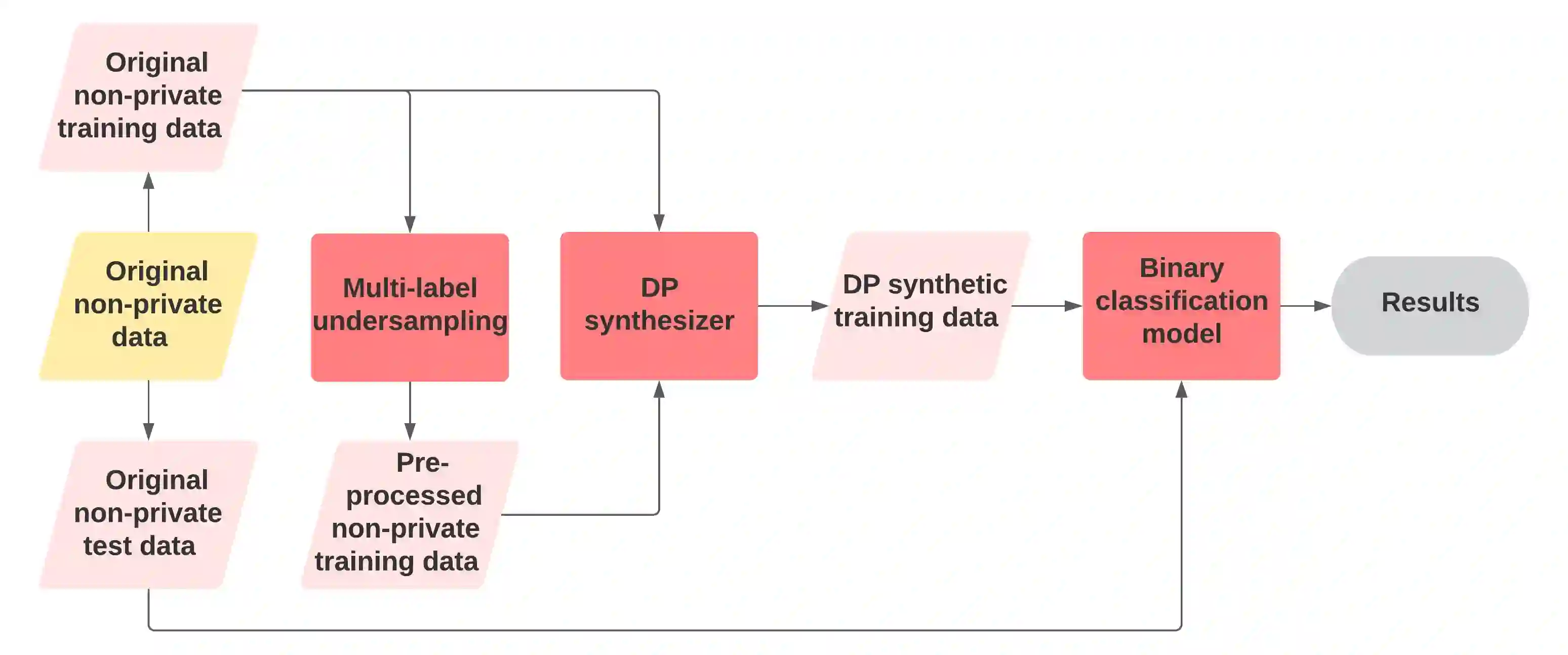
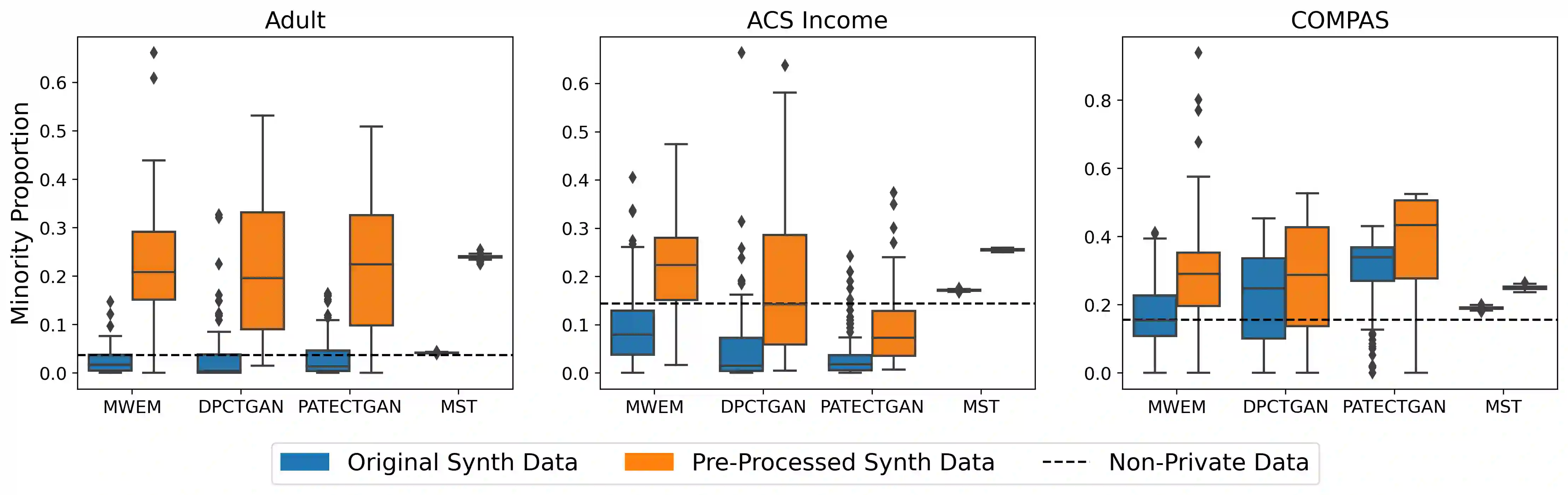
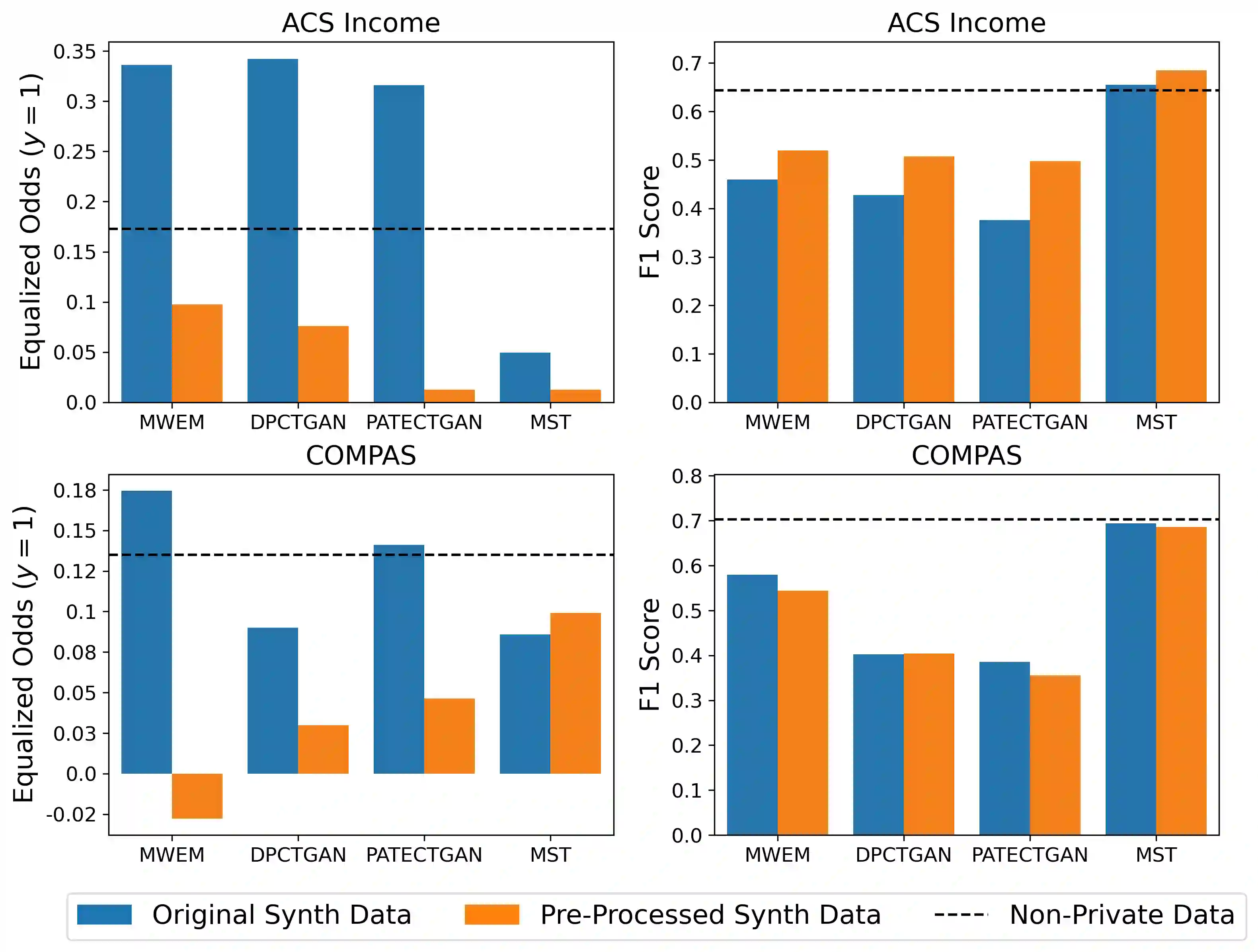
Differentially private (DP) synthetic data is a promising approach to maximizing the utility of data containing sensitive information. Due to the suppression of underrepresented classes that is often required to achieve privacy, however, it may be in conflict with fairness. We evaluate four DP synthesizers and present empirical results indicating that three of these models frequently degrade fairness outcomes on downstream binary classification tasks. We draw a connection between fairness and the proportion of minority groups present in the generated synthetic data, and find that training synthesizers on data that are pre-processed via a multi-label undersampling method can promote more fair outcomes without degrading accuracy.
翻译:区别对待的私人(DP)合成数据是最大限度地利用包含敏感信息的数据的一个很有希望的方法。但是,由于压制代表不足的类别,而这种类别往往是实现隐私所必须的,因此可能与公平相冲突。我们评估了四个DP合成器,并介绍了经验结果,表明其中三个模型经常降低下游二元分类任务的公平性结果。我们把所生成的合成数据中存在的少数群体的公平性和比例联系起来,并发现对合成器进行培训,使其了解通过多标签下标方法预先处理的数据,可以促进更公平的结果,而不会降低准确性。