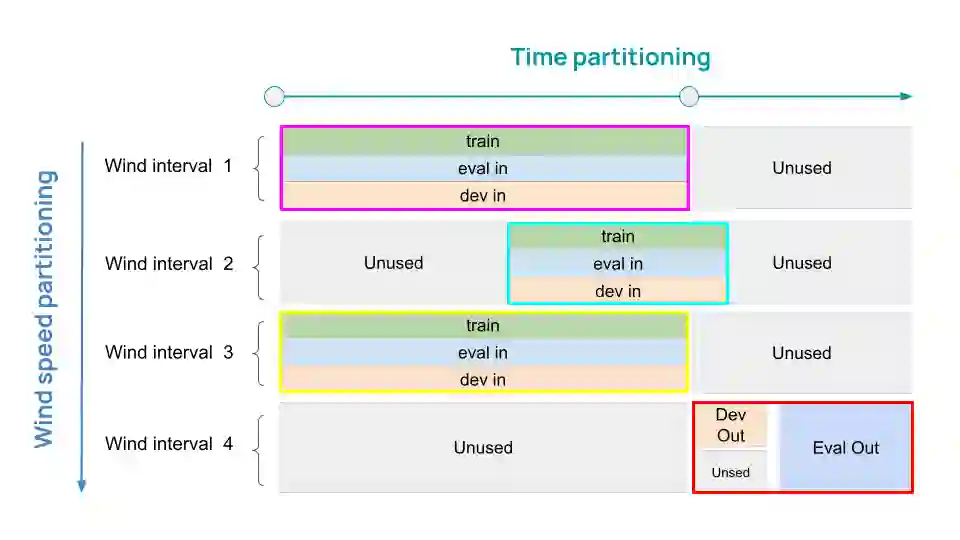
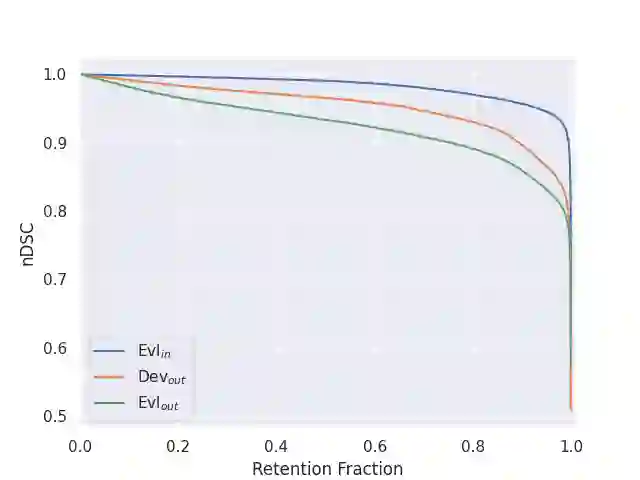
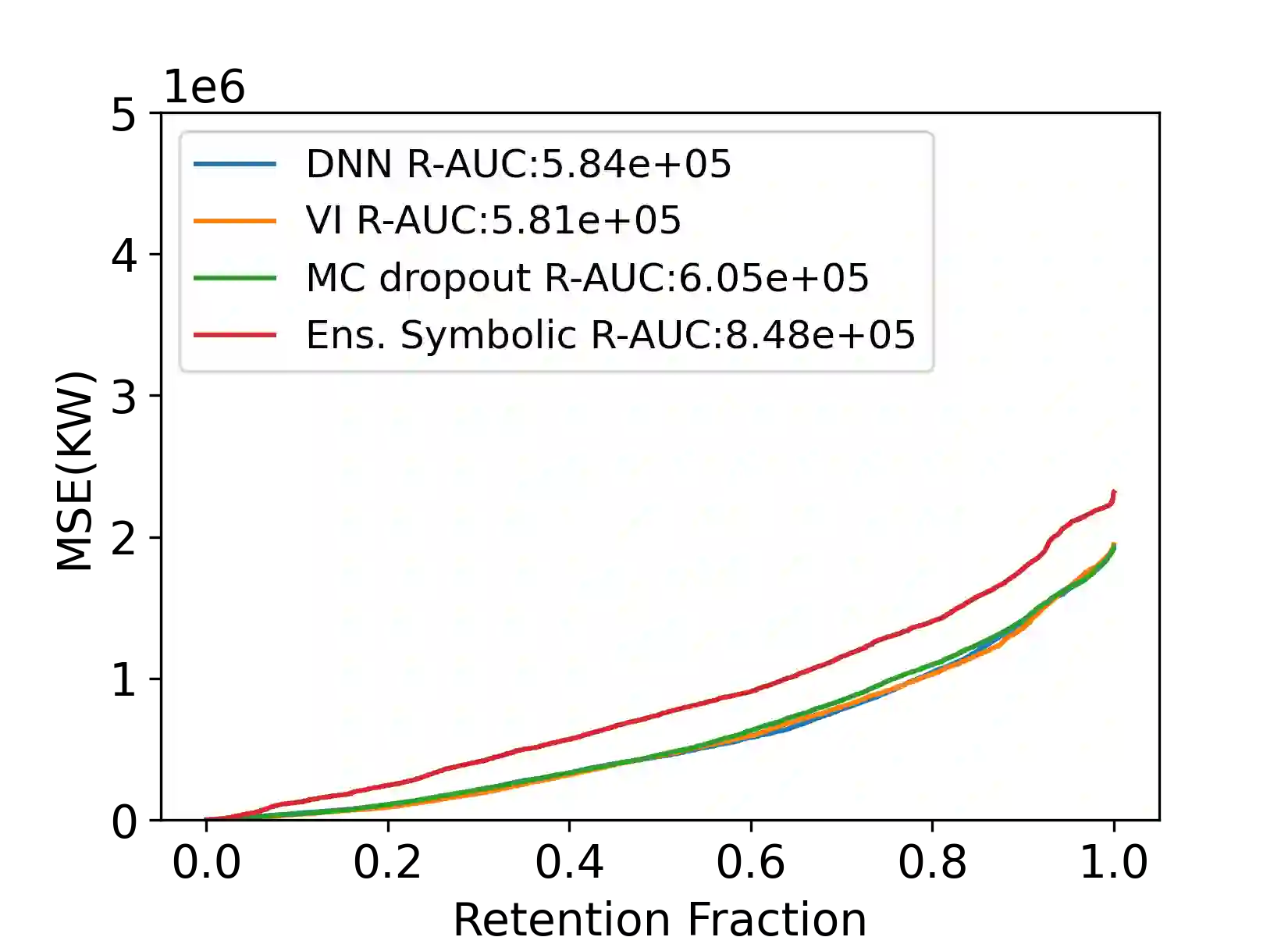
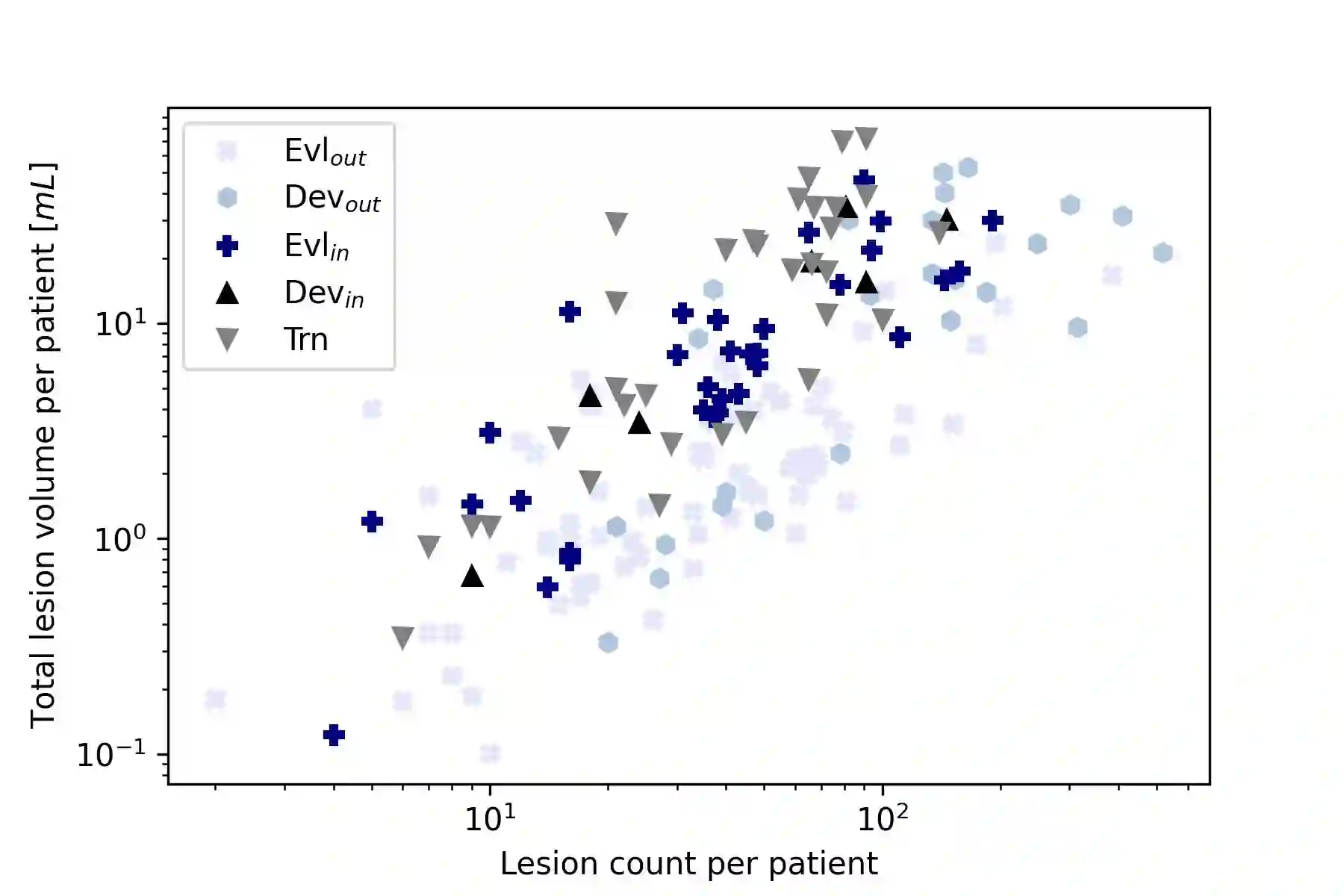
Distributional shift, or the mismatch between training and deployment data, is a significant obstacle to the usage of machine learning in high-stakes industrial applications, such as autonomous driving and medicine. This creates a need to be able to assess how robustly ML models generalize as well as the quality of their uncertainty estimates. Standard ML baseline datasets do not allow these properties to be assessed, as the training, validation and test data are often identically distributed. Recently, a range of dedicated benchmarks have appeared, featuring both distributionally matched and shifted data. Among these