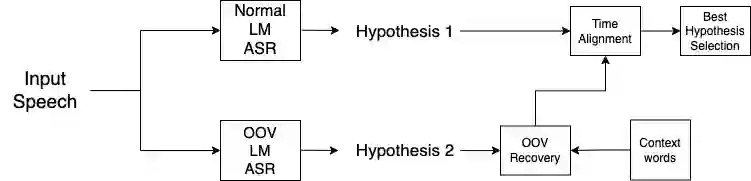
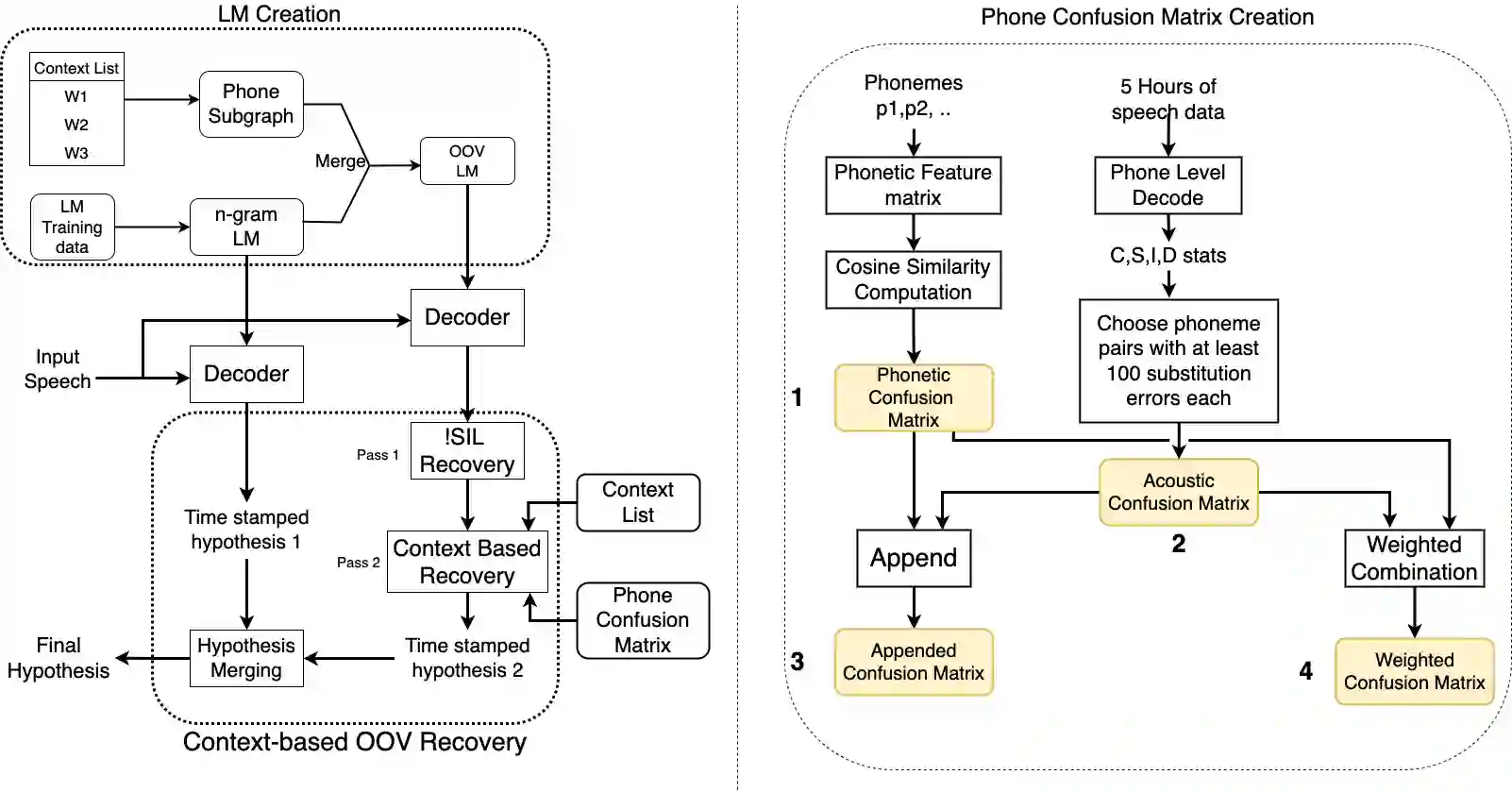
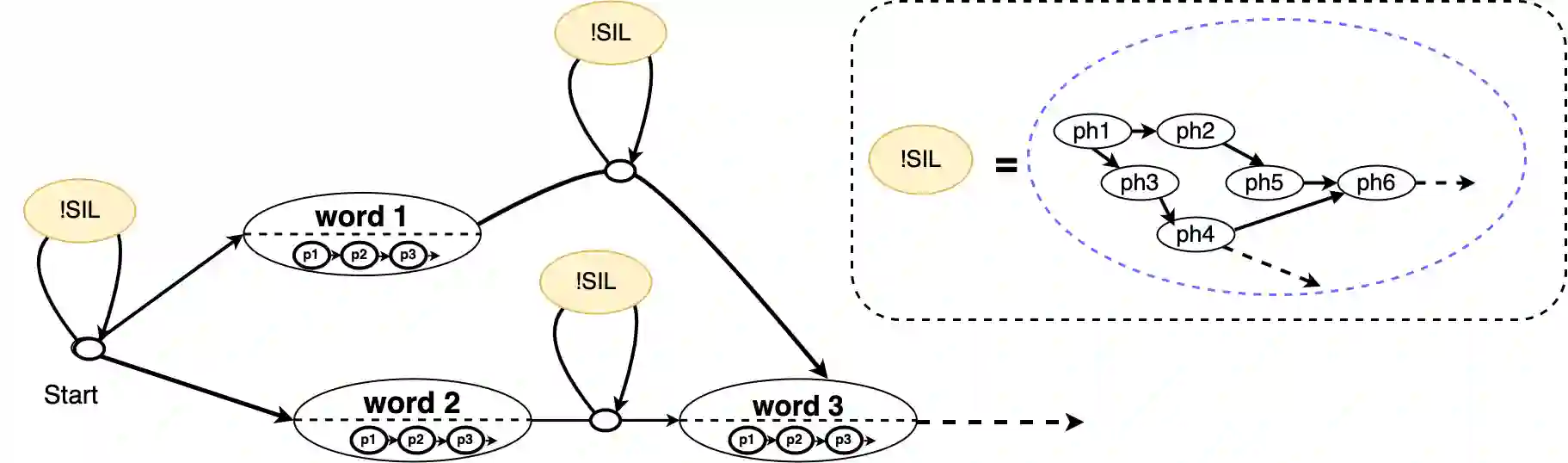
Detecting and recovering out-of-vocabulary (OOV) words is always challenging for Automatic Speech Recognition (ASR) systems. Many existing methods focus on modeling OOV words by modifying acoustic and language models and integrating context words cleverly into models. To train such complex models, we need a large amount of data with context words, additional training time, and increased model size. However, after getting the ASR transcription to recover context-based OOV words, the post-processing method has not been explored much. In this work, we propose a post-processing technique to improve the performance of context-based OOV recovery. We created an acoustically boosted language model with a sub-graph made at phone level with an OOV words