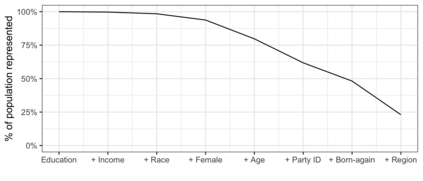
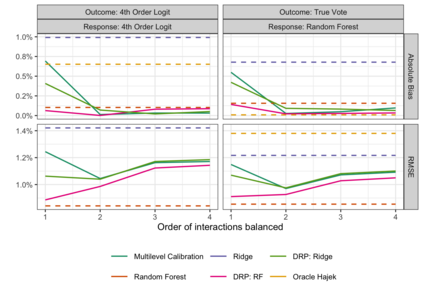
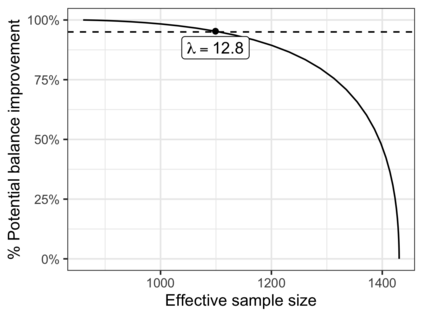
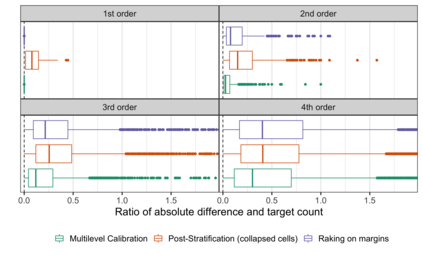
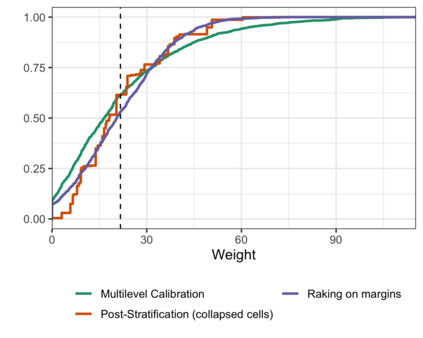
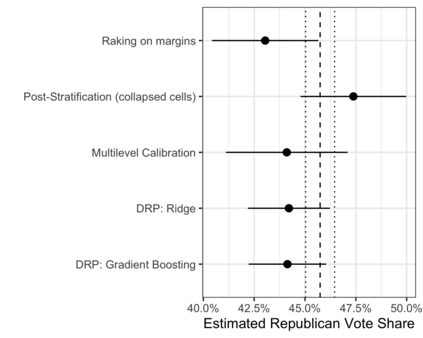
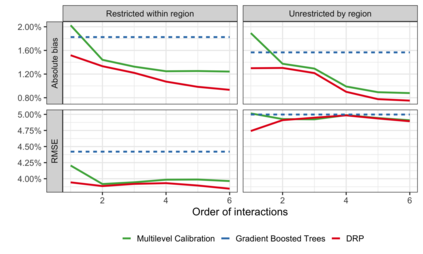
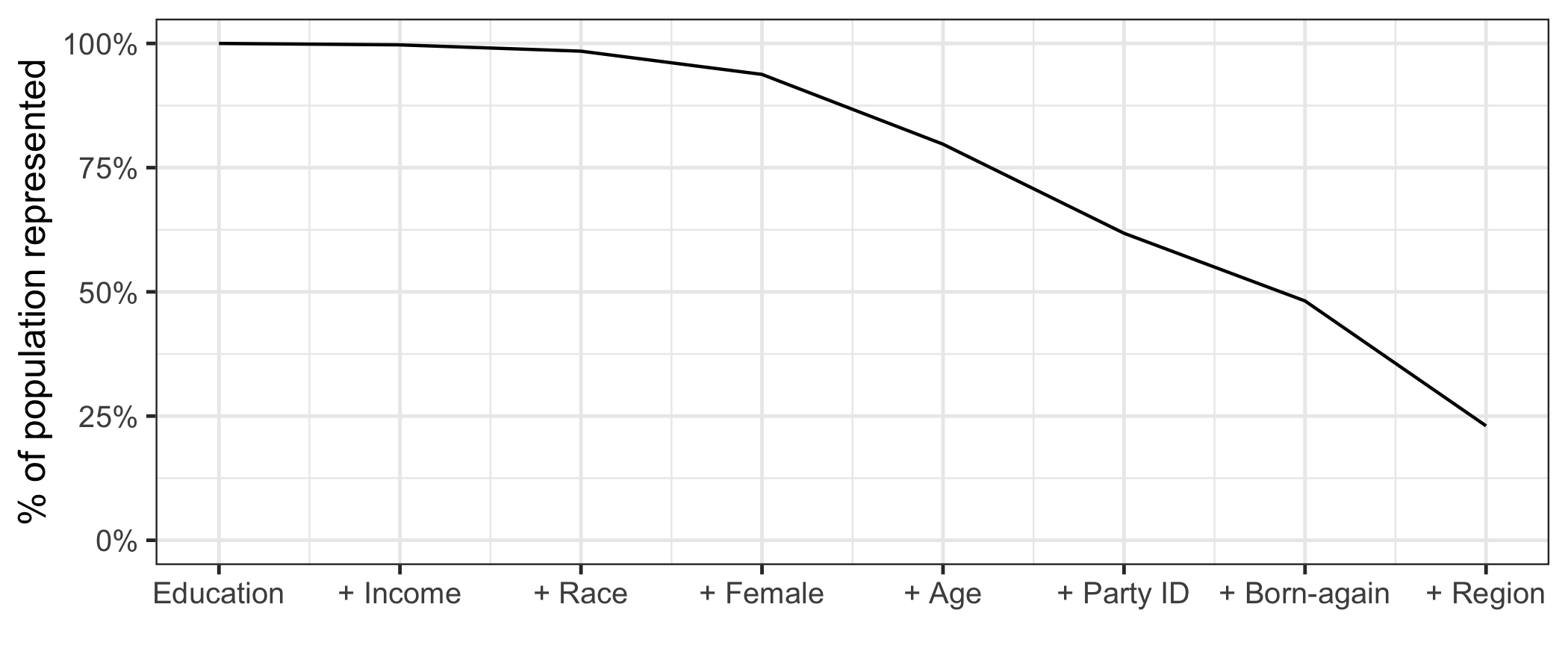
In the November 2016 U.S. presidential election, many state level public opinion polls, particularly in the Upper Midwest, incorrectly predicted the winning candidate. One leading explanation for this polling miss is that the precipitous decline in traditional polling response rates led to greater reliance on statistical methods to adjust for the corresponding bias -- and that these methods failed to adjust for important interactions between key variables like education, race, and geographic region. Finding calibration weights that account for important interactions remains challenging with traditional survey methods: raking typically balances the margins alone, while post-stratification, which exactly balances all interactions, is only feasible for a small number of variables. In this paper, we propose multilevel calibration weighting, which enforces tight balance constraints for marginal balance and looser constraints for higher-order interactions. This incorporates some of the benefits of post-stratification