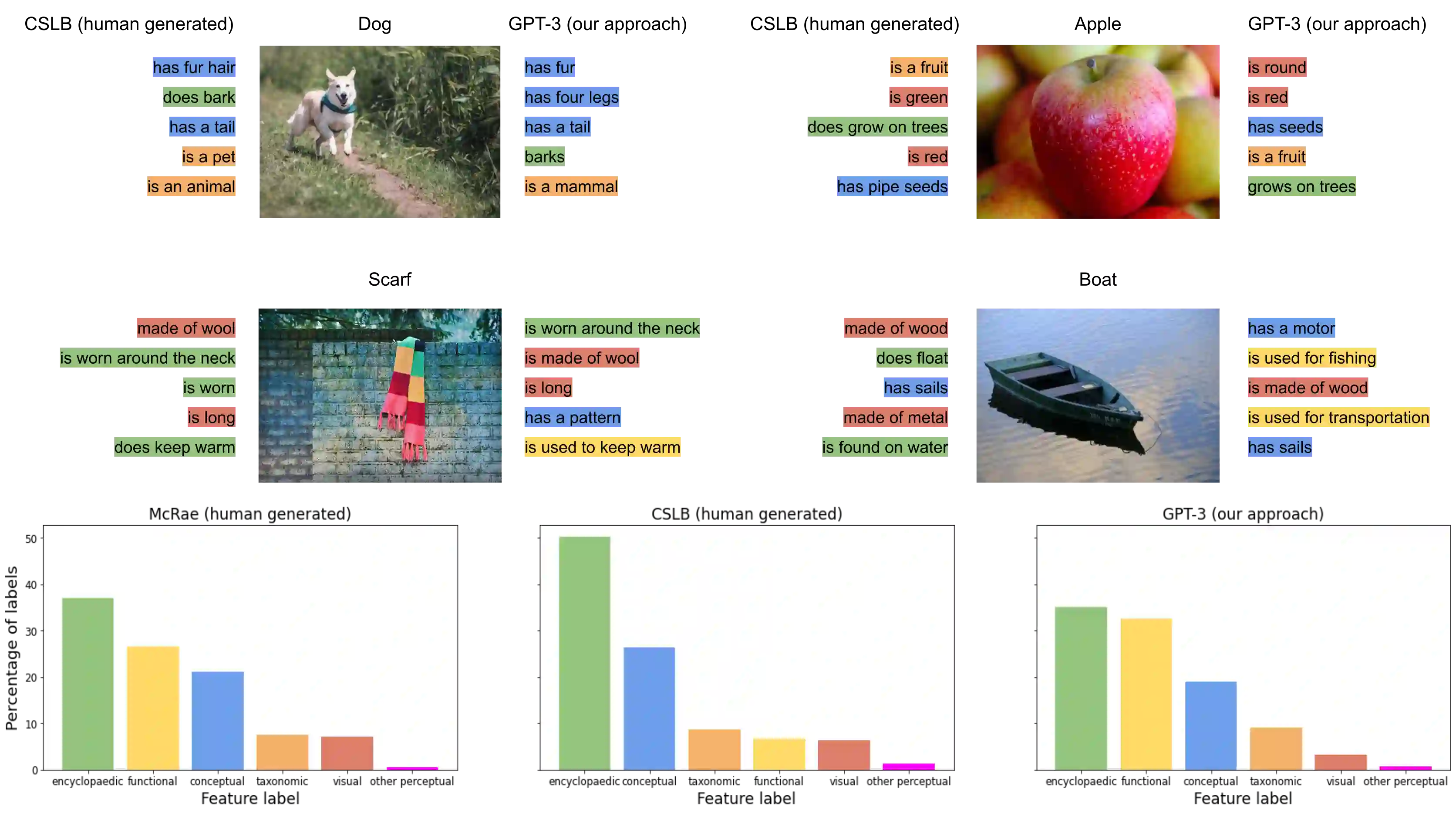
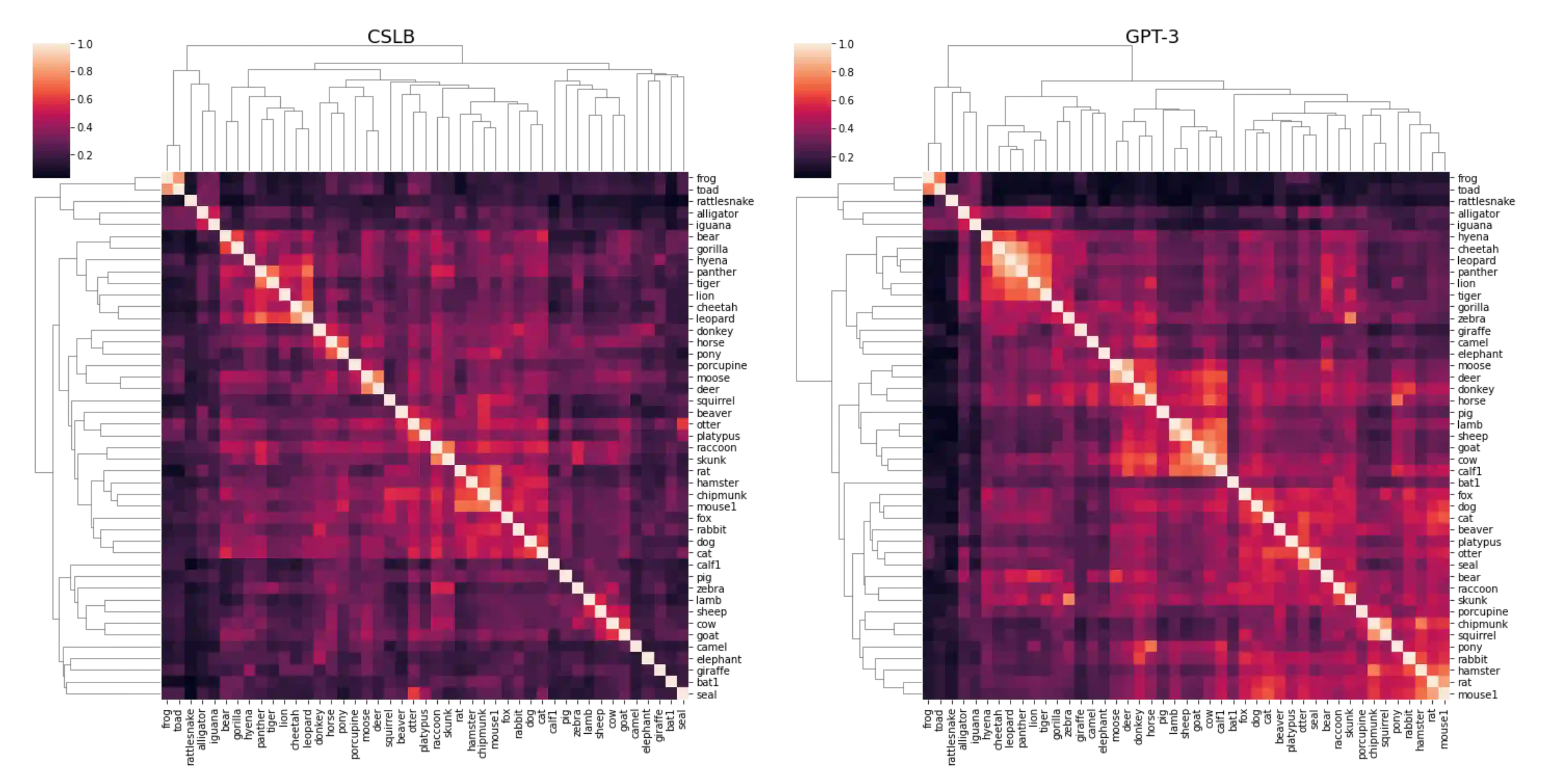
Semantic features have been playing a central role in investigating the nature of our conceptual representations. Yet the enormous time and effort required to empirically sample and norm features from human raters has restricted their use to a limited set of manually curated concepts. Given recent promising developments with transformer-based language models, here we asked whether it was possible to use such models to automatically generate meaningful lists of properties for arbitrary object concepts and whether these models would produce features similar to those found in humans. To this end, we probed a GPT-3 model to generate semantic features for 1,854 objects and compared automatically-generated features to existing human feature norms. GPT-3 generated many more features than humans, yet showed a similar distribution in the types of generated