benchmarks, the Shifts dataset stands out in terms of the diversity of tasks as well as the data modalities it features. While most of the benchmarks are heavily dominated by 2D image classification tasks, Shifts contains tabular weather forecasting, machine translation, and vehicle motion prediction tasks. This enables the robustness properties of models to be assessed on a diverse set of industrial-scale tasks and either universal or directly applicable task-specific conclusions to be reached. In this paper, we extend the Shifts Dataset with two datasets sourced from industrial, high-risk applications of high societal importance. Specifically, we consider the tasks of segmentation of white matter Multiple Sclerosis lesions in 3D magnetic resonance brain images and the estimation of power consumption in marine cargo vessels. Both tasks feature ubiquitous distributional shifts and a strict safety requirement due to the high cost of errors. These new datasets will allow researchers to further explore robust generalization and uncertainty estimation in new situations. In this work, we provide a description of the dataset and baseline results for both tasks.
翻译:分布变化,或培训与部署数据之间的不匹配,是使用机器学习在工业应用(如自主驾驶和医学)中采用高档数据的重大障碍,这就需要能够评估ML模型的广度和不确定性估计的质量。标准 ML基线数据集不允许评估这些属性,因为培训、验证和测试数据分布相同。最近出现了一系列专用基准,既有分布匹配,也有转移的数据。在这些基准中, Shift数据集在任务的多样性以及数据模式中显得很突出。虽然大多数基准都在很大程度上以2D图像分类任务为主,但 Shifts包含表格天气预报、机器翻译和车辆运动预测任务的质量。这使得无法评估模型的稳健性特性,因为各种工业规模任务以及普遍或直接适用的任务结论往往分布相同。在本文件中,我们将变换数据集扩展为两个数据数据集,其来源是工业、高风险、社会重要性高档数据应用。具体地说,变换模型包含表格天气预报、机器翻译以及车辆运动预测任务的质量。我们考虑将高档的磁力分析任务,将这种测测测测测测测数据任务中的高级任务,将允许海洋结构结构的重判。