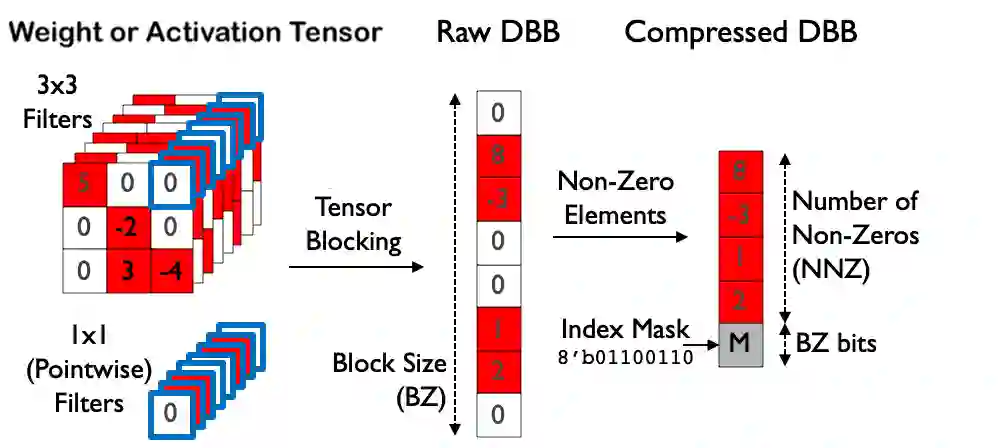
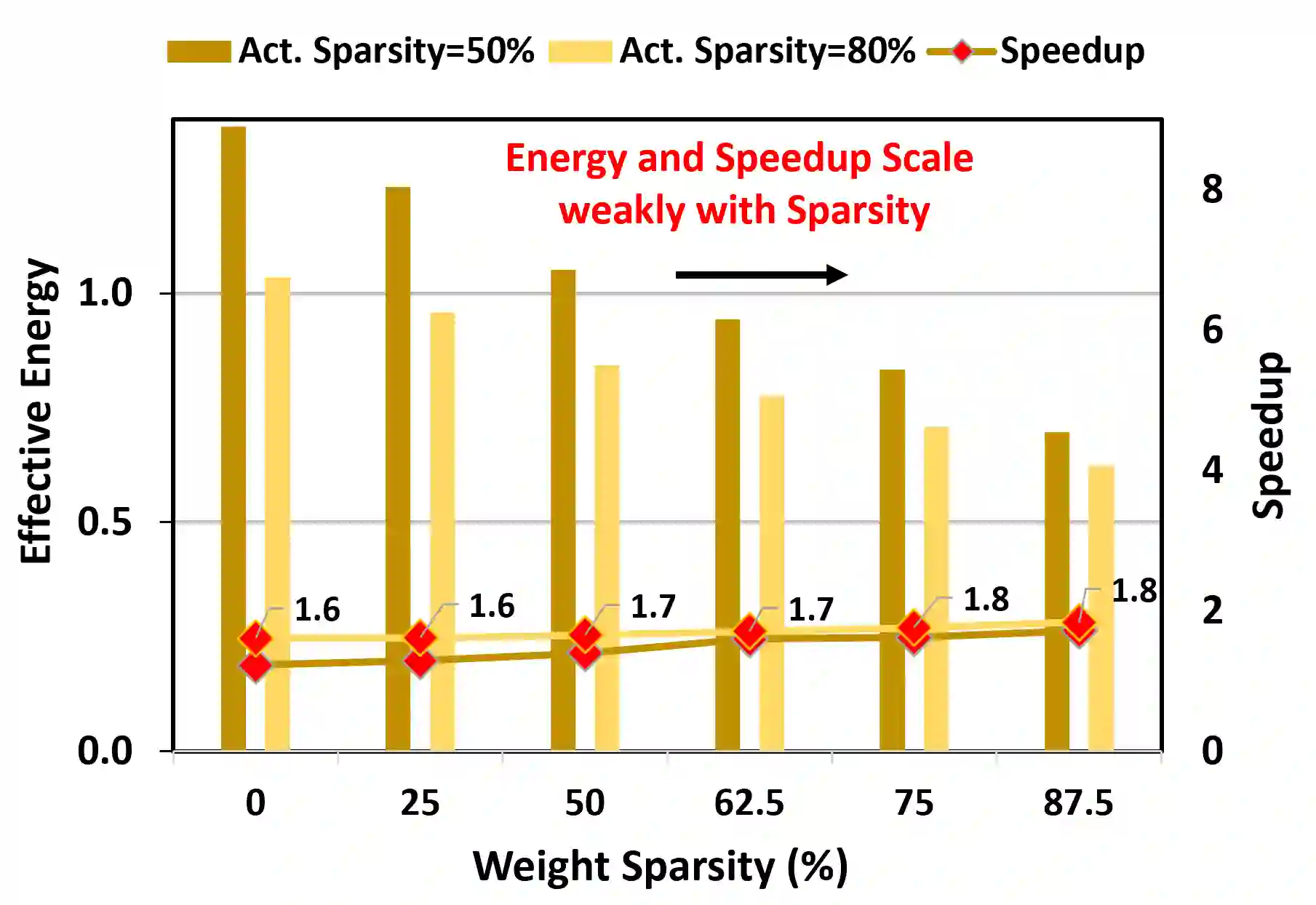
Exploiting sparsity is a key technique in accelerating quantized convolutional neural network (CNN) inference on mobile devices. Prior sparse CNN accelerators largely exploit un-structured sparsity and achieve significant speedups. Due to the unbounded, largely unpredictable sparsity patterns, however, exploiting unstructured sparsity requires complicated hardware design with significant energy and area overhead, which is particularly detrimental to mobile/IoT inference scenarios where energy and area efficiency are crucial. We propose to exploit structured sparsity, more specifically, Density Bound Block (DBB) sparsity for both weights and activations. DBB block tensors bound the maximum number of non-zeros per block. DBB thus exposes statically predictable sparsity patterns that enable lean sparsity-exploiting hardware. We propose new hardware primitives to implement DBB sparsity for (static) weights and (dynamic) activations, respectively, with very low overheads. Building on top of the