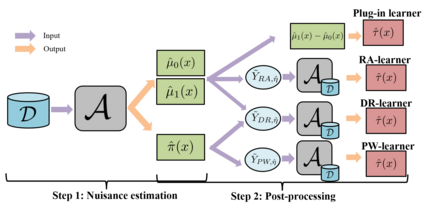
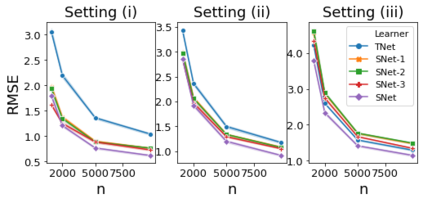
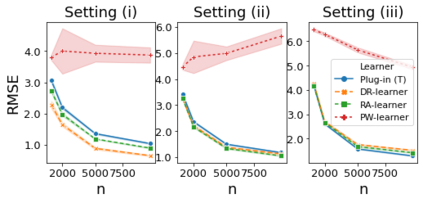
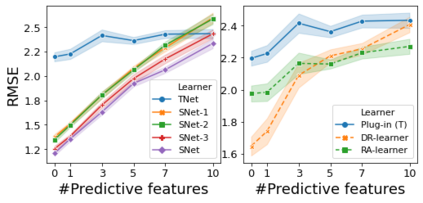
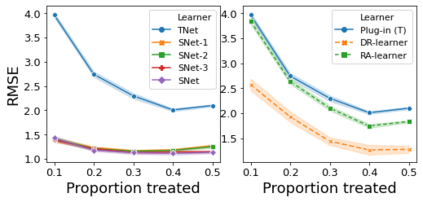
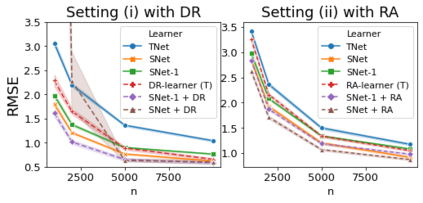
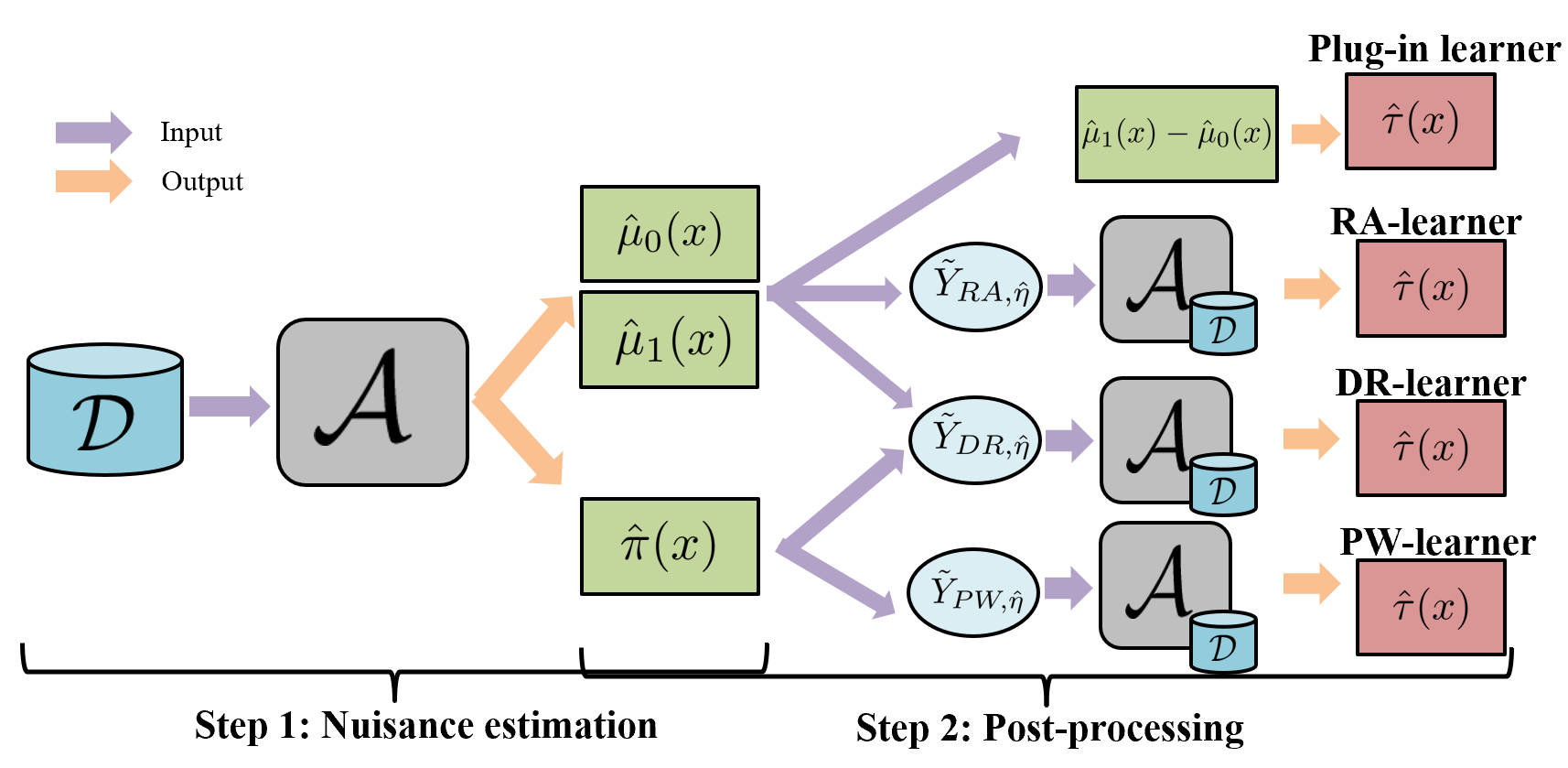
The need to evaluate treatment effectiveness is ubiquitous in most of empirical science, and interest in flexibly investigating effect heterogeneity is growing rapidly. To do so, a multitude of model-agnostic, nonparametric meta-learners have been proposed in recent years. Such learners decompose the treatment effect estimation problem into separate sub-problems, each solvable using standard supervised learning methods. Choosing between different meta-learners in a data-driven manner is difficult, as it requires access to counterfactual information. Therefore, with the ultimate goal of building better understanding of the conditions under which some learners can be expected to perform better than others a priori, we theoretically analyze four broad meta-learning strategies which rely on plug-in estimation and pseudo-outcome regression. We highlight how this theoretical reasoning can be used to guide principled algorithm design and translate our analyses into practice by considering a variety of neural network architectures as base-learners for the discussed meta-learning strategies. In a simulation study, we showcase the relative strengths of the learners under different data-generating processes.
翻译:在大多数经验科学中,评估治疗有效性的必要性是普遍存在的,灵活调查效果差异的兴趣正在迅速增长。为此,近年来提出了许多模型-不可知性、非参数性超脱产器。这些学习者将治疗效应估计问题分解成不同的子问题,每个问题都采用标准监督的学习方法。很难以数据驱动的方式在不同的超脱产器之间进行选择,因为这需要获得反事实信息。因此,为了最终更好地认识某些学习者在哪些条件下能够比其他学习者更出色地工作,我们从理论上分析了四种广泛的元学习战略,这些战略依赖插头估计和假结果回归。我们强调,如何利用这种理论推理来指导有原则的算法设计,并通过考虑各种神经网络结构作为讨论的元学习战略的基础分离器,将我们的分析转化为实践。在模拟研究中,我们展示了不同数据生成过程中学习者的相对优势。