list. We proposed two methods to determine a suitable cost function to retrieve the OOV words based on the context. The cost function is defined based on phonetic and acoustic knowledge for matching and recovering the correct context words in the decode. The effectiveness of the proposed cost function is evaluated at both word-level and sentence-level. The evaluation results show that this approach can recover an average of 50% context-based OOV words across multiple categories.
翻译:对自动语音识别(ASR)系统来说,检测和回收词汇外的词汇总是有挑战性。许多现有方法侧重于对语音和语言模型进行模型化的OOV词汇进行模型化修改,并将上下文文字纳入模型中。为了培训这些复杂的模型,我们需要大量数据,包括上下文文字、额外的培训时间和更大的模型规模。然而,在获得ASR转录以恢复基于背景的OOOV文字后,没有多少探索后处理方法。在这项工作中,我们提议了一种后处理技术,以改进基于背景的OOOOV恢复的性能。我们创建了一种以声学增强的语言模型,在电话级别上用OOOV文字列表制作了一个子图表。我们提出了两种方法,以确定根据上下文检索OOV文字的适当成本功能。成本功能是根据语音和声学知识来界定的,用于匹配和恢复在解码中正确背景文字中的正确文字。拟议成本功能的有效性在文字和句级上都得到评估。评价结果表明,这一方法可以恢复多个类别中基于上50%的OOV文字的平均值。