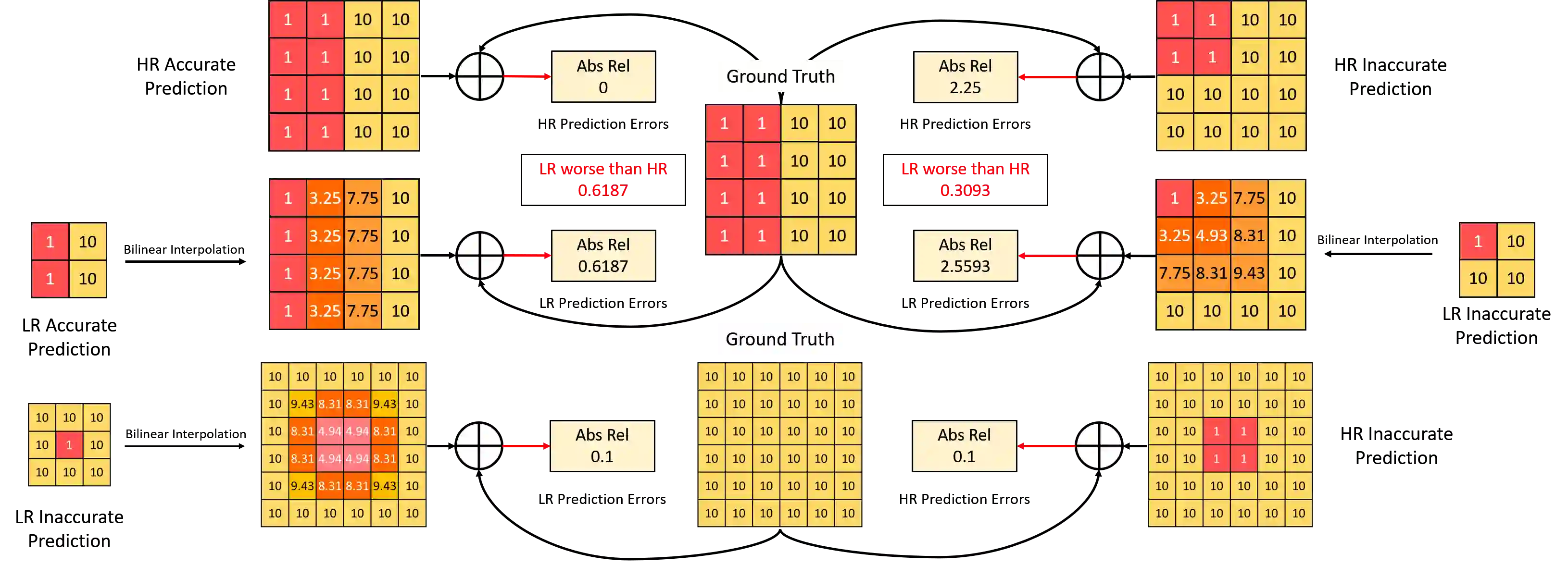
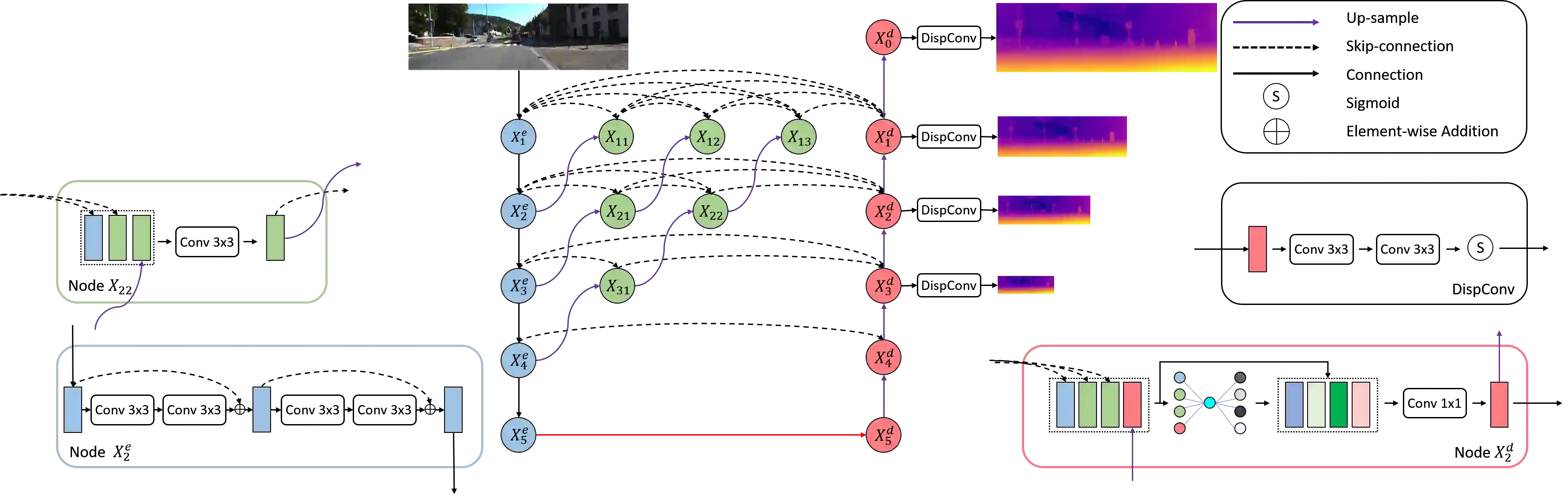
Self-supervised learning shows great potential in monoculardepth estimation, using image sequences as the only source ofsupervision. Although people try to use the high-resolutionimage for depth estimation, the accuracy of prediction hasnot been significantly improved. In this work, we find thecore reason comes from the inaccurate depth estimation inlarge gradient regions, making the bilinear interpolation er-ror gradually disappear as the resolution increases. To obtainmore accurate depth estimation in large gradient regions, itis necessary to obtain high-resolution features with spatialand semantic information. Therefore, we present an improvedDepthNet, HR-Depth, with two effective strategies: (1) re-design the skip-connection in DepthNet to get better high-resolution features and (2) propose feature fusion Squeeze-and-Excitation(fSE) module to fuse feature more efficiently.Using Resnet-18 as the