features. Generated feature norms rivaled human norms in predicting similarity, relatedness, and category membership, while variance partitioning demonstrated that these predictions were driven by similar variance in humans and GPT-3. Together, these results highlight the potential of large language models to capture important facets of human knowledge and yield a new approach for automatically generating interpretable feature sets, thus drastically expanding the potential use of semantic features in psychological and linguistic studies.
翻译:语义特征在调查我们概念表述的性质方面一直发挥着核心作用。然而,人类标本器的经验抽样和规范特征所需要的大量时间和努力限制了其使用,将其限制在有限的一组人工整理概念上。鉴于以变压器为基础的语言模型最近出现的有希望的发展动态,我们在这里询问是否有可能使用这些模型自动生成任意物体概念的有意义的属性清单,以及这些模型是否会产生与人类所发现的特征相类似的特征。为此,我们探索了一种GPT-3模型,为1,854个物体生成语义特征,并将自动生成的特征与现有人类特征规范进行比较。GPT-3生成了比人类更多的特征,但在生成的特征类型中却显示出类似的分布分布。生成的特征规范在预测相似性、关联性和类别成员构成方面与人类规范相匹配,而差异分布表明这些预测是由人类和GPT-3的类似差异驱动的。这些结果突出表明,大型语言模型有可能捕捉人类知识的重要方面,并产生可自动生成的特征数据集的新方法,从而极大地扩展了在心理和语言研究中使用语义特征方面的潜力。