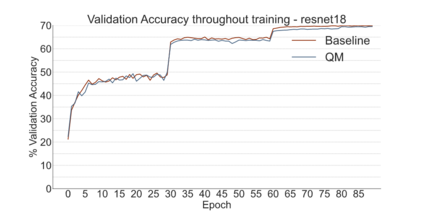
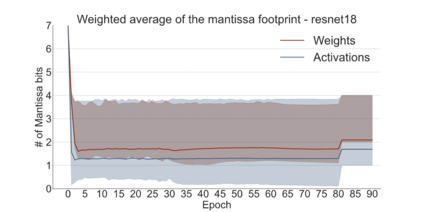
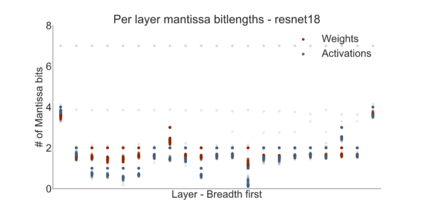
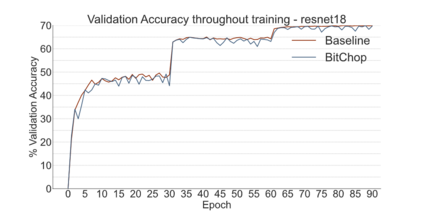
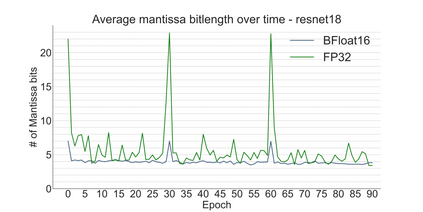
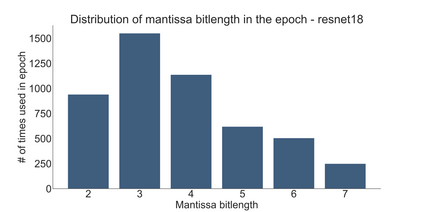
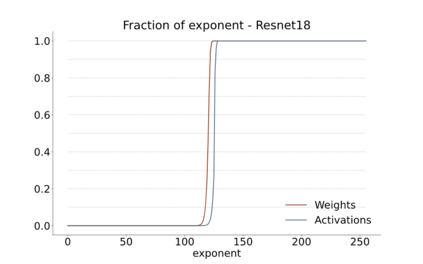
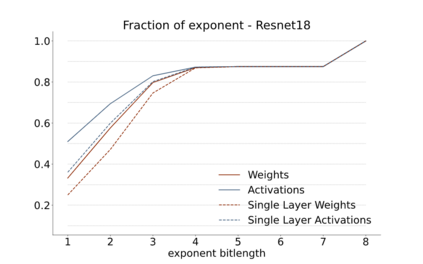
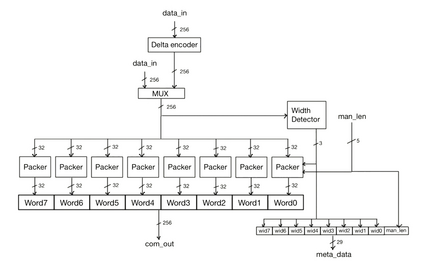
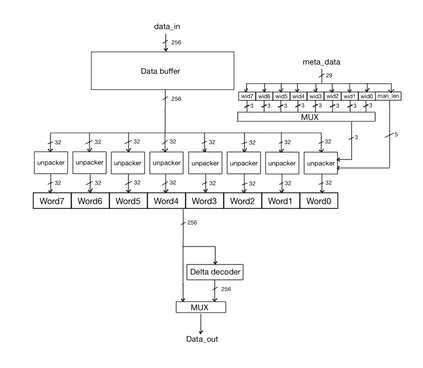
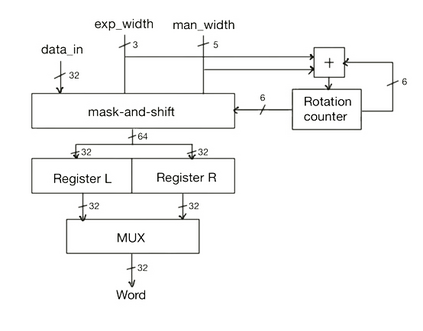
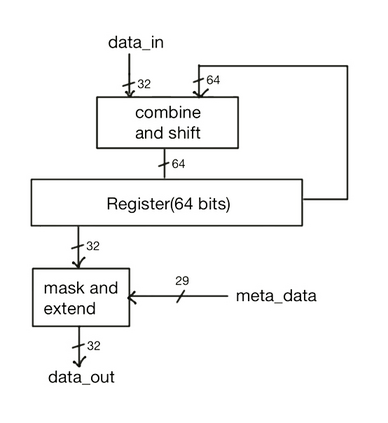
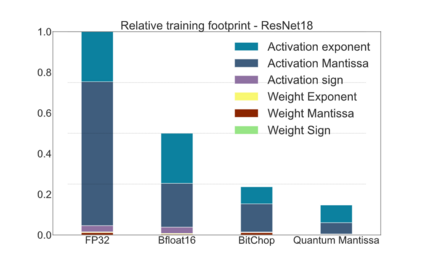
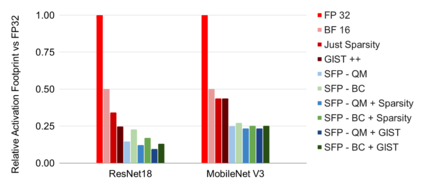
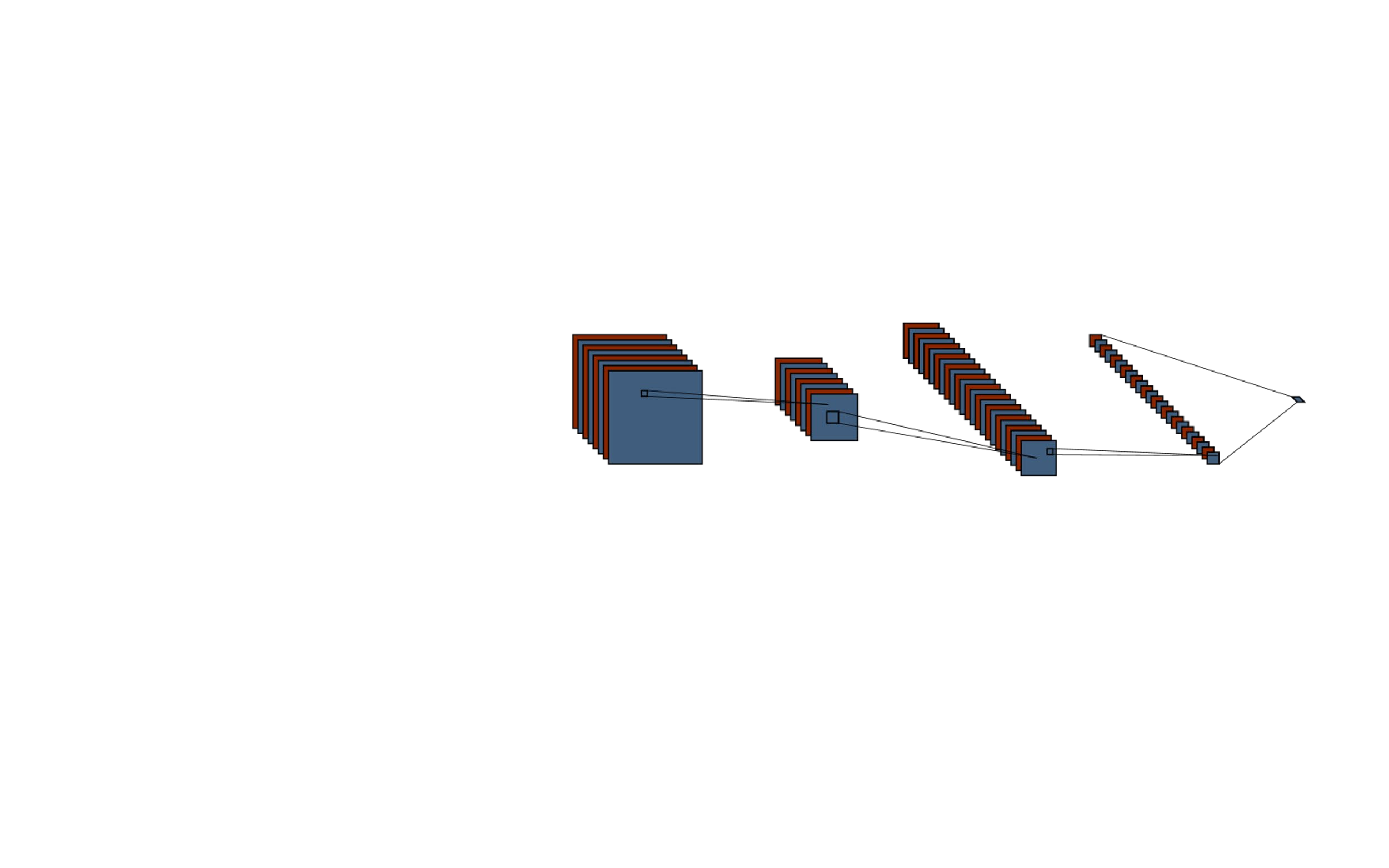
We introduce a software-hardware co-design approach to reduce memory traffic and footprint during training with BFloat16 or FP32 boosting energy efficiency and execution time performance. We introduce methods to dynamically adjust the size and format of the