encoder, HR-Depth surpasses all pre-vious state-of-the-art(SoTA) methods with the least param-eters at both high and low resolution. Moreover, previousstate-of-the-art methods are based on fairly complex and deepnetworks with a mass of parameters which limits their realapplications. Thus we also construct a lightweight networkwhich uses MobileNetV3 as encoder. Experiments show thatthe lightweight network can perform on par with many largemodels like Monodepth2 at high-resolution with only20%parameters. All codes and models will be available at https://github.com/shawLyu/HR-Depth.
翻译:自我监督的学习在单眼深度估算中显示出巨大的潜力, 使用图像序列作为唯一的监督源。 虽然人们试图使用高分辨率图像进行深度估算, 但预测的准确性并没有显著提高。 在这项工作中, 我们发现核心原因来自大梯度区域的不准确深度估算, 使得双线内插ER- r 或随着分辨率的增加而逐渐消失。 在大梯度区域, 要获得更准确的深度估算, 就必须用空间和语义信息获得高分辨率特征。 因此, 我们提出改进的DepehNet, HR- Depeh, 有两种有效的战略:(1) 重新设计深度网络中的跳接头连接, 以获得更好的高分辨率特征, 并且(2) 提出在大梯度地区进行不准确的深度估算, 使双线性内插和Exucation(fESe) 模块更高效地消失。 HR- Depeh 在大梯度区域获得更准确的深度估算时, 需要获得更准确的深度空间和语义信息。 因此, HR- Dept, 和低分辨率解分解两种方法都具有最低的准性。 。 此外的网络模型, 将大量的网络使用。