
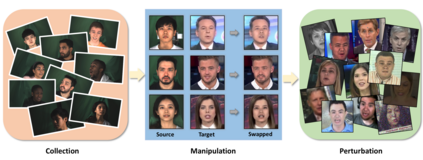
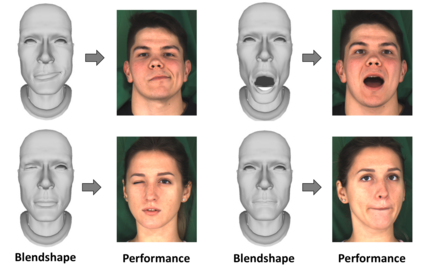
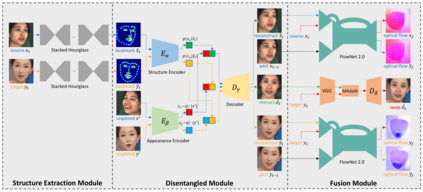
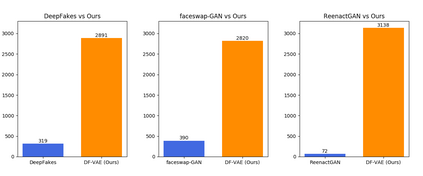
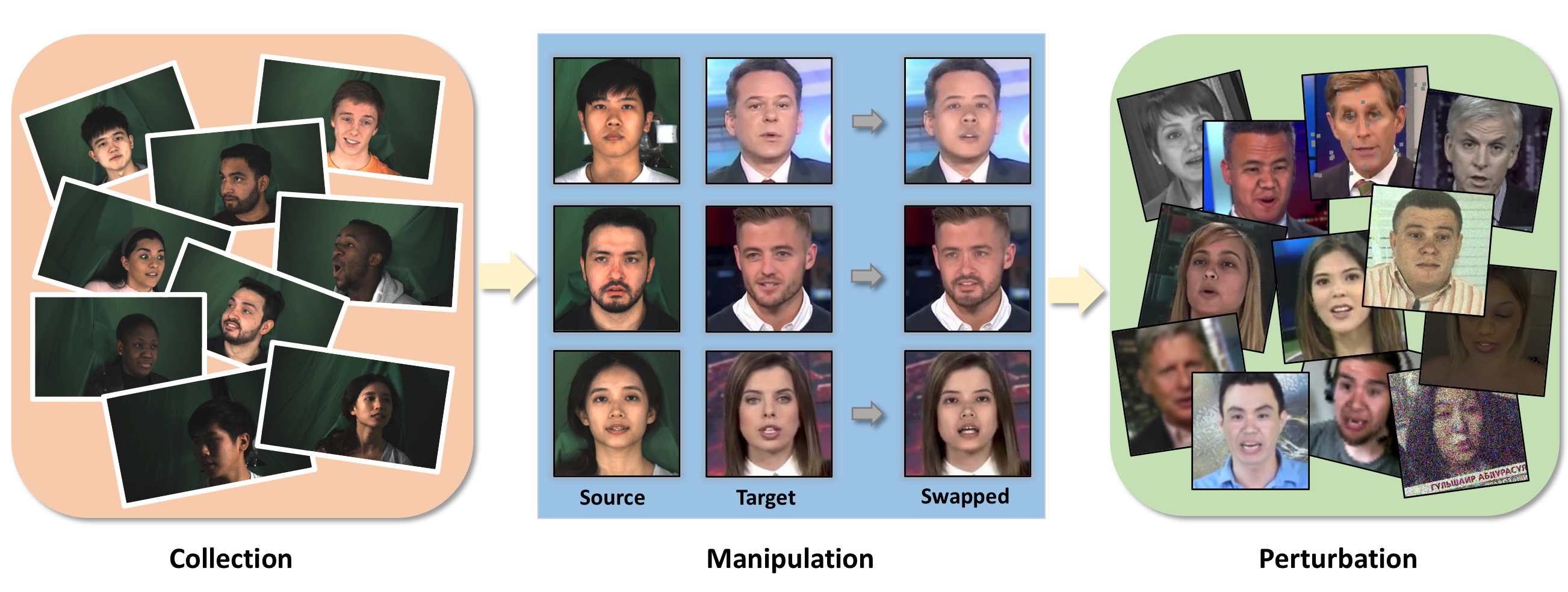
We present our on-going effort of constructing a large-scale benchmark for face forgery detection. The first version of this benchmark, DeeperForensics-1.0, represents the largest face forgery detection dataset by far, with 60,000 videos constituted by a total of 17.6 million frames, 10 times larger than existing datasets of the same kind. Extensive real-world perturbations are applied to obtain a more challenging benchmark of larger scale and higher diversity. All source videos in DeeperForensics-1.0 are carefully collected, and fake videos are generated by a newly proposed end-to-end face swapping framework. The quality of generated videos outperforms those in existing datasets, validated by user studies. The benchmark features a hidden test set, which contains manipulated videos achieving high deceptive scores in human evaluations. We further contribute a comprehensive study that evaluates five representative detection baselines and make a thorough analysis of different settings.
翻译:我们介绍了我们为建立大规模假冒检测基准而正在进行的努力。这一基准的第一个版本,DeeperForensics-1.0,是迄今为止最大的面假检测数据集,共有60,000个视频,由总共1,760万个框架组成,比同类现有数据集大10倍。为了获得更大规模、更多样化的更具挑战性的基准,我们应用了广泛的真实世界扰动。DeeperForensics-1.0中的所有源视频都是仔细收集的,而假视频是由新提议的端对端面转换框架生成的。生成的视频的质量超越了现有数据集中的数据,并由用户研究验证。该基准有一个隐藏的测试集,其中包含了在人类评估中达到高欺骗性高分数的被操纵视频。我们进一步协助一项全面研究,对5个具有代表性的检测基线进行评估,并对不同的环境进行透彻分析。















































































相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


