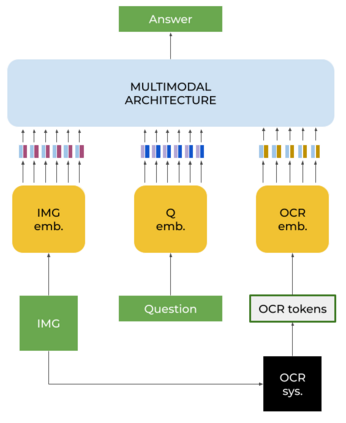
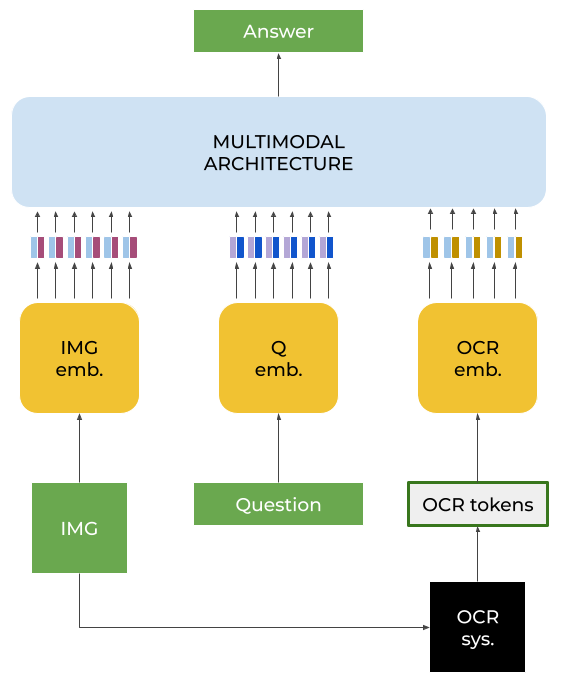
In this paper, we present a framework for Multilingual Scene Text Visual Question Answering that deals with new languages in a zero-shot fashion. Specifically, we consider the task of Scene Text Visual Question Answering (STVQA) in which the question can be asked in different languages and it is not necessarily aligned to the scene text language. Thus, we first introduce a natural step towards a more generalized version of STVQA: MUST-VQA. Accounting for this, we discuss two evaluation scenarios in the constrained setting, namely IID and zero-shot and we demonstrate that the models can perform on a par on a zero-shot setting. We further provide extensive experimentation and show the effectiveness of adapting multilingual language models into STVQA tasks.
翻译:在本文中,我们提出了一个多语种现场文字视觉问答框架,以零发方式处理新语言。具体地说,我们考虑现场文字视觉问答(STVQA)的任务,在这项任务中,可以以不同语言提出问题,但不一定与现场文字语言一致。因此,我们首先采取自然步骤,争取更普及的STVQA版本:MOST-VQA。为此,我们讨论了限制环境下的两个评估方案,即ID和零发,我们证明模型可以在零发环境中以等价进行,我们进一步提供了广泛的实验,并展示了将多语种语言模式纳入STVQA任务的有效性。