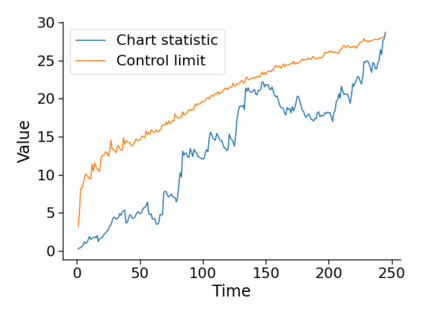
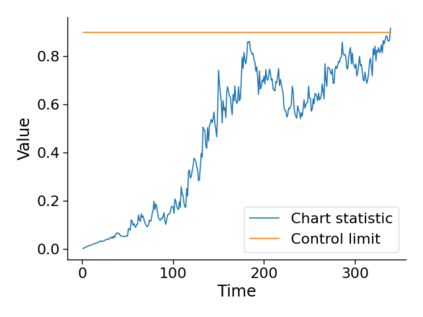
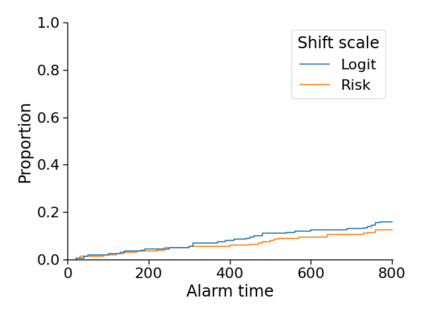
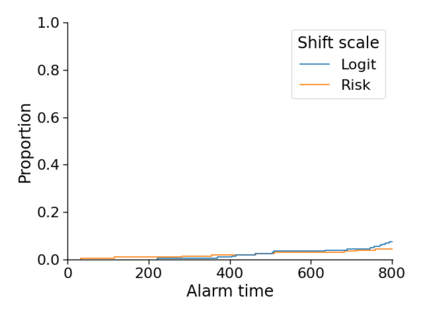
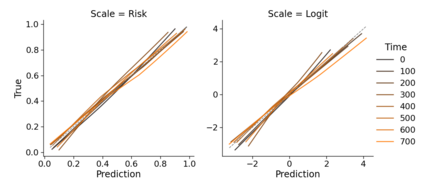
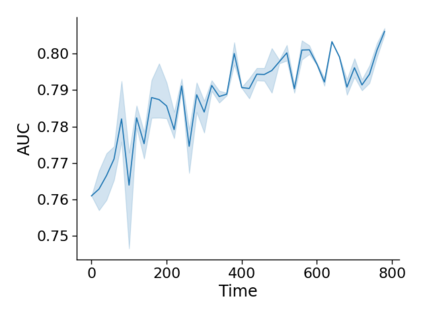
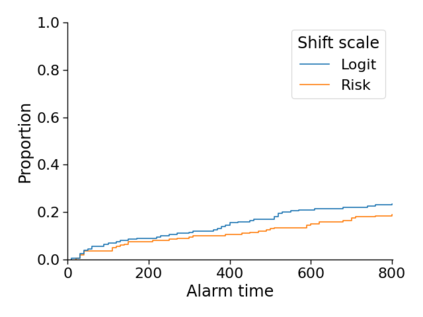
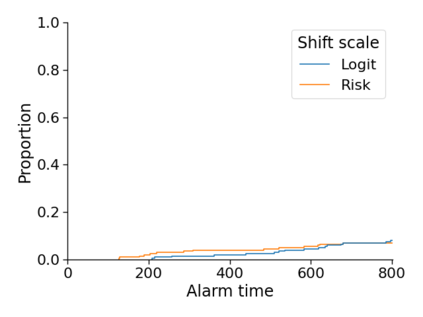
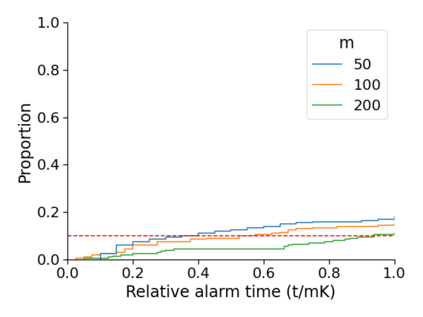
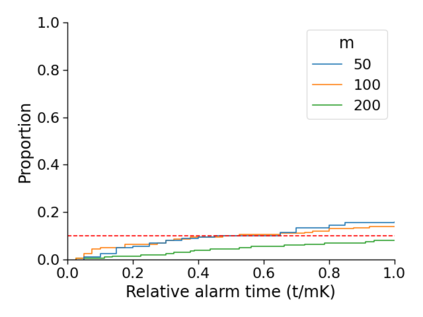
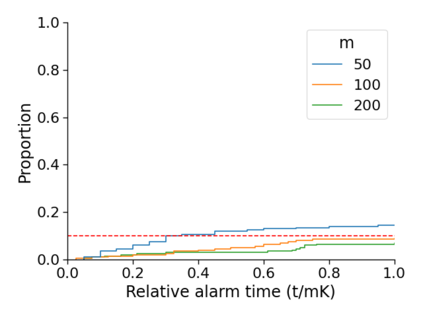
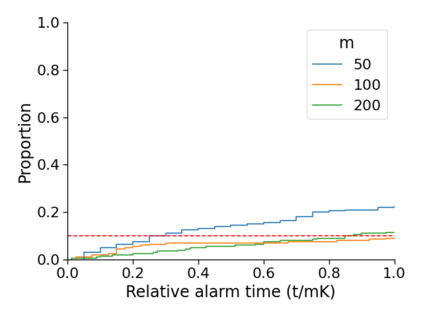
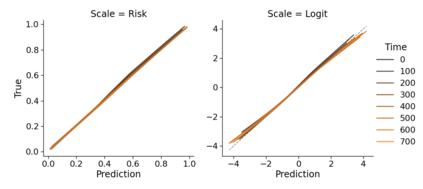
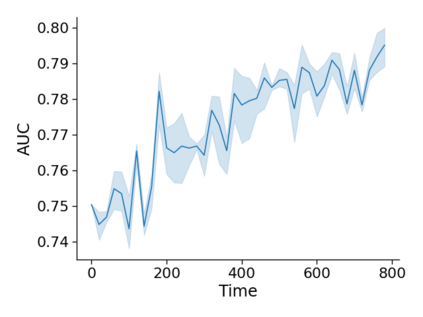
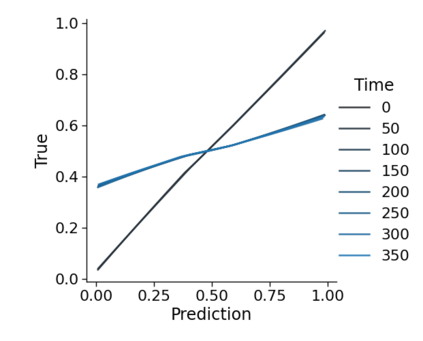
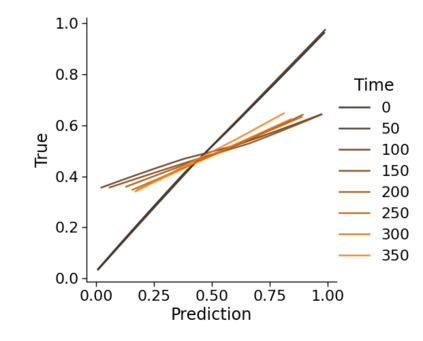
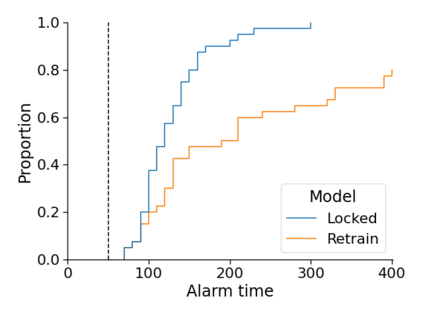
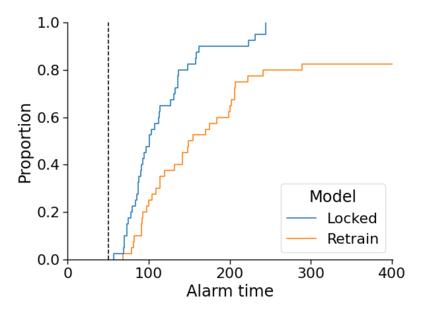
