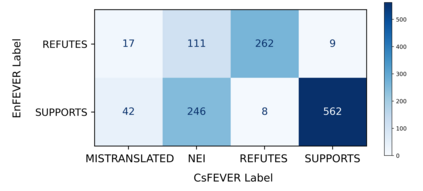
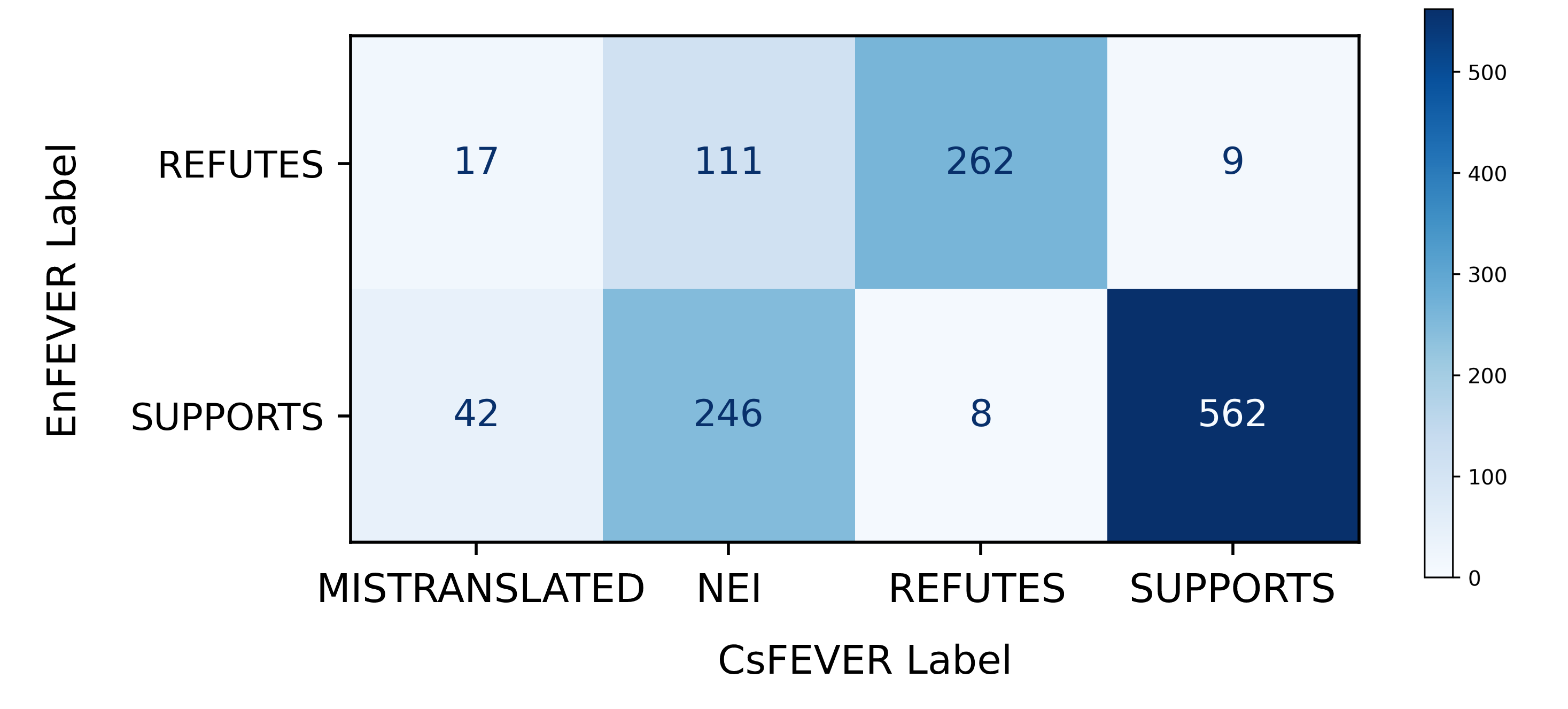
In this paper we present two Czech datasets aimed for training automated fact-checking machine learning models. Specifically we deal with the task of assessment of a textual claim veracity w.r.t. to a (presumably) verified corpus. The output of the system is the claim classification SUPPORTS or REFUTES complemented with evidence documents or NEI (Not Enough Info) alone. In the first place we publish CsFEVER of approximately 112k claims which is an automatically generated Czech version of the well-known Wikipedia-based FEVER dataset. We took a hybrid approach of machine translation and language alignment, where the same method (and tools we provide) can be easily applied to other languages. The second dataset CTKFacts of 3,097 claims is built on the corpus of approximately two million Czech News Agency news reports. We present an extended methodology based on the FEVER approach. Most notably, we describe a method to automatically generate wider claim contexts (dictionaries) for non-hyperlinked corpora. The datasets are analyzed for spurious cues, which are annotation patterns leading to model overfitting. CTKFacts is further examined for inter-annotator agreement, and a typology of common annotator errors is extracted. Finally, we provide baseline models for all stages of the fact-checking pipeline.
翻译:在本文中,我们提出两个捷克数据集,目的是培训自动化事实检查机学习模型。具体地说,我们处理的是评估文本要求真实性(和我们提供的工具)到(可以想象的)核实的文体的任务。系统的输出是索赔分类支持或REFUTES, 并辅以证据文件或NEI( 信息不足) 。首先,我们出版了大约112k索赔要求的CSFEWER, 这是捷克自动生成的、以维基百科为基础的FEW数据集的捷克版本。我们采用了机器翻译和语言对齐的混合方法,其中同一方法(和我们提供的工具)可以很容易地应用于其他语言。第二个3 097索赔要求的CTKFact, 建在大约200万捷克新闻机构新闻报道的文体中。我们根据FEWE(信息不足)的方法介绍了一个扩展的方法。最突出的是,我们描述了一种自动生成非功能连接的CFEVER数据集(词典)的更大范围(词典)的方法。我们分析了数据集,用来分析错误信号,这是导致过度校正的模型的CTFactsculttal a claimatealtraction a caltraction a casetraction for all folformaster