primitives, we describe S2TA, a systolic array-based CNN accelerator that exploits joint weight and activation DBB sparsity and new dimensions of data reuse unavailable on the traditional systolic array. S2TA in 16nm achieves more than 2x speedup and energy reduction compared to a strong baseline of a systolic array with zero-value clock gating, over five popular CNN benchmarks. Compared to two recent non-systolic sparse accelerators, Eyeriss v2 (65nm) and SparTen (45nm), S2TA in 65nm uses about 2.2x and 3.1x less energy per inference, respectively.
翻译:在移动设备上加速四分化神经神经网络(CNN)推导速度的关键技术之一,是爆炸性超强。在移动设备上,先前稀有的CNN加速器主要利用非结构的宽度,并实现显著的加速。然而,由于无限制的、基本上无法预测的聚度模式,利用无结构的聚度需要复杂的硬件设计,其能量和面积管理量巨大,尤其不利于移动/IOT推论情景,其中能量和面积效率至关重要。我们提议利用结构化的松散性,更具体地说,密度Bound Block(DBB)的炎度,用于重量和激活。DBBlC块的振动器将非零星的最大数量捆绑起来。因此,DBB暴露了静态的可预测性散度模式,使精度开发硬件变得精干。我们提议新的硬件原始剂分别用于(静态)重量和(动态)电压的DBBBT, 以及非常低的电流压。在原始材料上,我们描述为强的S2TA, 相对的S2TA值的S-S-Sylicallical-Slistral2级平级平面数据中,比S-Slieval-S-Sliver的Sliver2级的Sliftal-Sliftaldaldaldaldaltialdaltialdaldaldaldaltor 的Stor 和16个Slidaltoraltator 的Slivatormatialtialtialtialdaldaltor 。