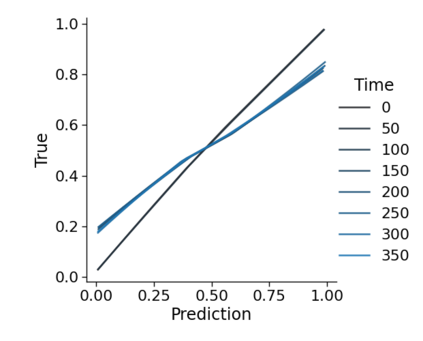
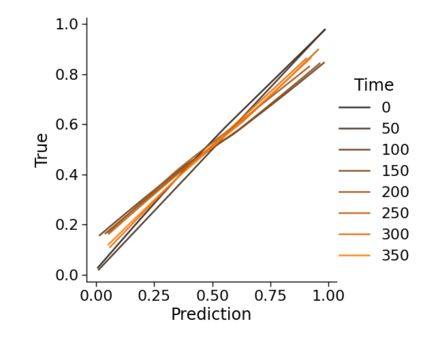
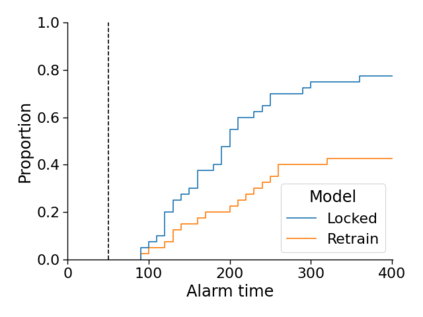
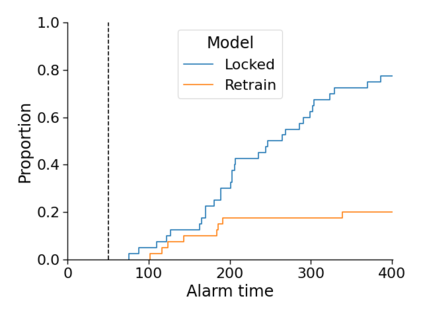
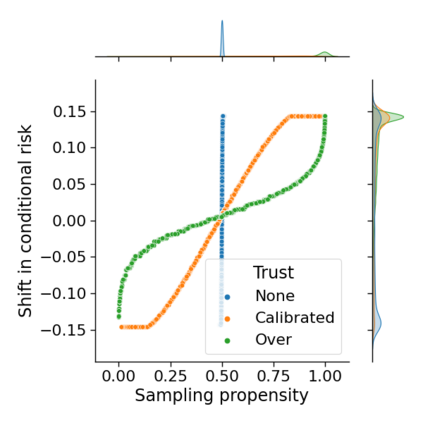
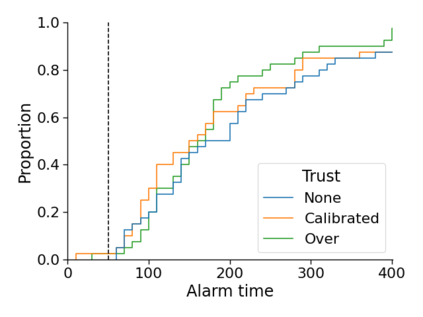
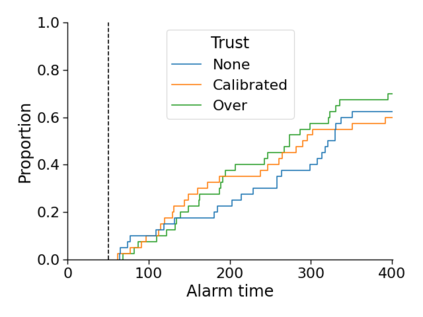
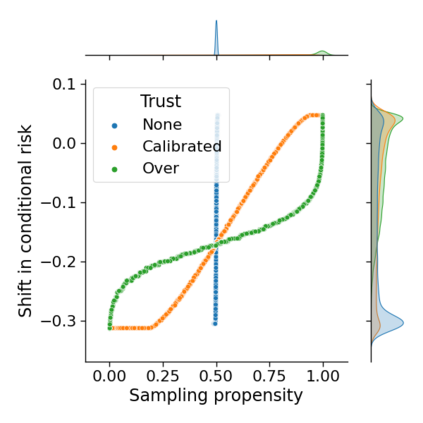
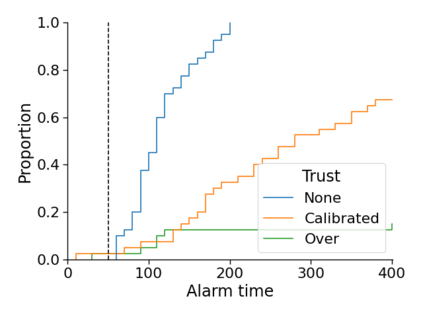
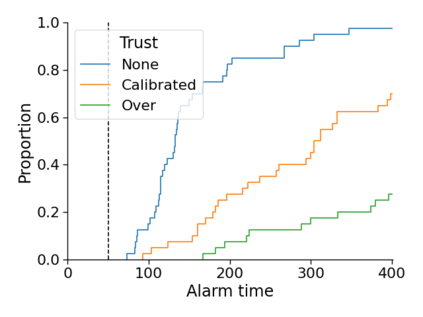
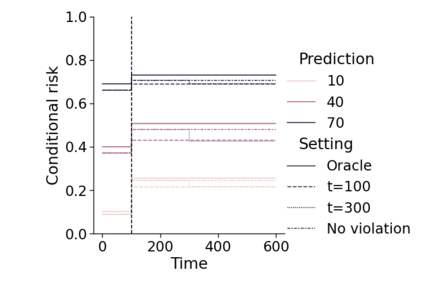
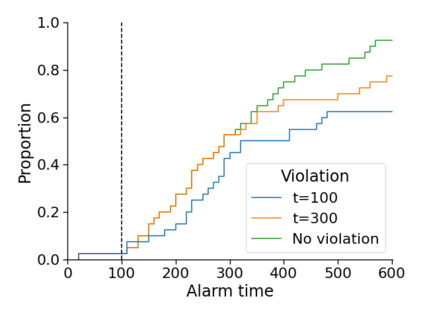
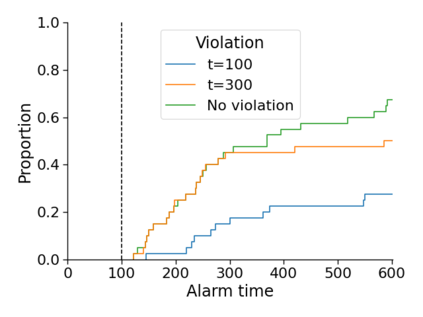
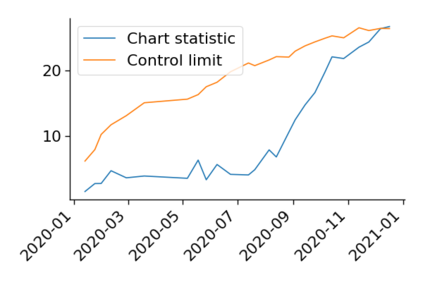
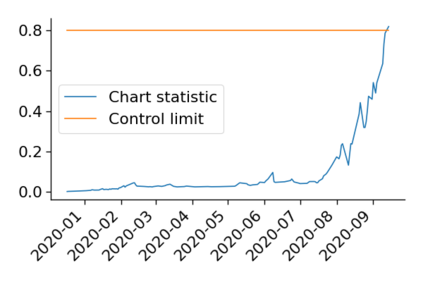
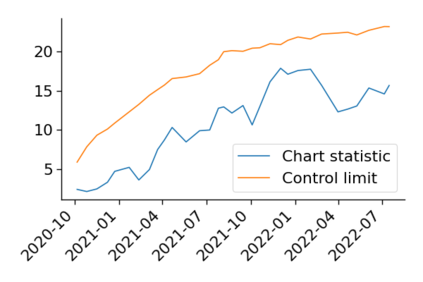
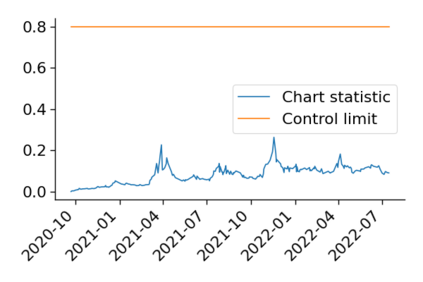