floating-point containers used to store activations and weights during training. The different value distributions lead us to different approaches for exponents and mantissas. Gecko exploits the favourable exponent distribution with a loss-less delta encoding approach to reduce the total exponent footprint by up to $58\%$ in comparison to a 32 bit floating point baseline. To content with the noisy mantissa distributions, we present two lossy methods to eliminate as many as possible least significant bits while not affecting accuracy. Quantum Mantissa, is a machine learning-first mantissa compression method that taps on training's gradient descent algorithm to also learn minimal mantissa bitlengths on a per-layer granularity, and obtain up to $92\%$ reduction in total mantissa footprint. Alternatively, BitChop observes changes in the loss function during training to adjust mantissa bit-length network-wide yielding a reduction of $81\%$ in footprint. Schr\"{o}dinger's FP implements hardware encoders/decoders that guided by Gecko/Quantum Mantissa or Gecko/BitChop transparently encode/decode values when transferring to/from off-chip memory boosting energy efficiency and reducing execution time.
翻译:我们采用软件硬件共同设计方法,在培训期间减少记忆流量和足迹,使用BFloat16或FP32提高能源效率和执行时间性能。我们采用各种方法,动态地调整用于储存激活和重量的培训用浮点集装箱的大小和格式。不同的价值分配方法使我们对Expententers和mantiissas采用不同的方法。Gecko利用一种无损失的三角编码法,以有利的快递分发方式,将总排泄量减少高达58美元,而低于32位浮动点基线。对于噪音曼蒂萨分布的内容,我们提出两种损失方法,以便在不影响准确性的情况下尽可能多地消除最小的点位数。Squmm Mantissa是一种机器学习-第一种曼蒂萨压缩方法,利用培训的梯底缩影算法,以学习一次级颗粒性颗粒的最小的曼蒂萨比,并在总曼蒂萨基底足迹上减少92美元。另外,BitChop 观察在培训期间,通过Orental-ral-decial development ral development ral ral-deal oria1 oria ormacial demode ormax ormax ormax le ormax ormax lex lex lex ormax lex lex lex lex lex ortial le lex lex lex lex 。