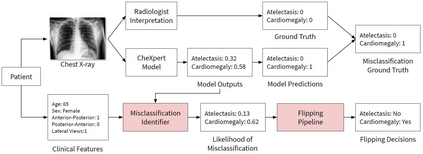
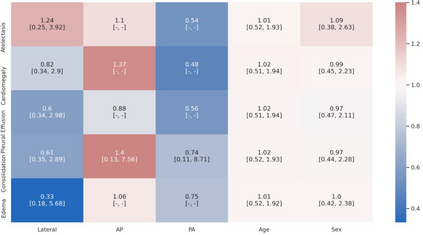
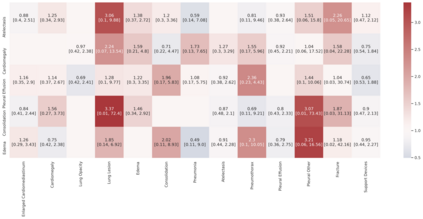
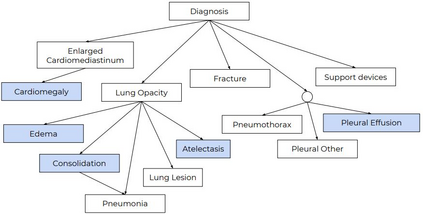
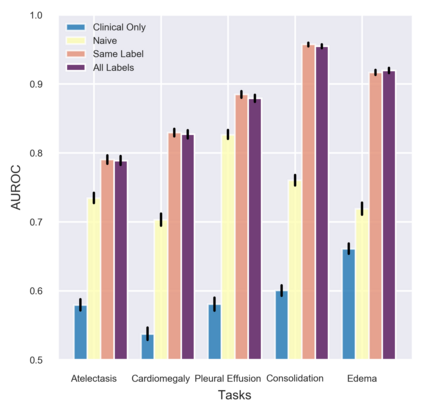
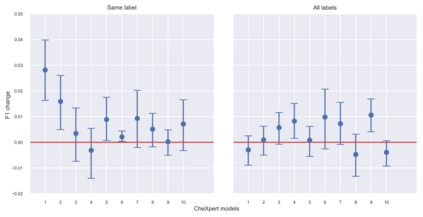
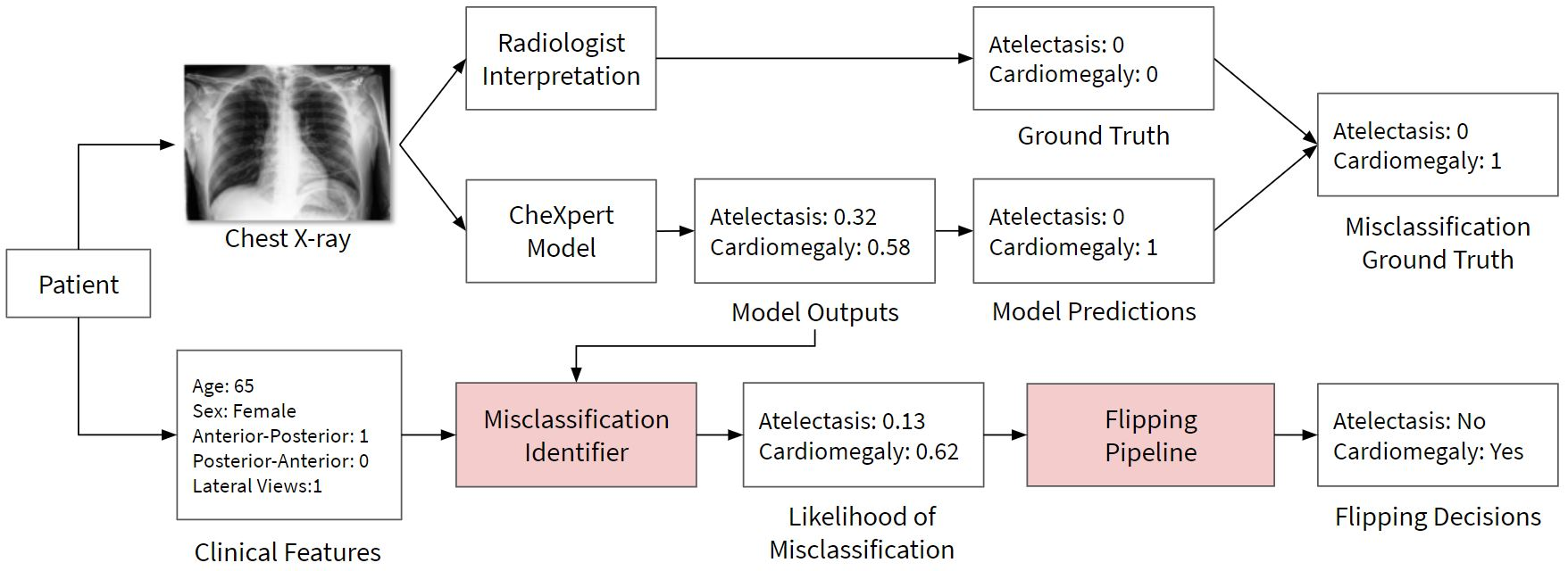
A major obstacle to the integration of deep learning models for chest x-ray interpretation into clinical settings is the lack of understanding of their failure modes. In this work, we first investigate whether there are patient subgroups that chest x-ray models are likely to misclassify. We find that patient age and the radiographic finding of lung lesion, pneumothorax or support devices are statistically relevant features for predicting misclassification for some chest x-ray models. Second, we develop misclassification predictors on chest x-ray models using their outputs and clinical features. We find that our best performing misclassification identifier achieves an AUROC close to 0.9 for most diseases. Third, employing our misclassification identifiers, we develop a corrective algorithm to selectively flip model predictions that have high likelihood of misclassification at inference time. We observe F1 improvement on the prediction of Consolidation (0.008 [95% CI 0.005, 0.010]) and Edema (0.003, [95% CI 0.001, 0.006]). By carrying out our investigation on ten distinct and high-performing chest x-ray models, we are able to derive insights across model architectures and offer a generalizable framework applicable to other medical imaging tasks.
翻译:将胸前X射线解释的深学习模型纳入临床环境的一个主要障碍是缺乏对其失败模式的理解。在这项工作中,我们首先调查是否有胸前X射线模型可能错误分类的病人分组;我们发现,病人年龄和肺损伤、肺炎球菌或辅助装置的放射调查结果是预测某些胸前X射线模型错误分类的统计相关特征;第二,我们利用胸部X射线模型的产出和临床特征,在胸前X射线模型上开发错误分类预测器。我们发现,我们最能执行的分类错误识别器在大多数疾病上达到接近0.9的AUROC。第三,我们使用错误分类识别器,我们开发了一种纠正算法,选择在发酵时极有可能发生错误分类的翻转模型预测。我们观察到,对合并预测(0.008 [95% CI0.005, 0.010] 和爱德马(0.003,[95% CI0.001,0.006] )的F1改进了。我们通过对10个独特和高性胸透的X射线模型进行调查,我们能够了解其他可应用的图像框架。