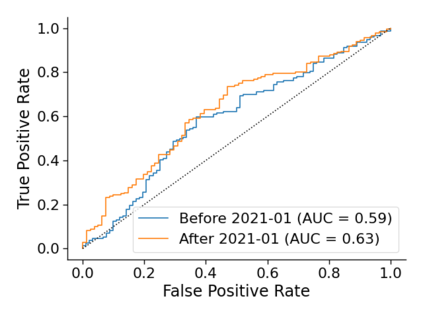
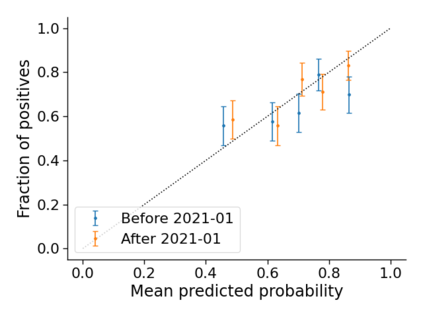
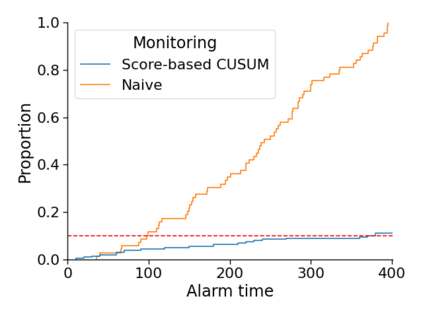
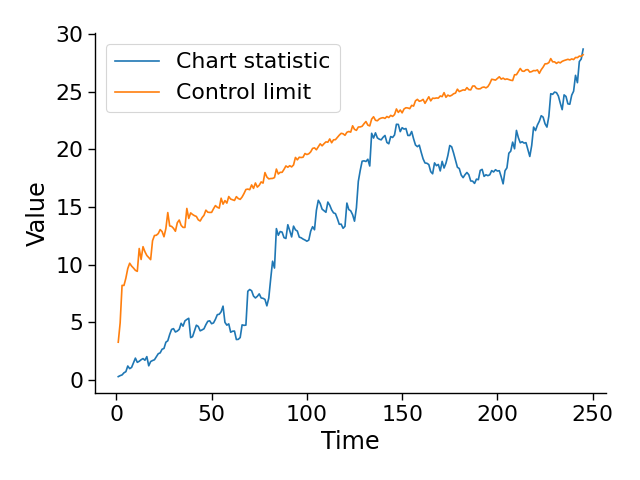
Monitoring the performance of machine learning (ML)-based risk prediction models in healthcare is complicated by the issue of confounding medical interventions (CMI): when an algorithm predicts a patient to be at high risk for an adverse event, clinicians are more likely to administer prophylactic treatment and alter the very target that the algorithm aims to predict. Ignoring CMI by monitoring only the untreated patients--whose outcomes remain unaltered--can inflate false alarm rates, because the evolution of both the model and clinician-ML interactions can induce complex