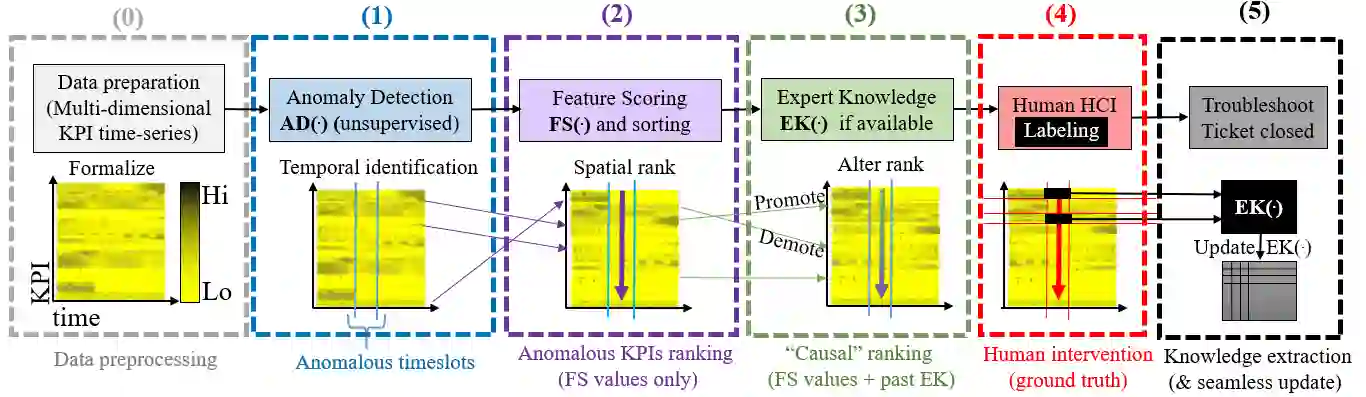
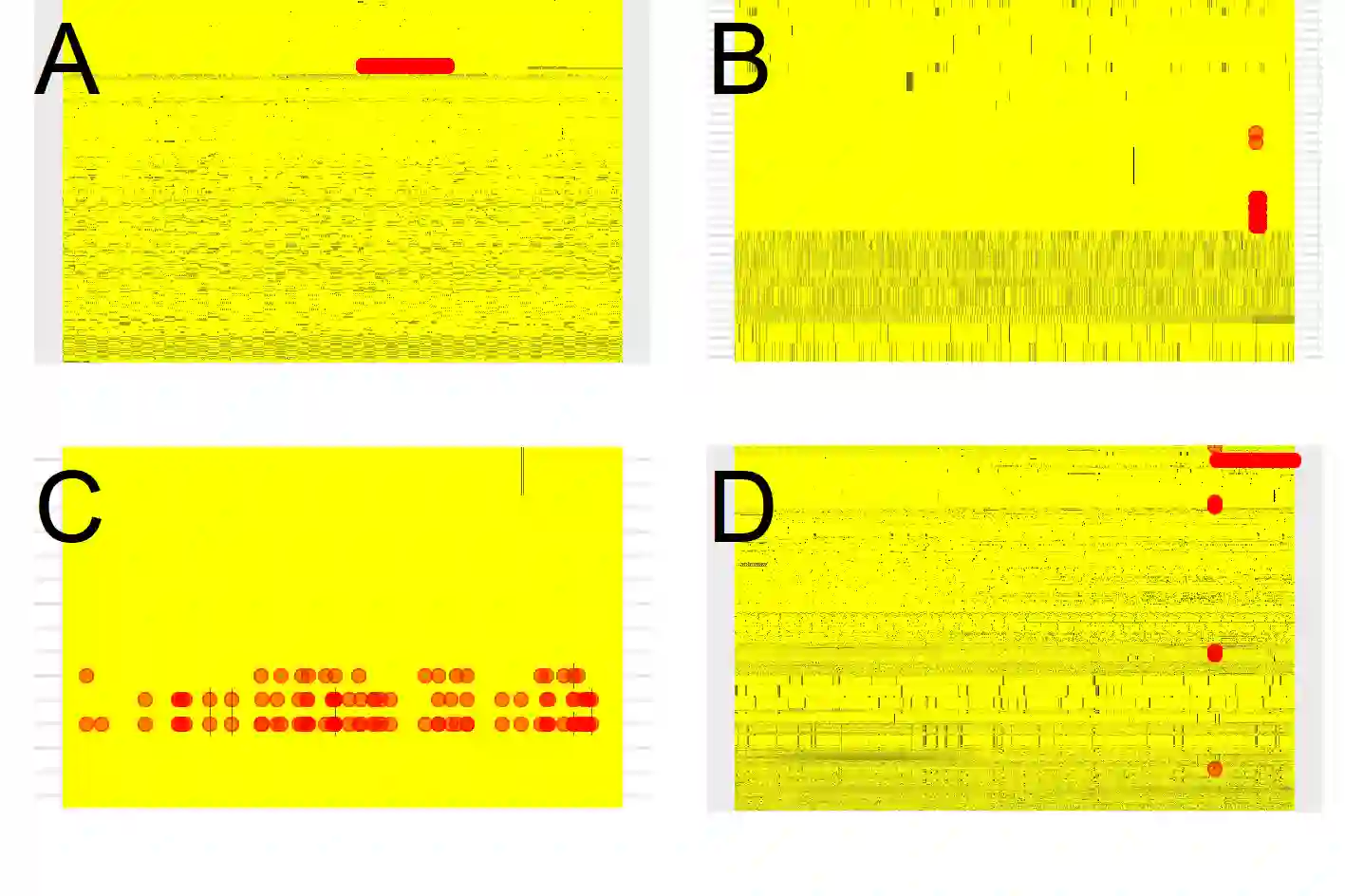
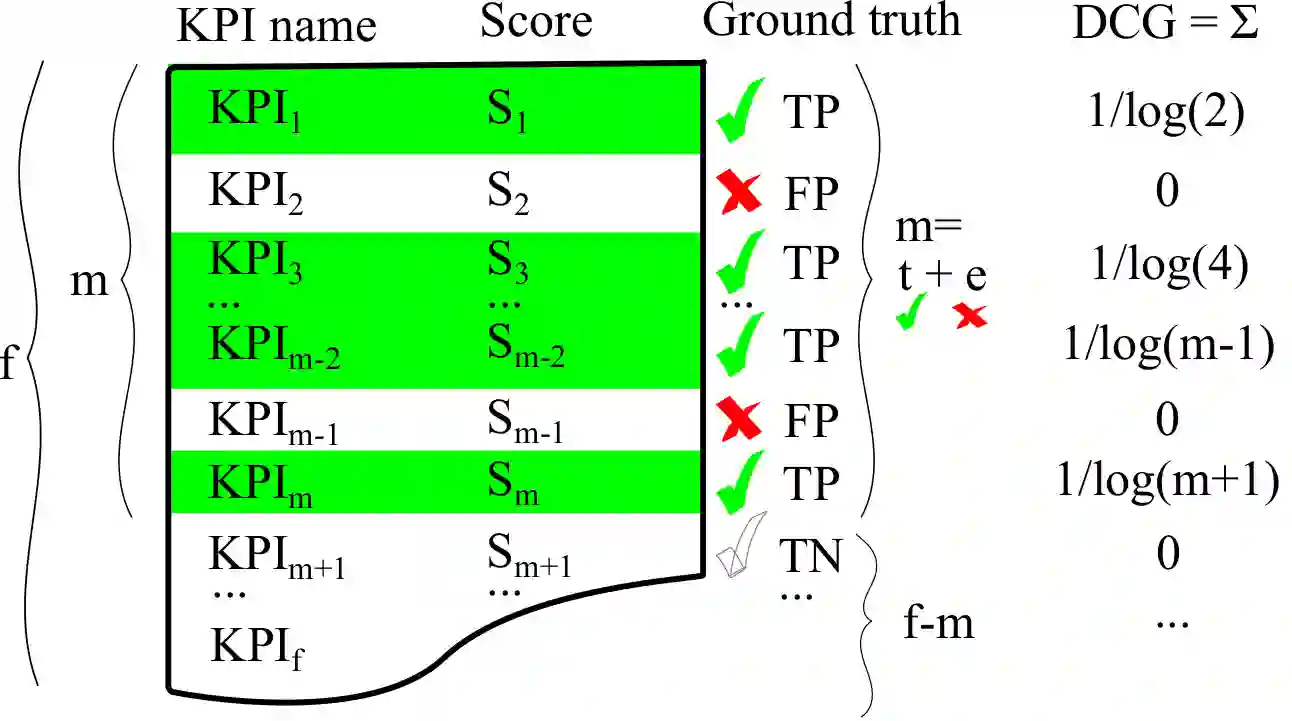
Network troubleshooting is still a heavily human-intensive process. To reduce the time spent by human operators in the diagnosis process, we present a system based on (i) unsupervised learning methods for detecting anomalies in the time domain, (ii) an attention mechanism to rank features in the feature space and finally (iii) an expert knowledge module able to seamlessly incorporate previously collected domain-knowledge. In this paper, we thoroughly evaluate the performance of the full system and of its individual building blocks: particularly, we consider (i) 10 anomaly detection algorithms as well as (ii) 10 attention mechanisms, that comprehensively represent the current state of the art in the respective fields. Leveraging a unique collection of expert-labeled datasets