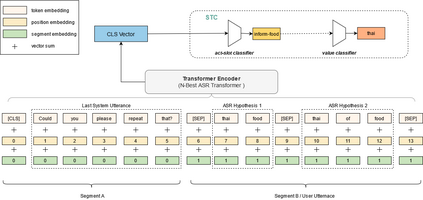
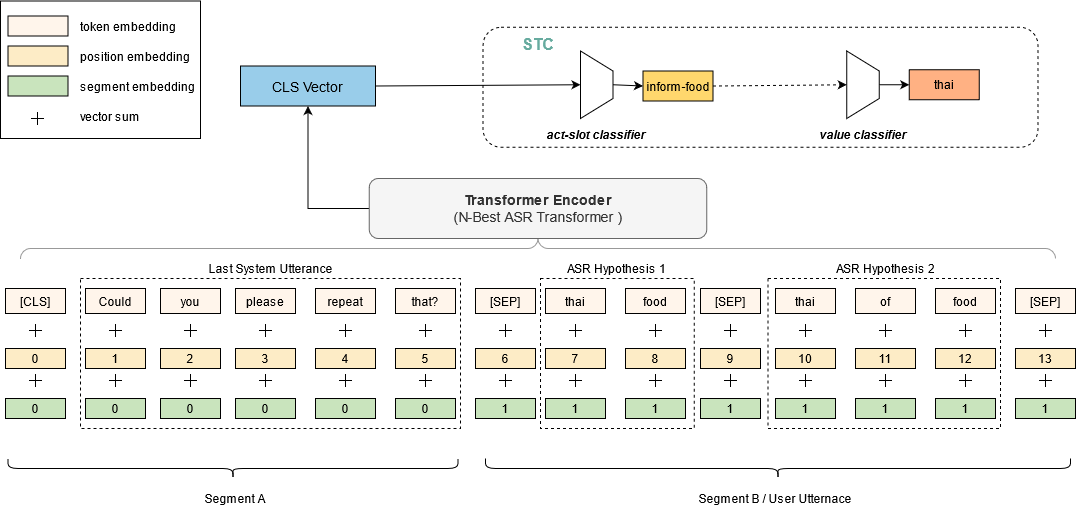
Spoken Language Understanding (SLU) systems parse speech into semantic structures like dialog acts and slots. This involves the use of an Automatic Speech Recognizer (ASR) to transcribe speech into multiple text alternatives (hypotheses). Transcription errors, common in ASRs, impact downstream SLU performance negatively. Approaches to mitigate such errors involve using richer information from the ASR, either in form of N-best hypotheses or word-lattices. We hypothesize that transformer models learn better with a simpler utterance representation using the concatenation of the N-best ASR alternatives, where each alternative is separated by a special delimiter [SEP]. In our work, we test our hypothesis by using concatenated N-best ASR alternatives as the input to transformer encoder models, namely BERT and XLM-RoBERTa, and achieve performance equivalent to the prior state-of-the-art model on DSTC2 dataset. We also show that our approach significantly outperforms the prior state-of-the-art when subjected to the low data regime. Additionally, this methodology is accessible to users of third-party ASR APIs which do not provide word-lattice information.
翻译:语言理解(SLU)系统将语言分析分析成语义结构,如对话行为和空档。这涉及使用自动语音识别器(ASR)将语言转换成多文本替代物(假称) 。 ASR中常见的描述错误对下游 SLU 性能产生负面的影响。 减轻这种错误的方法包括使用来自ASR的更丰富的信息,或者以最佳假设或文字相对立的形式。 我们假设变压器模型学习得更好,使用N-最佳ASR替代物的配方进行更简单的发音表达,其中每种替代物都由特别划界器(SEP)分离。 在我们的工作中,我们测试我们的假设是,使用配制的N-最佳ASR替代物作为变压器编码模型(即BERT和XLM-ROBERTA)的输入,并实现与DSTC2数据集先前的状态模型相当的性能。 我们还表明,我们的方法大大超越了受低数据系统约束的API第三种状态。