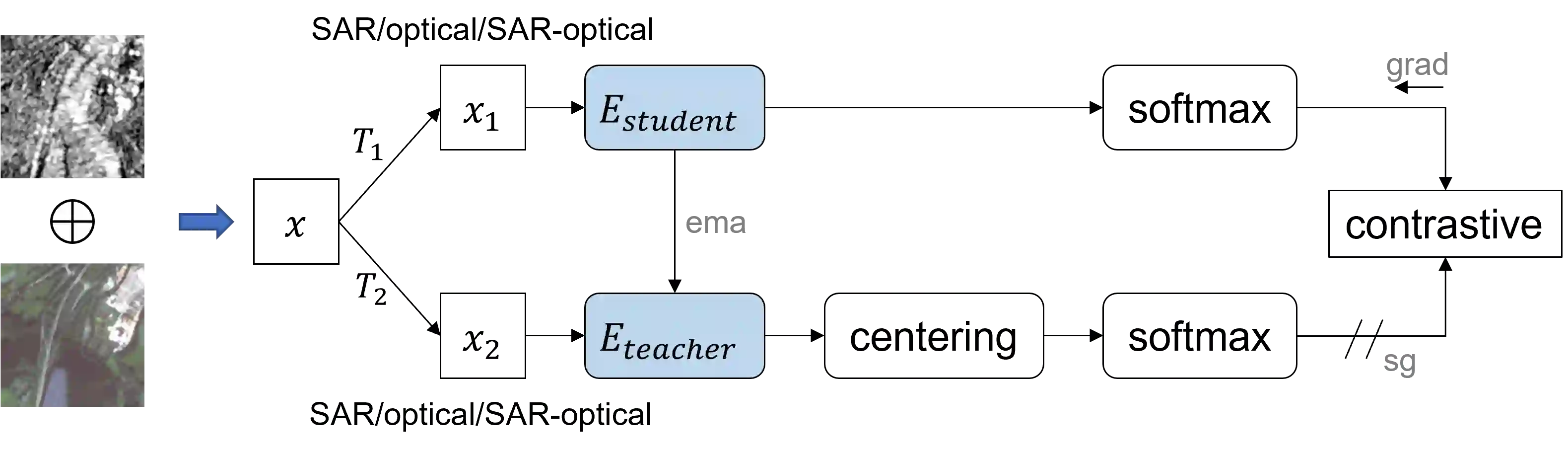
Self-supervised learning (SSL) has attracted much interest in remote sensing and earth observation due to its ability to learn task-agnostic representations without human annotation. While most of the existing SSL works in remote sensing utilize ConvNet backbones and focus on a single modality, we explore the potential of vision transformers (ViTs) for joint SAR-optical representation learning. Based on DINO, a state-of-the-art SSL algorithm that distills knowledge from two augmented views of an input image, we combine SAR and optical imagery by concatenating all channels to a unified input. Subsequently, we randomly mask out channels of one modality as a data augmentation strategy. While training, the model gets fed optical-only, SAR-only, and SAR-optical image pairs learning both inner- and intra-modality representations. Experimental results employing the BigEarthNet-MM dataset demonstrate the benefits of both, the ViT backbones and the proposed multimodal SSL algorithm DINO-MM.
翻译:自我监督的学习(SSL)吸引了人们对遥感和地球观测的极大兴趣,因为它有能力在不作人类说明的情况下学习任务不可知的表现,虽然现有的SSL大部分在遥感领域工作,利用ConvNet的骨干和专注于单一模式,但我们探索了视觉变压器(ViTs)在合成孔径雷达和光学联合教学中的潜力。根据DINO,一个从输入图像的两种扩大观点中提取知识的最先进的SSL算法,我们将合成孔径雷达和光学图像结合起来,将所有渠道归结为统一的输入。随后,我们随机将一种模式的渠道遮盖出来,作为数据增强战略。在培训的同时,该模型被输入只光学、仅求求光和合成孔光成图像配对,学习内部和内部的模拟。使用大地球网-MMM数据集的实验结果显示了VIT骨干和拟议的多式SL DINO-MM算法的好处。