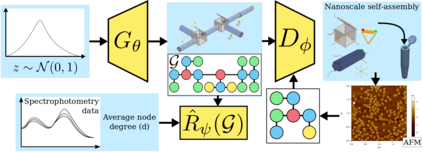
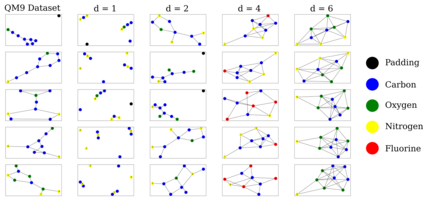
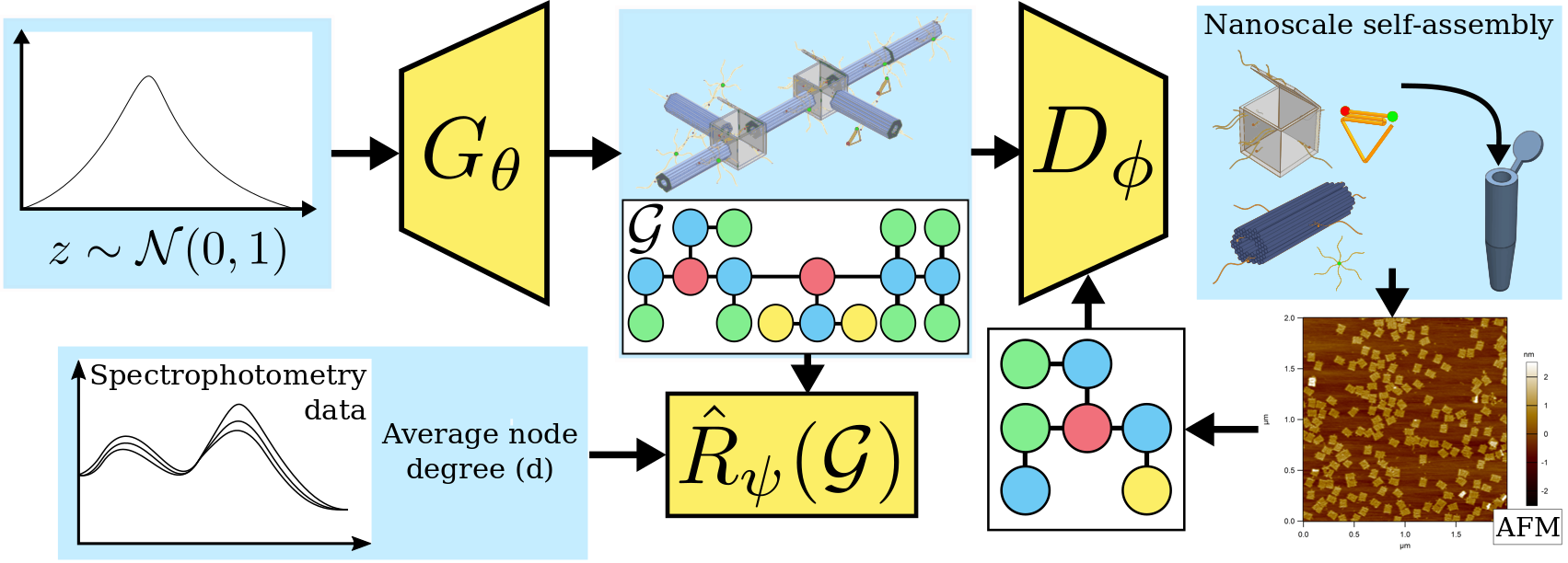
The field of DNA nanotechnology has made it possible to assemble, with high yields, different structures that have actionable properties. For example, researchers have created components that can be actuated. An exciting next step is to combine these components into multifunctional nanorobots that could, potentially, perform complex tasks like swimming to a target location in the human body, detect an adverse reaction and then release a drug load to stop it. However, as we start to assemble more complex nanorobots, the yield of the desired nanorobot begins to decrease as the number of possible component combinations increases. Therefore, the ultimate goal of this work is to develop a predictive model to maximize yield. However, training predictive models typically requires a large dataset. For the nanorobots we are interested in assembling, this will be difficult to collect. This is because high-fidelity data, which allows us to characterize the shape and size of individual structures, is very time-consuming to collect, whereas low-fidelity data is readily available but only captures bulk statistics for different processes. Therefore, this work combines low- and high-fidelity data to train a generative model using a two-step process. We first use a relatively small, high-fidelity dataset to train a generative model. At run time, the model takes low-fidelity data and uses it to approximate the high-fidelity content. We do this by biasing the model towards samples with specific properties as measured by low-fidelity data. In this work we bias our distribution towards a desired node degree of a graphical model that we take as a surrogate representation of the nanorobots that this work will ultimately focus on. We have not yet accumulated a high-fidelity dataset of nanorobots, so we leverage the MolGAN architecture [1] and the QM9 small molecule dataset [2-3] to demonstrate our approach.
翻译:DNA纳米技术领域使得有可能以高产量收集具有可操作性的不同结构。 例如, 研究人员已经创建了可以激活的元件。 令人振奋的下一步是将这些元件合并成多功能纳米机器人, 这些元件有可能执行复杂的任务, 比如游泳到人体中的目标位置, 检测出一种负面反应, 然后释放出一种药物负荷来阻止它。 但是, 当我们开始组装更复杂的纳米机器人时, 所期望的纳米机器人的产值开始下降, 随着可能的元件组合数量的增加。 因此, 这项工作的最终目标是开发一个预测性模型, 以最大限度地增产。 然而, 培训预测性模型通常需要一个大型的数据集。 对于我们有兴趣组装的纳米机器人来说, 这将很难收集。 这是因为高性数据模型, 使我们能够描述个体结构的形状和大小, 是非常费时的收集, 而低性能数据是很容易获得的, 低性能数据是用来捕捉到的, 低性能数据, 并且只能捕捉到我们不同的进程。 因此, 这项工作将低性和高性的数据 合并为低性和高性数据, 我们使用高性数据 运行数据 数据 使用高性模型, 我们使用高性数据 使用高性数据 运行 数据 数据 运行 数据 运行 数据 模型 运行 数据 数据 运行 数据 数据 模型 运行一个小的模型