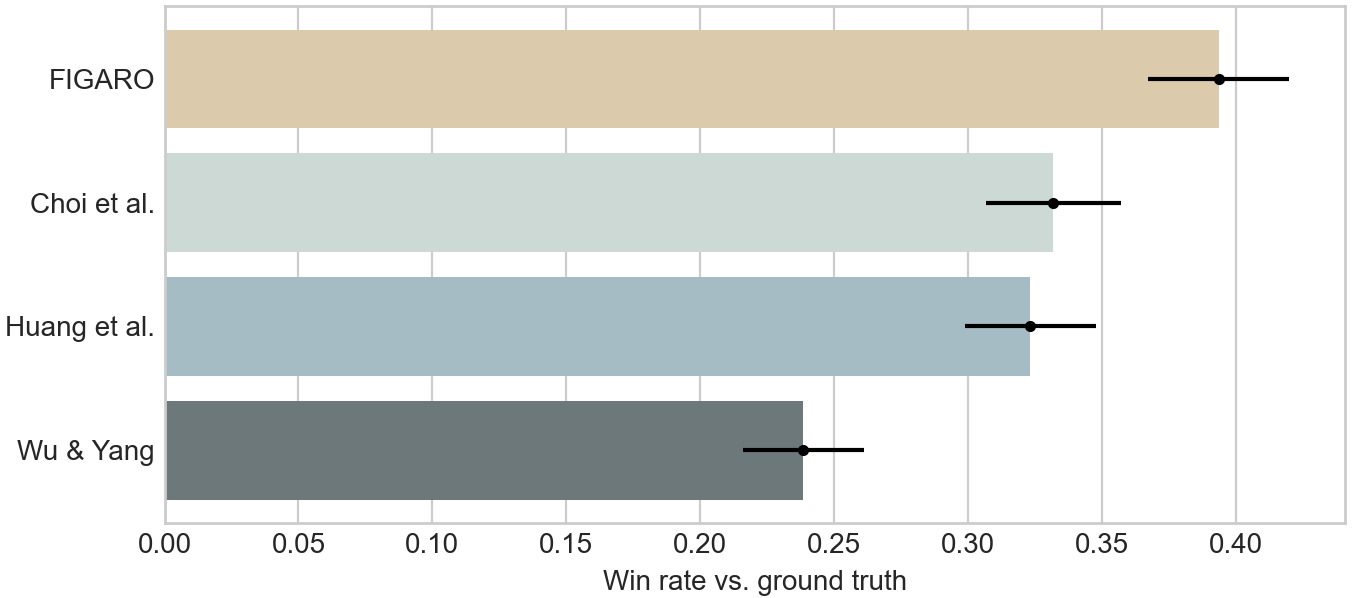
Generating music with deep neural networks has been an area of active research in recent years. While the quality of generated samples has been steadily increasing, most methods are only able to exert minimal control over the generated sequence, if any. We propose the self-supervised description-to-sequence task, which allows for fine-grained controllable generation on a global level. We do so by extracting high-level features about the target sequence and learning the conditional distribution of sequences given the corresponding high-level description in a sequence-to-sequence modelling setup. We train FIGARO (FIne-grained music Generation via Attention-based, RObust control) by applying description-to-sequence modelling to symbolic music. By combining learned high level features with domain knowledge, which acts as a strong inductive bias, the model achieves state-of-the-art results in controllable symbolic music generation and generalizes well beyond the training distribution.
翻译:近年来,通过深层神经网络生成音乐一直是积极研究的领域。虽然所生成样品的质量一直在稳步提高,但大多数方法只能对所生成的序列(如果有的话)进行最低限度的控制。我们建议进行自我监督的描述到序列任务,这样可以在全球范围内进行细微的可控生成。我们这样做的方法是提取目标序列的高层次特征,并学习在序列到序列建模设置中根据相应的高层次描述有条件的序列分布。我们通过对象征性音乐应用描述到序列的模型来培训FIGARO(FINEGARO)(通过基于注意的RObust 控制) 。通过将高层次的特征与广域知识相结合,而广域知识作为强烈的诱导偏差作用,该模型在培训分布之外实现了可控的象征性音乐生成和普及效果。