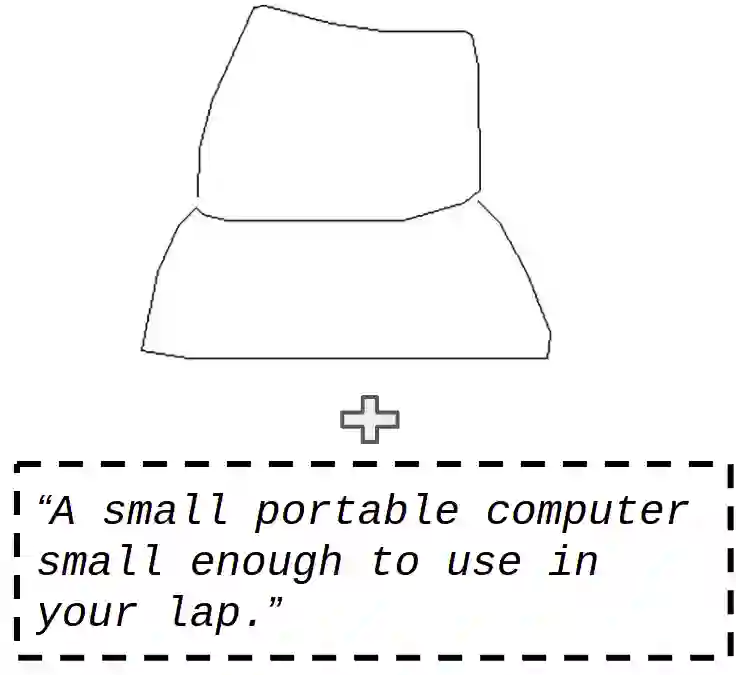
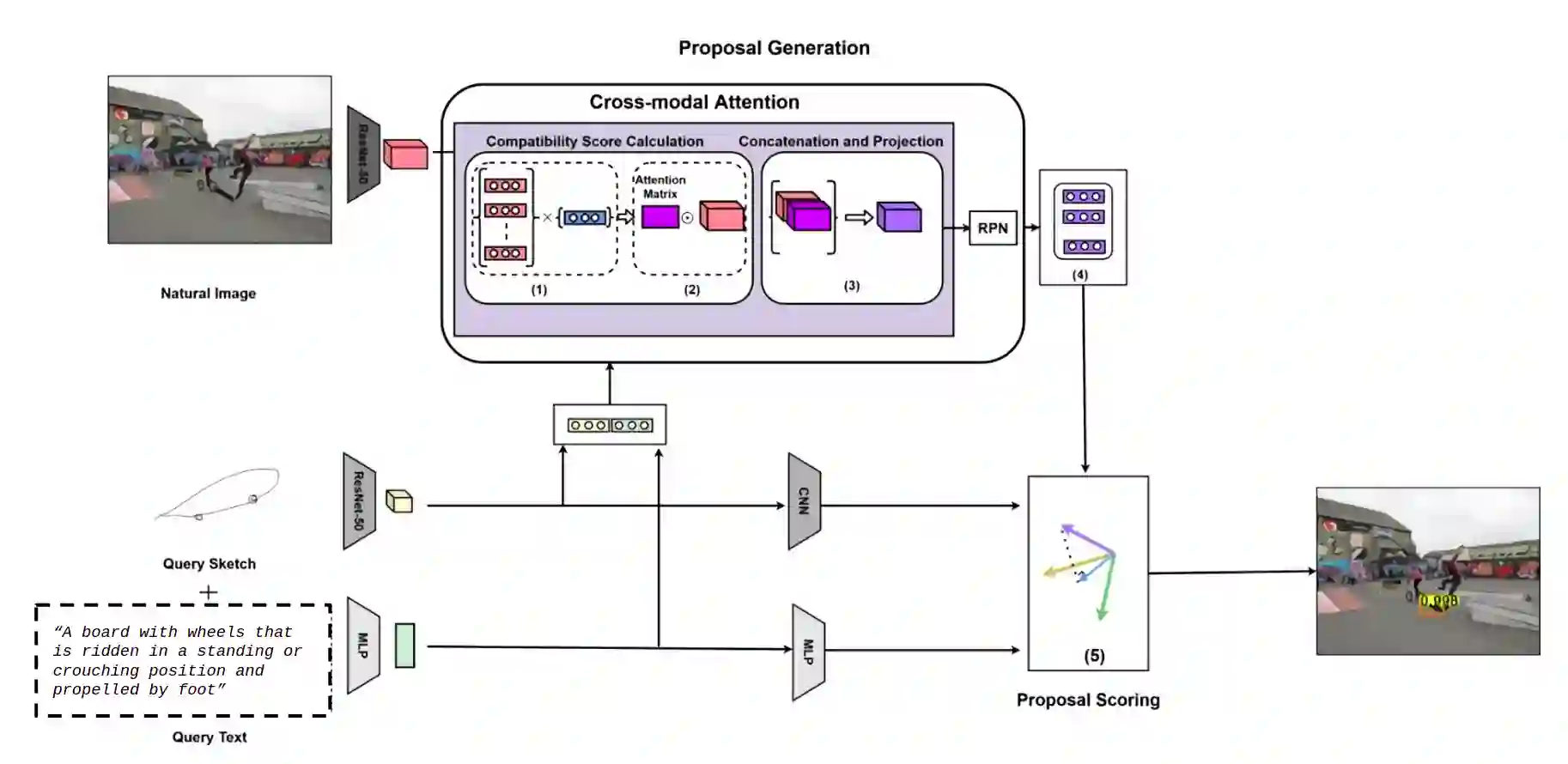
Consider a scenario in one-shot query-guided object localization where neither an image of the object nor the object category name is available as a query. In such a scenario, a hand-drawn sketch of the object could be a choice for a query. However, hand-drawn crude sketches alone, when used as queries, might be ambiguous for object localization, e.g., a sketch of a laptop could be confused for a sofa. On the other hand, a linguistic definition of the category, e.g., a small portable computer small enough to use in your lap" along with the sketch query, gives better visual and semantic cues for object localization. In this work, we present a multimodal query-guided object localization approach under the challenging open-set setting. In particular, we use queries from two modalities, namely, hand-drawn sketch and description of the object (also known as gloss), to perform object localization. Multimodal query-guided object localization is a challenging task, especially when