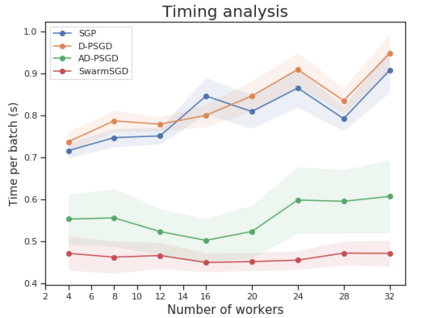
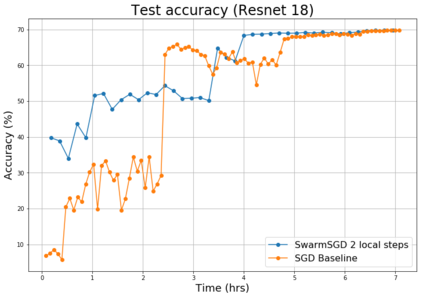
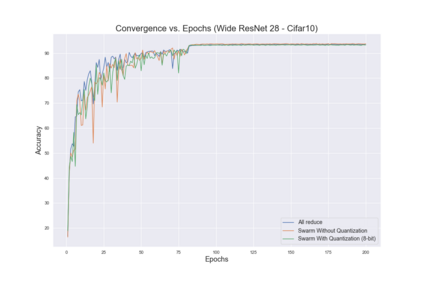
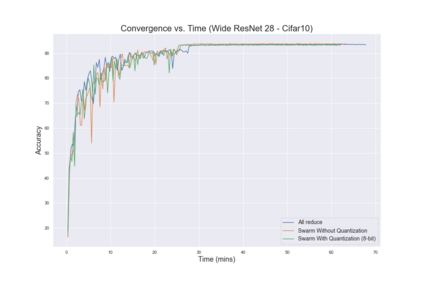
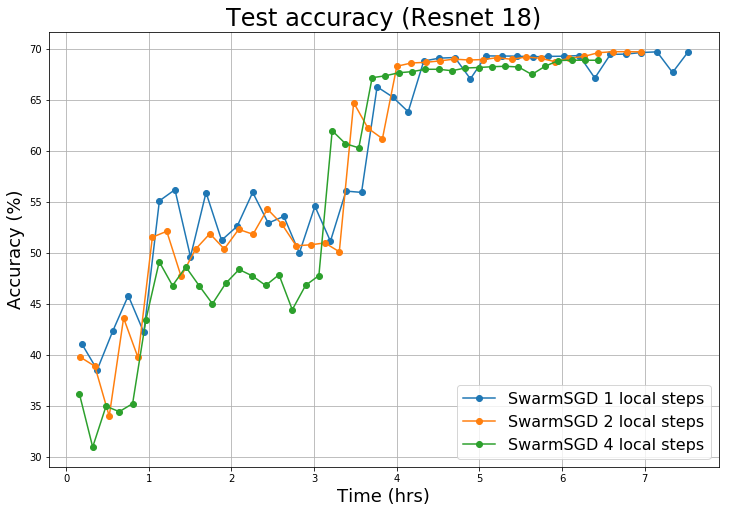
The ability to scale distributed optimization to large node counts has been one of the main enablers of recent progress in machine learning. To this end, several techniques have been explored, such as asynchronous, decentralized, or quantized communication--which significantly reduce the cost of synchronization, and the ability for nodes to perform several local model updates before communicating--which reduces the frequency of synchronization. In this paper, we show that these techniques, which have so far been considered independently, can be jointly leveraged to minimize distribution cost for training neural network models via stochastic gradient descent (SGD). We consider a setting with minimal coordination: we have a large number of nodes on a communication graph, each with a local subset of data, performing independent SGD updates onto their local models. After some number of local updates, each node chooses an interaction partner uniformly at random from its neighbors, and averages a possibly quantized version of its local model with the neighbor's model. Our first contribution is in proving that, even under such a relaxed setting, SGD can still be guaranteed to converge under standard assumptions. The proof is based on a new connection with parallel load-balancing processes, and improves existing techniques by jointly handling decentralization, asynchrony, quantization, and local updates, and by bounding their impact. On the practical side, we implement variants of our algorithm and deploy them onto distributed environments, and show that they can successfully converge and scale for large-scale image classification and translation tasks, matching or even slightly improving the accuracy of previous methods.
翻译:将分布式优化缩放到大节点计数的能力一直是最近机器学习进展的主要推动因素之一。 为此,我们探索了几种技术,例如不同步、分散或量化通信技术,这些技术大大降低了同步成本,降低了节点在通信前进行若干本地模型更新的能力,降低了同步频率。在本文中,我们表明,迄今为止独立考虑过的这些技术可以联合利用,以尽量减少通过轻度梯度下降(SGD)来培训神经网络模型的分布成本。我们考虑的设置是最小的协调:我们有一个通信图上有大量的节点,每个有当地一组数据,对本地模型进行独立的SGD更新。在进行一些本地更新之后,每个节点在与其邻居随机地选择一个互动伙伴,平均可以将其本地模型的四分解版本与邻居模型一起进行。我们的第一个贡献是证明,即使在如此宽松的分类方法下,SGD仍然可以保证在标准假设下整合。我们的证据基于新的分级化和分级化环境,我们通过同时的分级化、分级和分级流程,在新的分级流程上显示新的分级流程中进行。