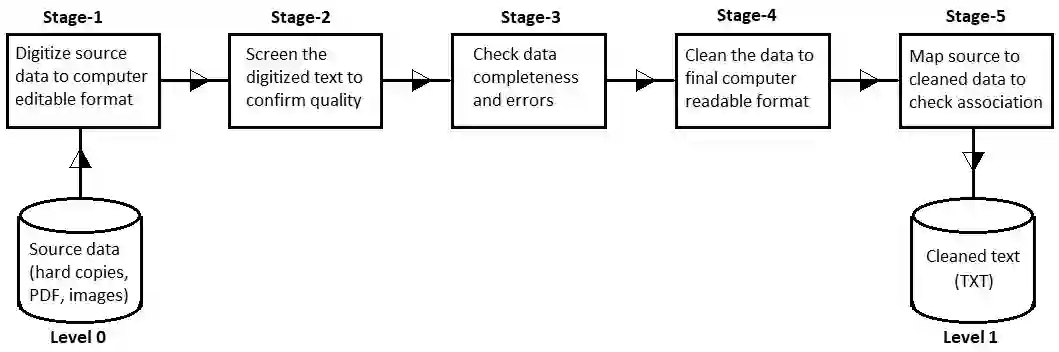
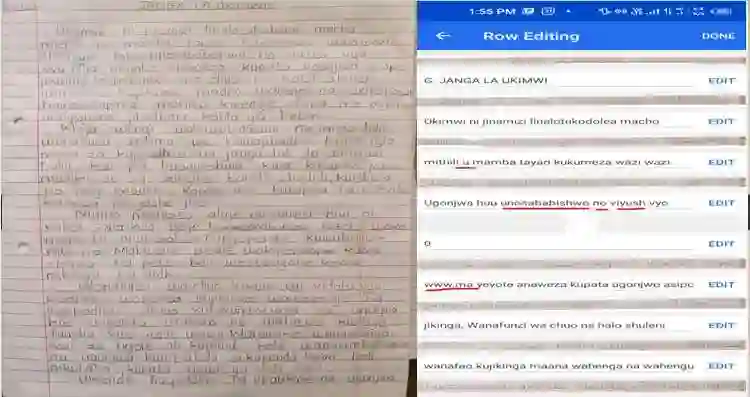
Indigenous African languages are categorized as under-served in Artificial Intelligence and suffer poor digital inclusivity and information access. The challenge has been how to use machine learning and deep learning models without the requisite data. Kencorpus is a Kenyan Language corpus that intends to bridge the gap on how to collect, and store text and speech data that is good enough to enable data-driven solutions in applications such as machine translation, question answering and transcription in multilingual communities. Kencorpus is a corpus (text and speech) for three languages predominantly spoken in Kenya: Swahili, Dholuo and Luhya (dialects Lumarachi, Lulogooli and Lubukusu). This corpus intends to fill the gap of developing a dataset that can be used for Natural Language Processing and Machine Learning tasks for low-resource languages. Each of these languages contributed text and speech data for the language corpus. Data collection was done by researchers from communities, schools and collaborating partners (media, publishers). Kencorpus has a collection of 5,594 items, being 4,442 texts (5.6million words) and 1,152 speech files (177hrs). Based on this data, other datasets were also developed e.g POS tagging sets for Dholuo and Luhya (50,000 and 93,000 words tagged respectively), Question-Answer pairs from Swahili texts (7,537 QA pairs) and Translation of texts into Swahili (12,400 sentences). The datasets are useful for machine learning tasks such as text processing, annotation and translation. The project also undertook proof of concept systems in speech to text and machine learning for QA task, with initial results confirming the usability of the Kencorpus to the machine learning community. Kencorpus is the first such corpus of its kind for these low resource languages and forms a basis of learning and sharing experiences for similar works.
翻译:Kencorpus是一个肯尼亚语言库,旨在弥补在如何收集、储存文本和语音数据方面存在的差距,这些数据足以使多语种社区在机器翻译、答题和笔录等应用中找到数据驱动的解决方案。Kencorpus是肯尼亚三种主要语言的文具(文字和语言):Swahili、Dholuo和Luhya(视频Lumarachi、Lulogooli和Lubukusu),挑战在于如何在没有必要数据的情况下使用机器学习模式和深层次学习模式。Kencorpus是一个肯尼亚语言库(文字和语言),主要使用三种语言:Swahili、Dholuo和Luhya(视频Lumarachi、Lulogooli和Lubukusu)。这个文库旨在填补开发数据集的空白,该数据集可用于自然资源语言处理和机器学习任务。 Kenhillial为Syal、Syloral、Syaliflex、Sylegle、Syle、Syalex、Sylex、Syalegle、Syle、Syale、Syal、Syle、Syle、Klade、Slade、Sil、Syal、Sil、Sla、Sla、Sil、Sil、Sild、Syal、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sla、Sil、S、S、S、S、Sil、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、K、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、S、