dependencies in the data that violate standard assumptions. A more sophisticated approach is to explicitly account for CMI by modeling treatment propensities, but its time-varying nature makes accurate estimation difficult. Given the many sources of complexity in the data, it is important to determine situations in which a simple procedure that ignores CMI provides valid inference. Here we describe the special case of monitoring model calibration, under either the assumption of conditional exchangeability or time-constant selection bias. We introduce a new score-based cumulative sum (CUSUM) chart for monitoring in a frequentist framework and review an alternative approach using Bayesian inference. Through simulations, we investigate the benefits of combining model updating with monitoring and study when over-trust in a prediction model does (or does not) delay detection. Finally, we simulate monitoring an ML-based postoperative nausea and vomiting risk calculator during the COVID-19 pandemic.
翻译:医疗干预措施的混乱问题(CMI)使基于机学(ML)的风险预测模型监测工作复杂化:当算法预测病人对不利事件有高风险时,临床医生更有可能进行预防性治疗,并改变算法所要预测的目标。CMI只监测未经治疗的病人和其结果仍未改变的病人,从而忽略错误警报率,因为模型和诊所-ML相互作用的演变可能会在数据中造成违反标准假设的复杂依赖性。一个更复杂的方法是,通过模拟治疗倾向来明确说明CMI的下落,但其时间变化的性质使得难以准确估计。鉴于数据中的许多复杂来源,重要的是要确定这样一种情况,即无视CMI的简单程序提供了正确的推断。这里我们描述了监测模型校准的特殊案例,即假设有条件的互换性或基于时间的MLM-ML互动,我们采用新的分数累积(CUSUM)累积(CMI)图,通过模拟性预测框架和模拟测试结果,我们使用一种模拟性预测方法来监测最终的BIV(在模拟检测和模拟测试过程中,通过模拟分析结果,进行一项模拟分析)的模拟评估结果,对结果进行模拟分析,对结果进行模拟分析,对结果进行模拟分析,对结果进行模拟分析。