while retaining the guarantees of raking. We then correct for the bias due to the relaxed constraints via a flexible outcome model; we call this approach Double Regression with Post-stratification (DRP). We characterize the asymptotic properties of these estimators and show that the proposed calibration approach has a dual representation as a multilevel model for survey response. We then use these tools to to re-assess a large-scale survey of voter intention in the 2016 U.S. presidential election, finding meaningful gains from the proposed methods. The approach is available in the multical R package.
翻译:在2016年11月的美国总统选举中,许多州一级的民意测验,特别是在上中西部州,错误地预测了获胜候选人。对本次投票空缺的一个主要解释是,传统投票响应率的急剧下降导致更多地依赖统计方法来调整相应的偏差,而这些方法未能适应教育、种族和地理区域等关键变量之间的重要互动。在传统调查方法中,许多州一级的民意测验,特别是在上中西部州,错误地预测了获胜候选人。许多州一级的民意测验,特别是在上中西部州,错误地预测了获胜候选人。这次投票空缺的一个主要解释是:传统调查方法仍然具有挑战性:通常只平衡差额,而完全平衡所有互动的州一级的民意测验后,只有一小部分变量才可行。在本文件中,我们建议多层次校准校准校准加权,对边际平衡和较松散的对更高级别互动的限制。这包括了批准后的一些好处,同时保留了萎缩的保证。我们随后纠正了由于通过灵活的结果模式放松限制而产生的偏差造成的偏差;我们称之为“双级回归”和“事后批准”的方法(DP)。我们将这些这些估定这些“偏差者”的“选择”的属性属性属性属性属性属性属性特性描述这些“衡量”的“衡量”的“衡量”的“衡量”和“时,并展示”的“选择”的“选择”的“选择”的“选举”的“选举”的“比例”是“结果”的“结果的“结果的“结果的“结果”的“结果”的“比例”方法,显示的“我们”是“我们”的“我们”的“我们”的“对”的“选择”的“选择”的“选择”的“选择”的“在”的“选择”的“选择”的“选择”的“在”的“选择”的“选择”的“在”的“选择”的“在”的“在”的“选择”的“在”的“在”的“在”的“在”的“在”的“在”的“在”的“在”中,在”的“在”的“在”的“在”中,在”的“在”的“在”的“在”中,在”的“在”的“在”中,在”中进行中的“在”中进行中的“