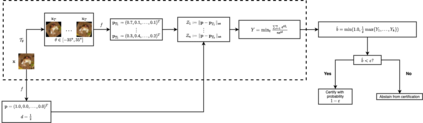
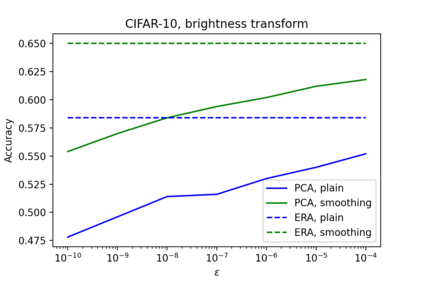
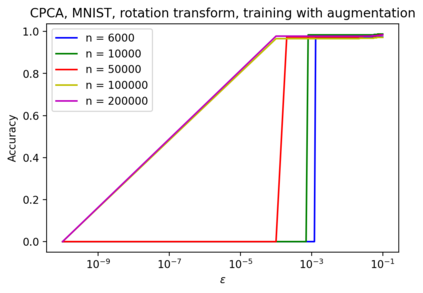
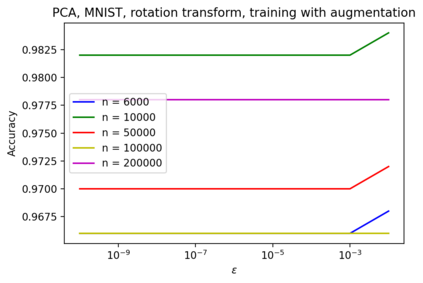
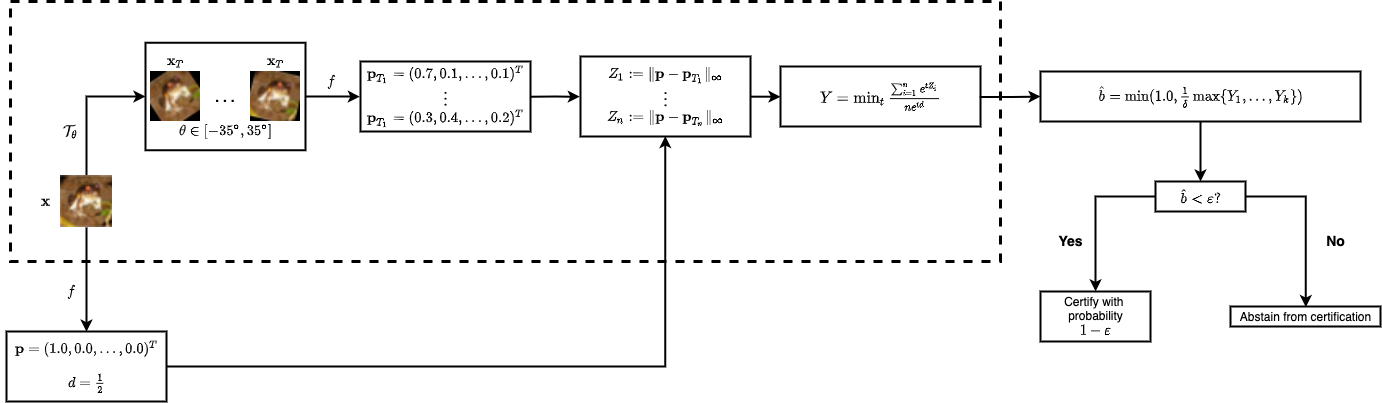
In safety-critical machine learning applications, it is crucial to defend models against adversarial attacks -- small modifications of the input that change the predictions. Besides rigorously studied $\ell_p$-bounded additive perturbations, recently proposed semantic perturbations (e.g. rotation, translation) raise a serious concern on deploying ML systems in real-world. Therefore, it is important to provide provable guarantees for deep learning models against semantically meaningful input transformations. In this paper, we propose a new universal probabilistic certification approach based on Chernoff-Cramer bounds that can be used in general attack settings. We estimate the probability of a model to fail if the attack is sampled from a certain distribution. Our theoretical findings are supported by experimental results on different datasets.
翻译:在安全关键机器学习应用中,必须保护各种模型,防止对抗性攻击 -- -- 对改变预测的输入进行小的修改。除了严格研究$@ell_p$绑定的添加扰动外,最近提出的语义扰动(例如轮用、翻译)引起人们严重关切在现实世界部署 ML 系统。因此,重要的是为深层次学习模型提供可证实的保障,防止具有义性意义的输入转换。在本文中,我们提出了一种新的基于Chernoff-Cramer 界限的普遍概率认证方法,可用于一般攻击环境。我们估计了如果从某种分布中抽样攻击模式失败的可能性。我们理论发现得到了不同数据集实验结果的支持。