a large domain gap exists between the queries and the natural images, as well as due to the challenge of combining the complementary and minimal information present across the queries. For example, hand-drawn crude sketches contain abstract shape information of an object, while the text descriptions often capture partial semantic information about a given object category. To address the aforementioned challenges, we present a novel cross-modal attention scheme that guides the region proposal network to generate object proposals relevant to the input queries and a novel orthogonal projection-based proposal scoring technique that scores each proposal with respect to the queries, thereby yielding the final localization results. ...
翻译:将一个图片或对象类别名称的图像都无法在您腿上使用的小便携计算机 和素描查询一样, 手画对象的草图可能是查询的选择。 但是, 单手画的粗略草图, 用作查询时, 可能对于对象的本地化模糊不清, 例如, 膝上型笔记本的草图可能会被沙发混淆。 另一方面, 该类别的语言定义, 例如, 一个小到足以在您腿上使用的小型便携式计算机, 与素描查询一起, 为对象本地化提供更好的视觉和语义提示提示。 在这种假设中, 我们用一个多式的自手画式目标定位图, 在具有挑战性的开放设置设置设置下, 单手画的粗粗粗粗粗的本地化方法。 手画的素描图和描述中, 以最小的本地化方法标定, 以我们给出的域标本为主页码的本地化方法, 并且以粗略的路径图解, 将当前精细的路径转换为图表 。