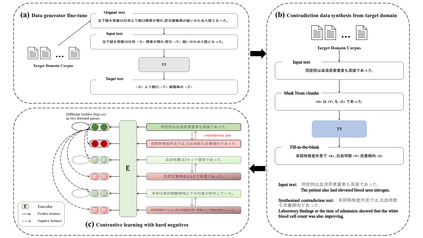
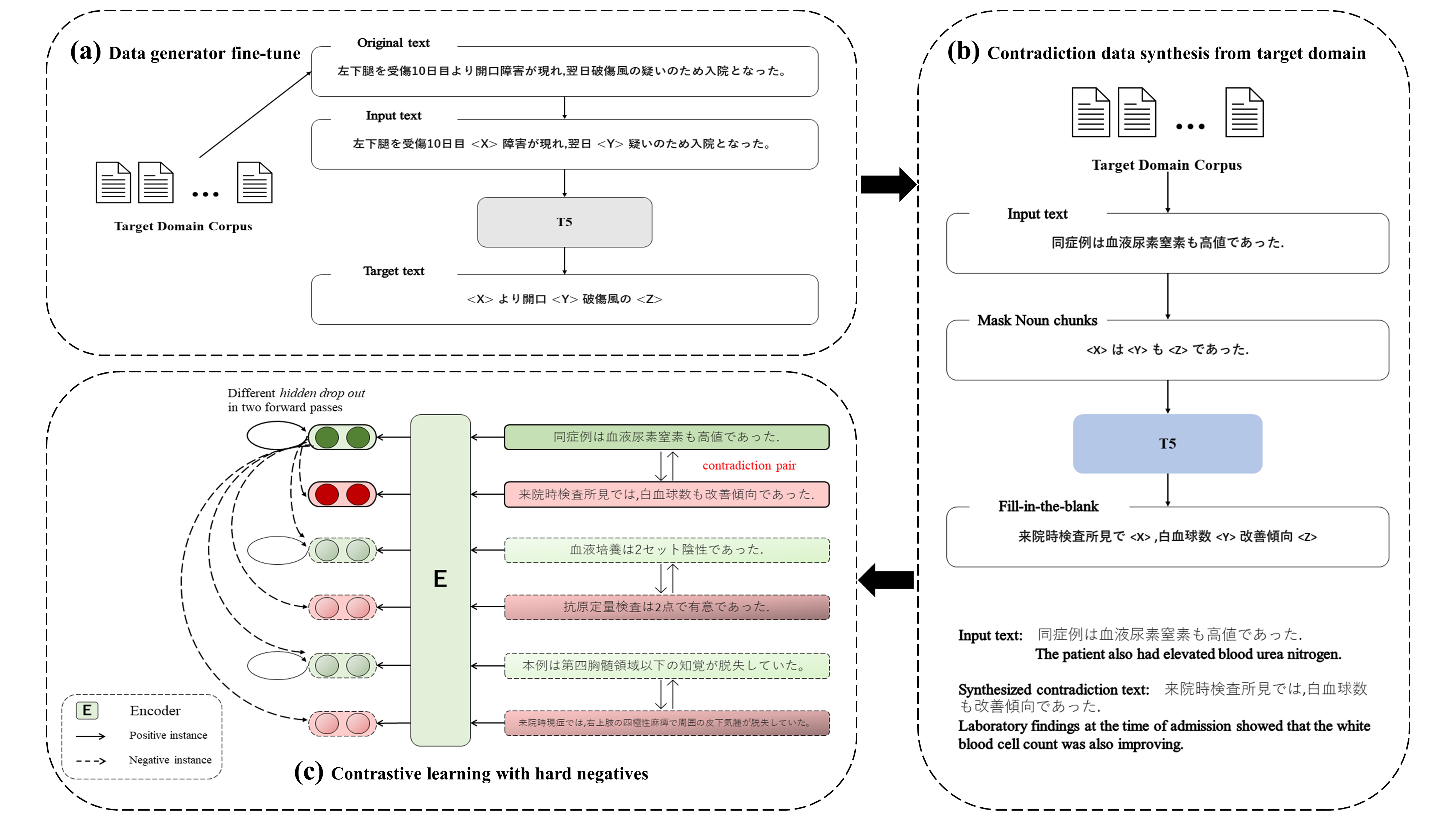
Contrastive learning is widely used for sentence representation learning. Despite this prevalence, most studies have focused exclusively on English and few concern domain adaptation for domain-specific downstream tasks, especially for low-resource languages like Japanese, which are characterized by insufficient target domain data and the lack of a proper training strategy. To overcome this, we propose a novel Japanese sentence representation framework, JCSE (derived from ``Contrastive learning of Sentence Embeddings for Japanese''), that creates training data by generating sentences and synthesizing them with sentences available in a target domain. Specifically, a pre-trained data generator is finetuned to a target domain using our collected corpus. It is then used to generate contradictory sentence pairs that are used in contrastive learning for adapting a Japanese language model to a specific task in the target domain. Another problem of Japanese sentence representation learning is the difficulty of evaluating existing embedding methods due to the lack of benchmark datasets. Thus, we establish a comprehensive Japanese Semantic Textual Similarity (STS) benchmark on which various embedding models are evaluated. Based on this benchmark result, multiple embedding methods are chosen and compared with JCSE on two domain-specific tasks, STS in a clinical domain and information retrieval in an educational domain. The results show that JCSE achieves significant performance improvement surpassing direct transfer and other training strategies. This empirically demonstrates JCSE's effectiveness and practicability for downstream tasks of a low-resource language.
翻译:尽管这种普遍现象,但大多数研究都只关注英语,很少关注特定领域下游任务的领域适应,特别是日本等低资源语言,其特点是目标域数据不足,缺乏适当的培训战略。要克服这一点,我们提议日本新颖的句号代表框架JCSE(来自“对日判刑嵌入的学习”日本语),它创造培训数据,生成判决,将其与目标域的刑期合并。具体地说,培训前数据生成器利用我们收集的材料对目标域进行微调,特别是日本语等低资源语言。然后,它被用来产生相互矛盾的句子配对,用于对比性学习,使日语模式适应目标域的具体任务。日本句号学习的另一个问题是,由于缺少基准数据集,难以评估现有的嵌入方法。因此,我们建立了一个全面的日语义文本相似性(STSE)基准基准,根据这一基准结果,选择了多种嵌入式方法,并与JSESE领域直接的学习成果转换。