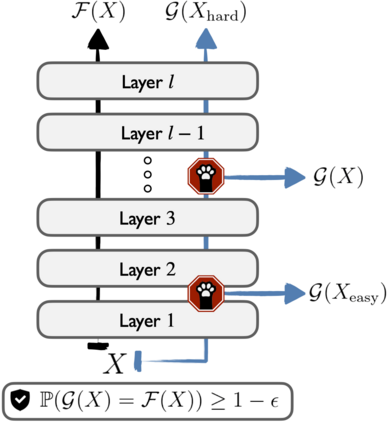
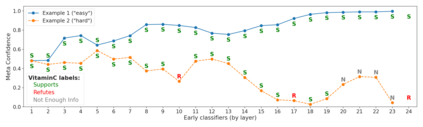
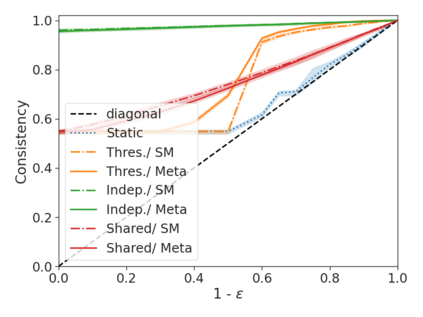
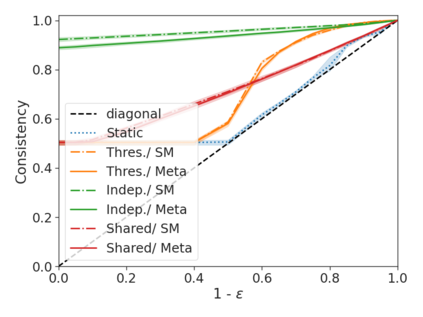
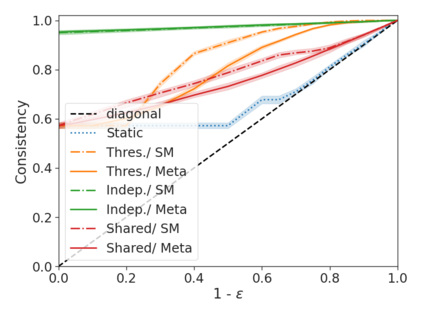
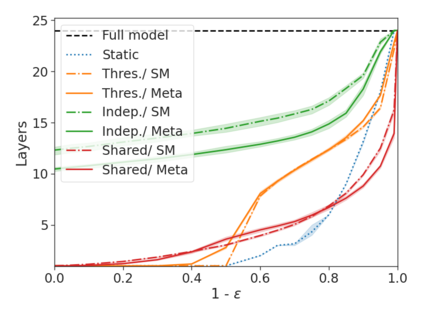
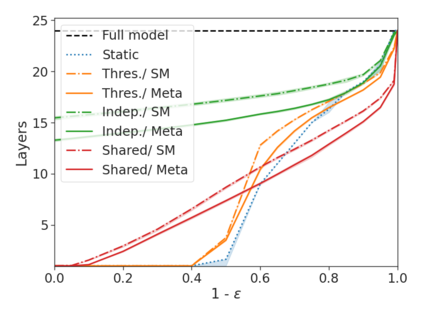
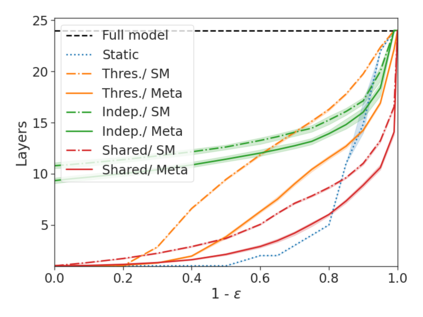
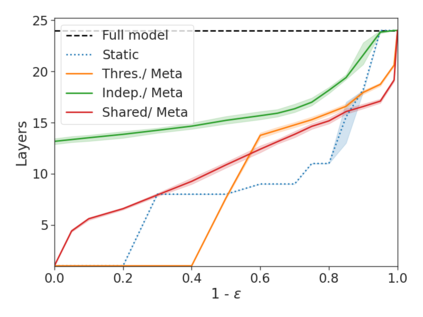
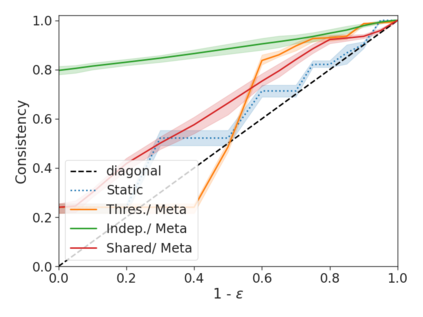
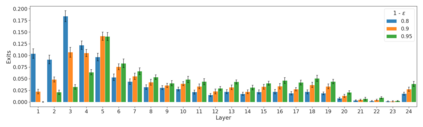
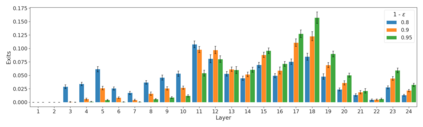
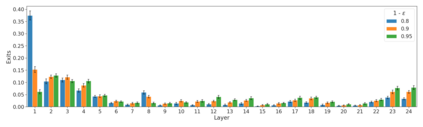
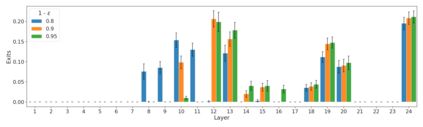
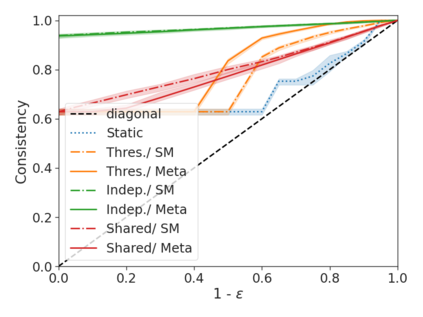
