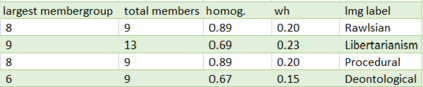
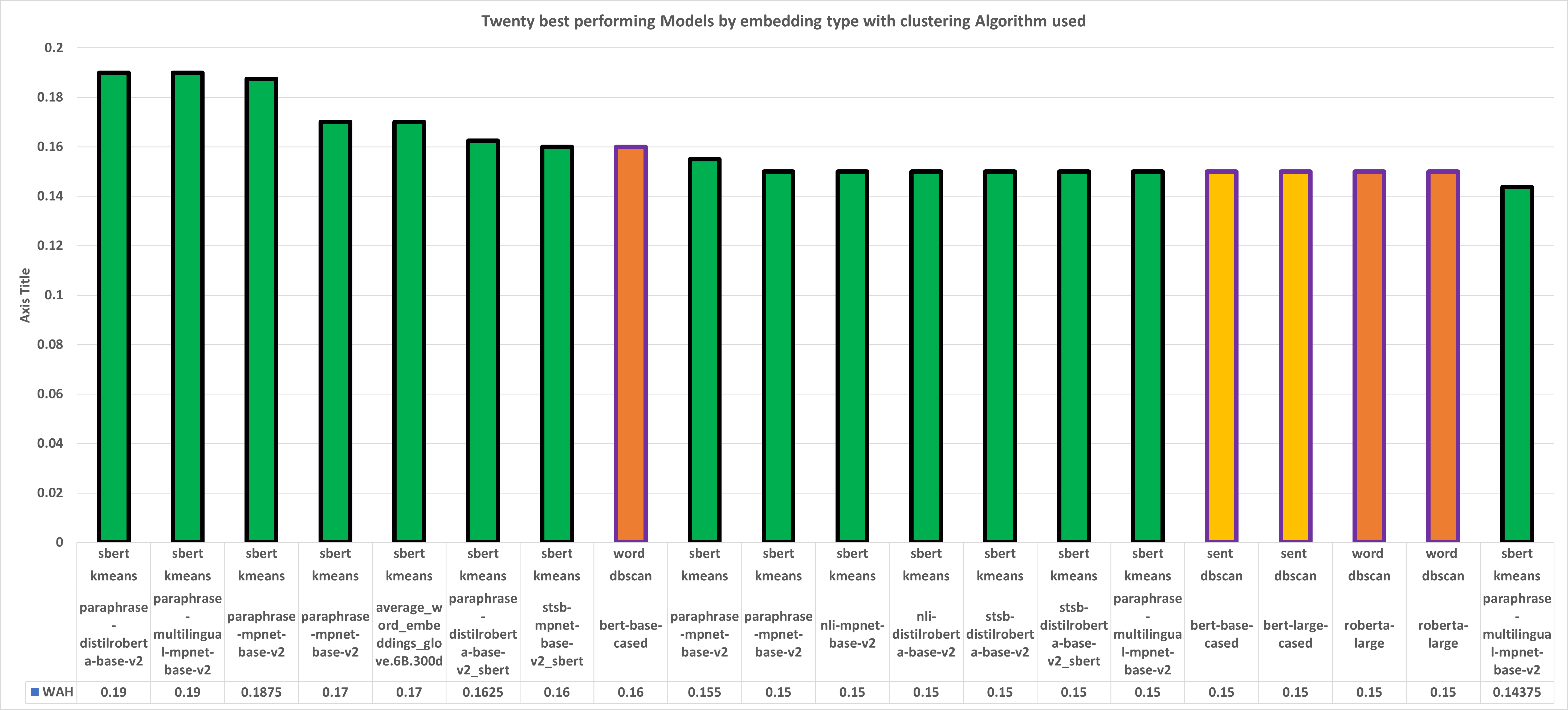
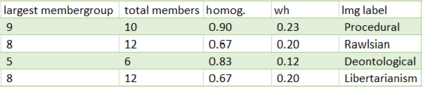In this article, we explore the potential of transformer-based language models (LMs) to correctly represent normative statements in the legal domain, taking tax law as our use case. In our experiment, we use a variety of LMs as bases for both word- and sentence-based clusterers that are then evaluated on a small, expert-compiled test-set, consisting of real-world samples from tax law research literature that can be clearly assigned to one of four normative theories. The results of the experiment show that clusterers based on sentence-BERT-embeddings deliver the most promising results. Based on this main experiment, we make first attempts at using the best performing models in a bootstrapping loop to build classifiers that map normative claims on one of these four normative theories.
翻译:在本篇文章中,我们探讨了以变压器为基础的语言模型(LMs)在正确代表法律领域的规范性声明方面的潜力,以税法作为我们使用的例子。在实验中,我们利用各种LMs作为基于字和基于判决的集群的基础,然后用一个由专家组成的小型测试集来评价,由来自税法研究文献的实世样本组成,可以明确分配给四种规范性理论之一。实验结果显示,基于判决-BERT编组的组合体提供了最有希望的结果。根据这一主要实验,我们首先尝试利用靴子圈中最优秀的模型来建立分类体,根据这四种规范性理论之一绘制规范性主张图。