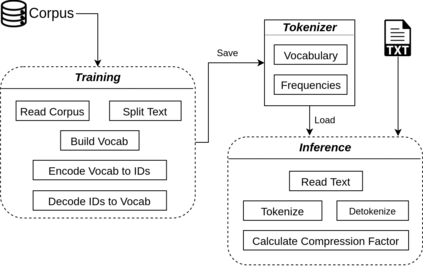
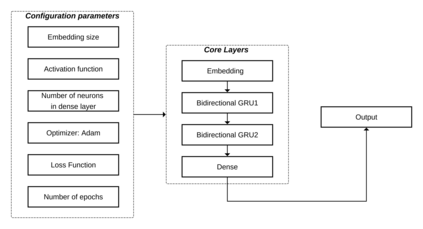
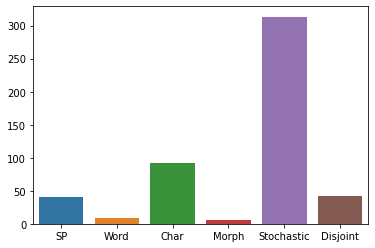
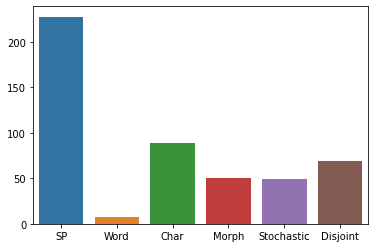
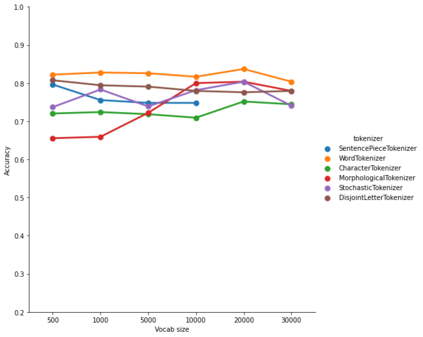
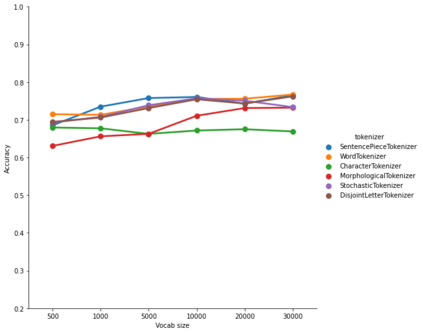
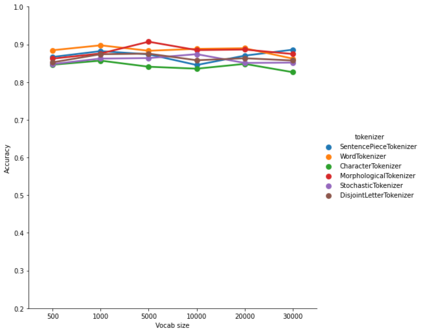
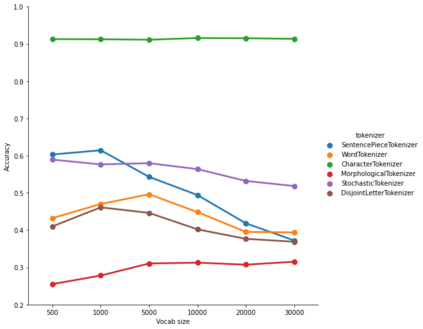
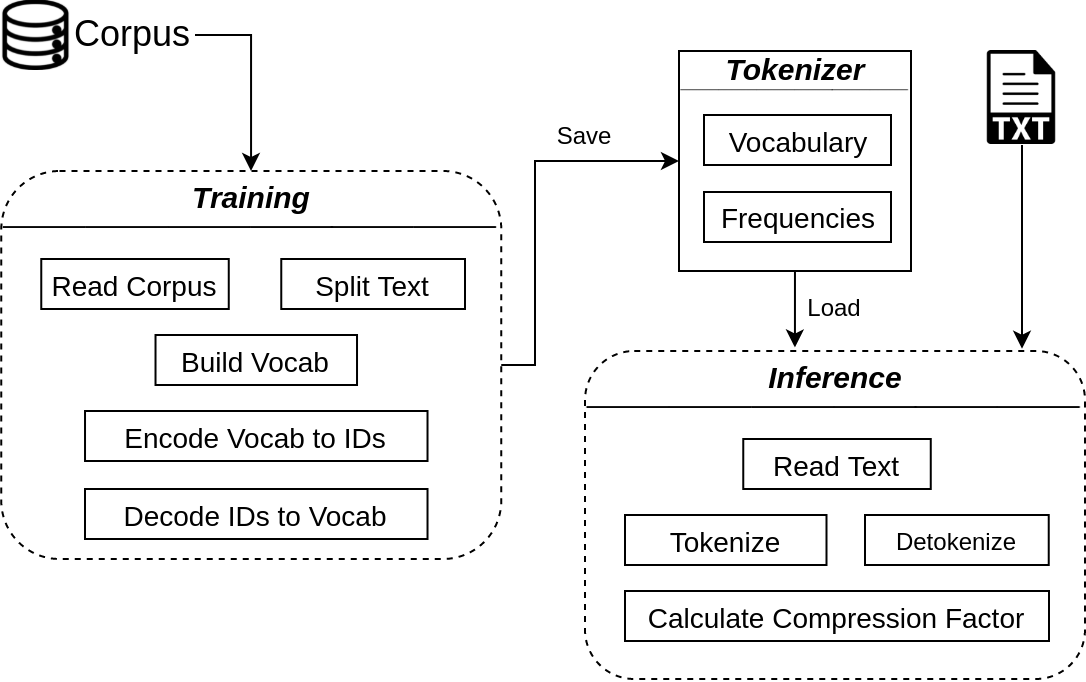
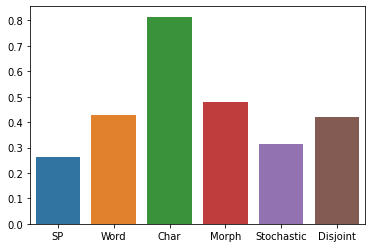The first step in any NLP pipeline is learning word vector representations. However, given a large text corpus, representing all the words is not efficient. In the literature, many tokenization algorithms have emerged to tackle this problem by creating subwords which in turn limits the vocabulary size in any text corpus. However such algorithms are mostly language-agnostic and lack a proper way of capturing meaningful tokens. Not to mention the difficulty of evaluating such techniques in practice. In this paper, we introduce three new tokenization algorithms for Arabic and compare them to three other baselines using unsupervised evaluations. In addition to that, we compare all the six algorithms by evaluating them on three tasks which are sentiment analysis, news classification and poetry classification. Our experiments show that the performance of such tokenization algorithms depends on the size of the dataset, type of the task, and the amount of morphology that exists in the dataset.
翻译:任何NLP管道的第一个步骤是学习文字矢量表示。 但是,鉴于代表所有字词的庞大文本体并不有效。 在文献中,许多象征性算法已经出现,通过创建子字来解决这个问题,这些子字反过来限制任何文字体的词汇大小。然而,这种算法大多是语言不可知性的,缺乏捕捉有意义符号的适当方式。更不用说在实际中评估这些技术的困难。在本文中,我们为阿拉伯语引入了三种新的象征性算法,并用未经监督的评价将其与其他三个基线进行比较。此外,我们通过对这六个算法进行对比,在三个任务上进行了感性分析、新闻分类和诗歌分类。我们的实验表明,这种象征性算法的性能取决于数据集的大小、任务类型以及数据集中存在的形态数量。