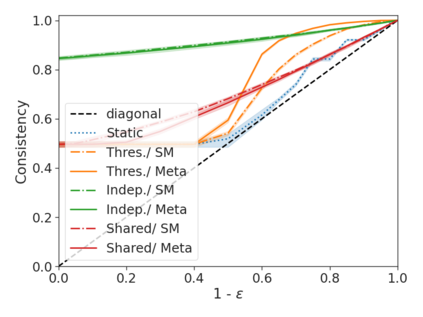
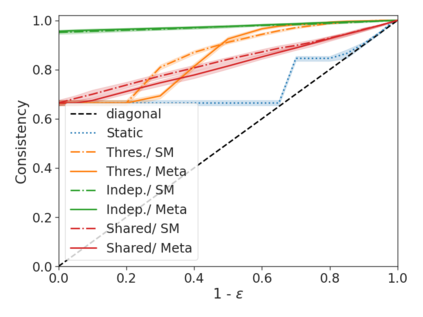
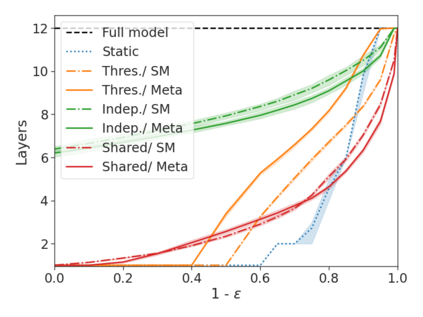
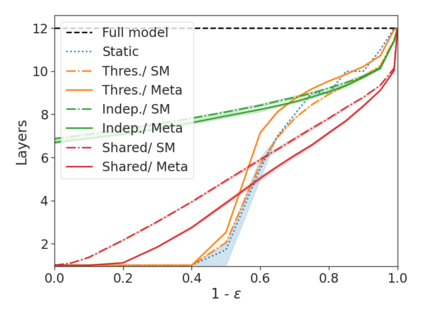
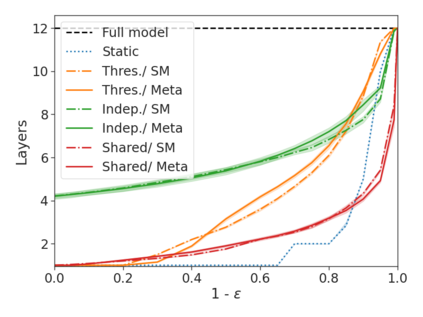
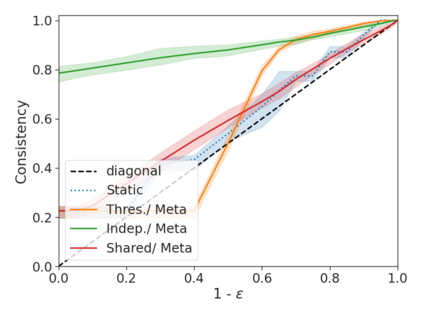
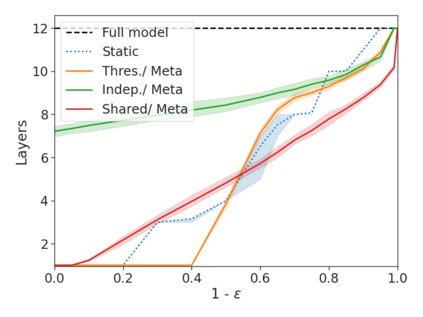
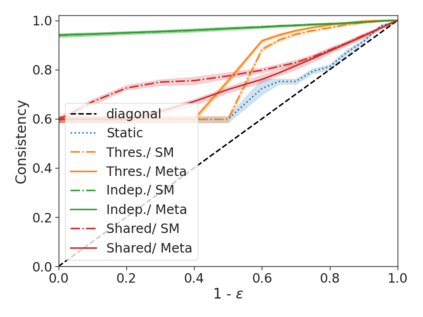
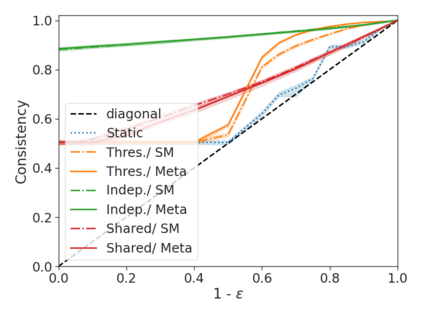
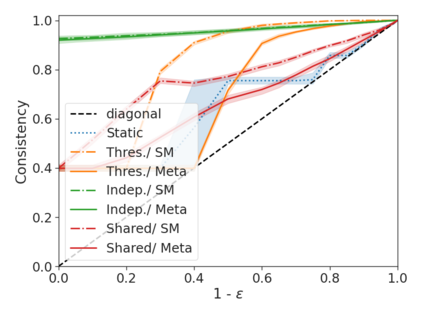
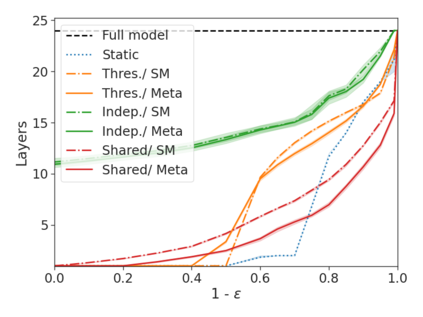
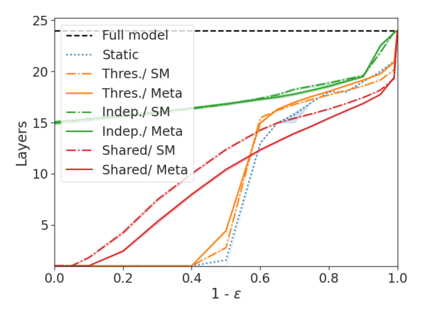
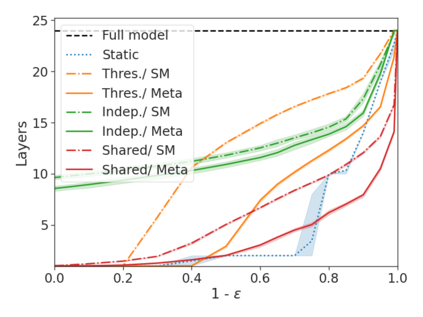
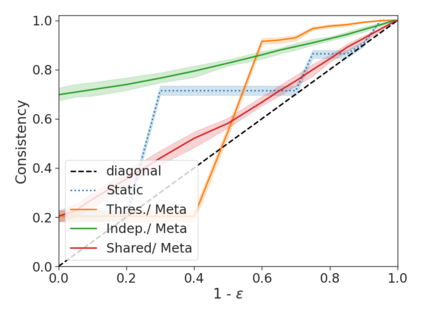
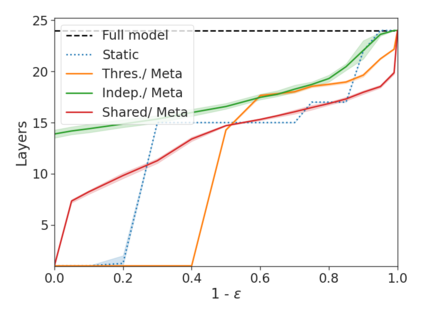