worth several months of real router telemetry data, we perform a thorough performance evaluation contrasting practical results in constrained stream-mode settings, with the results achievable by an ideal oracle in academic settings. Our experimental evaluation shows that (i) the proposed system is effective in achieving high levels of agreement with the expert, and (ii) that even a simple statistical approach is able to extract useful information from expert knowledge gained in past cases, significantly improving troubleshooting performance.
翻译:为了减少人类操作者在诊断过程中花费的时间,我们提出了一个系统,其基础是:(一) 在时间域内发现异常现象的未经监督的学习方法,(二) 注意地物空间的排位机制,以及(三) 能够无缝地纳入先前收集的域知识的专家知识模块。在本文件中,我们彻底评估了整个系统及其各个构件的性能:特别是,我们认为(一) 10个异常检测算法和(二) 10个关注机制,它们全面反映了各个领域的最新技术。利用专家标签数据集的独特收集,价值数月实际路由仪遥测数据,我们进行了彻底的业绩评估,对比了在受限制的流体模型环境中的实际结果,其结果由学术环境中的理想信箱所实现。我们的实验评估表明,(一) 拟议的系统在与专家达成高度协议方面是有效的,以及(二) 即使是简单的统计方法也能从以往案例获得的专家知识中提取有用的信息,大大地改进了故障。