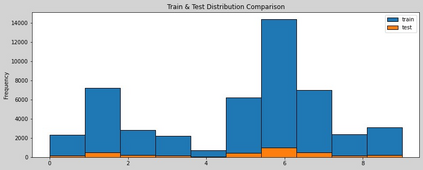
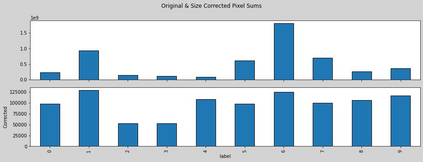
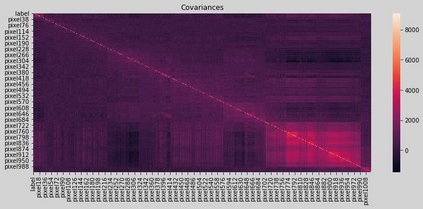
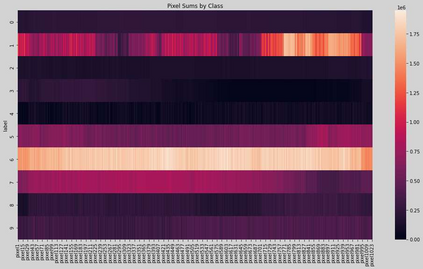
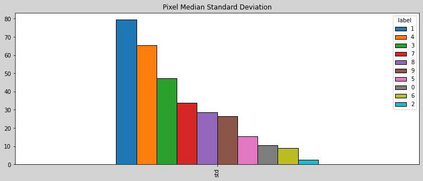
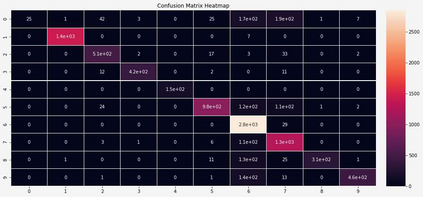
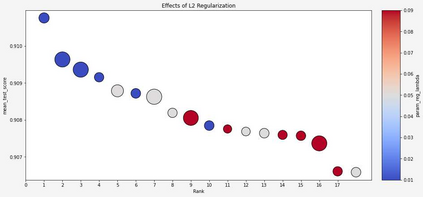
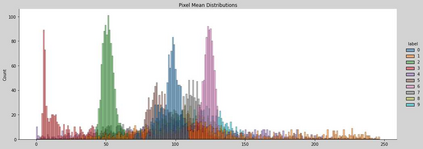
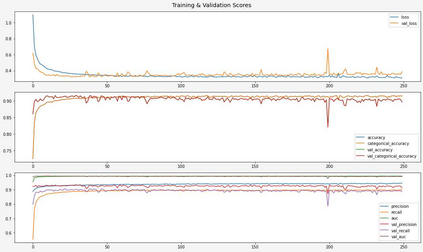
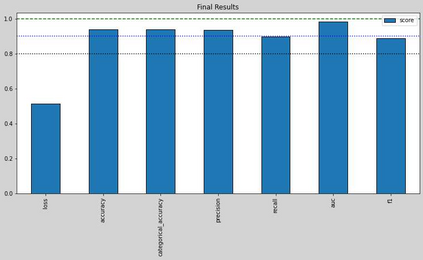
The Virus-MNIST data set is a collection of thumbnail images that is similar in style to the ubiquitous MNIST hand-written digits. These, however, are cast by reshaping possible malware code into an image array. Naturally, it is poised to take on a role in benchmarking progress of virus classifier model training. Ten types are present: nine classified as malware and one benign. Cursory examination reveals unequal class populations and other key aspects that must be considered when selecting classification and pre-processing methods. Exploratory analyses show possible identifiable characteristics from aggregate metrics (e.g., the pixel median values), and ways to reduce the number of features by identifying strong correlations. A model comparison shows that Light Gradient Boosting Machine, Gradient Boosting Classifier, and Random Forest algorithms produced the highest accuracy scores, thus showing promise for deeper scrutiny.
翻译:病毒-MNIST数据集是一个缩略图集,其风格类似于无处不在的MNIST手写数字。 但是,这些图集是通过将可能的恶意软件代码转换成图像阵列来绘制的。 当然,它准备在为病毒分类模型培训的进展制定基准方面发挥作用。 存在10种类型:9种被归类为恶意软件和1种良性。 光学检查显示在选择分类和预处理方法时必须考虑的阶级人口和其他关键方面不平等。 探索性分析显示综合指标(例如像素中值)中可能具有的可识别特征,并通过确定强有力的关联性来减少特征数量。 模型比较显示,轻重力推动机、梯级推动机和随机森林算法产生了最高精度分数,从而显示了更深入审查的希望。