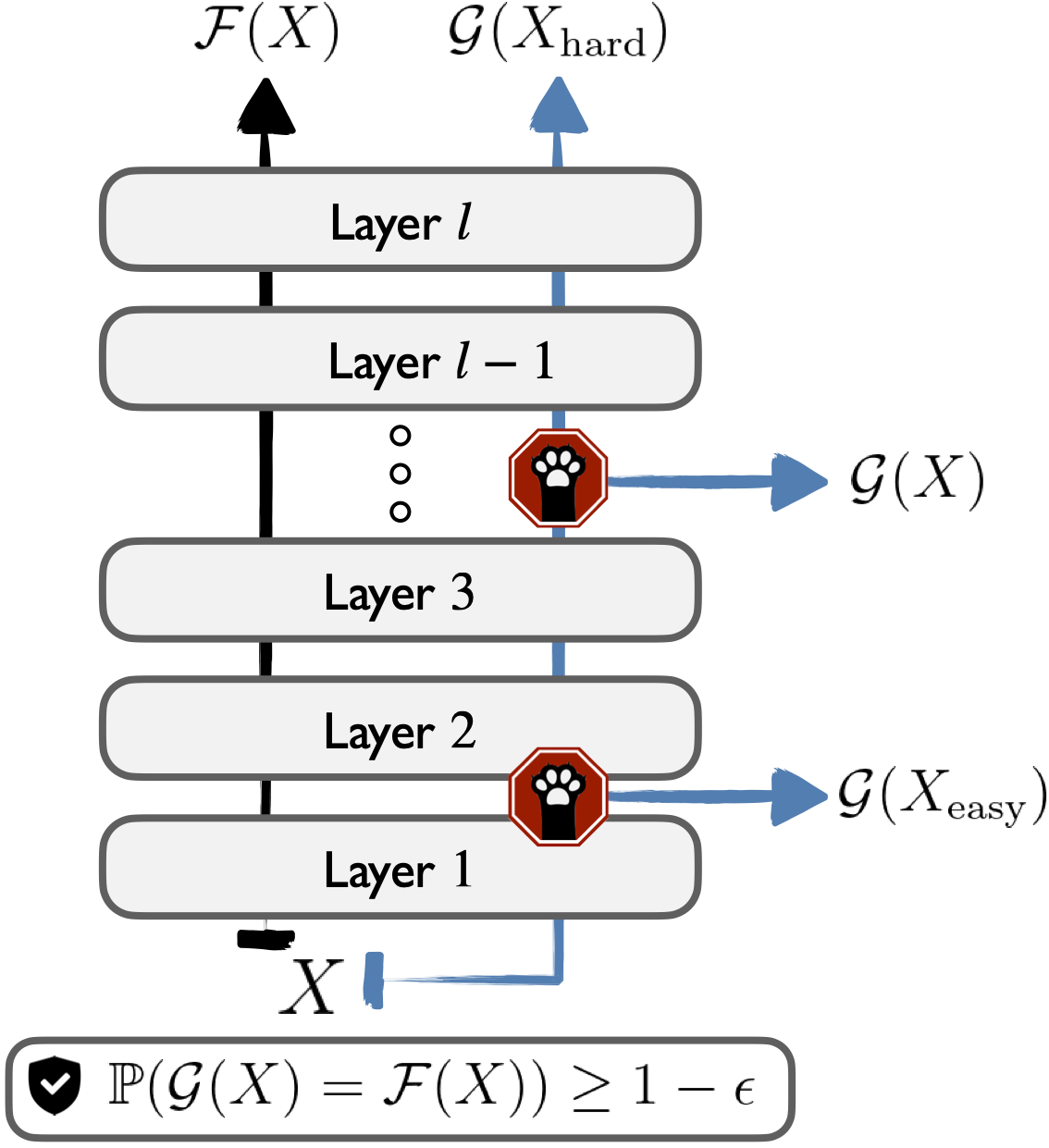
We develop a novel approach for confidently accelerating inference in the large and expensive multilayer Transformers that are now ubiquitous in natural language processing (NLP). Amortized or approximate computational methods increase efficiency, but can come with unpredictable performance costs. In this work, we present CATs -- Confident Adaptive Transformers -- in which we simultaneously increase computational efficiency, while guaranteeing a specifiable degree of consistency with the original model with high confidence. Our method trains additional prediction heads on top of intermediate layers, and dynamically decides when to stop allocating computational effort to each input using a meta consistency classifier. To calibrate our early prediction stopping rule, we formulate a unique extension of conformal prediction. We demonstrate the effectiveness of this approach on four classification and regression tasks.
翻译:我们开发了一种新颖的方法,以有信心地加速对目前自然语言处理中普遍存在的大型和昂贵的多层变换器(NLP)的推论。 摊销或接近计算方法提高了效率,但可能会带来无法预测的性能成本。 在这项工作中,我们介绍了CATs -- -- 自信的适应变换器 -- -- 我们同时提高计算效率,同时以高度信心保证与原始模型的可预见程度一致。 我们的方法在中间层顶部培训了额外的预测头,并动态地决定何时停止使用元一致性分类器将计算工作分配给每项输入。为了校准我们的早期预测停止规则,我们制定了一个独特的符合预测的延伸。我们展示了这一方法在四种分类和回归任务上的有效性。