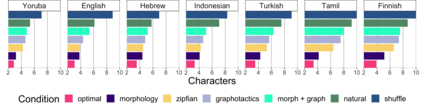
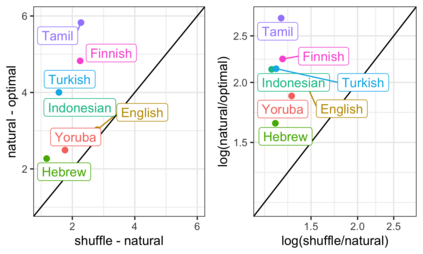
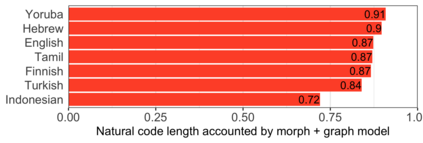
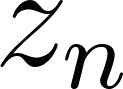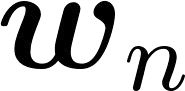The mapping of lexical meanings to wordforms is a major feature of natural languages. While usage pressures might assign short words to frequent meanings (Zipf's law of abbreviation), the need for a productive and open-ended vocabulary, local constraints on sequences of symbols, and various other factors all shape the lexicons of the world's languages. Despite their importance in shaping lexical structure, the relative contributions of these factors have not been fully quantified. Taking a coding-theoretic view of the lexicon and making use of a novel generative statistical model, we define upper bounds for the compressibility of the lexicon under various constraints. Examining corpora from 7 typologically diverse languages, we use those upper bounds to quantify the lexicon's optimality and to explore the relative costs of major constraints on natural codes. We find that (compositional) morphology and graphotactics can sufficiently account for most of the complexity of natural codes -- as measured by code length.
翻译:文字形状的词汇含义绘图是自然语言的一个主要特征。虽然使用压力可能将短词划为常用词(Zipf的缩写法),但需要有一个有成果的、开放的词汇、对符号序列的当地限制以及各种其他因素,这些因素都决定了世界语言的词汇。尽管这些因素在形成词汇结构方面很重要,但这些因素的相对贡献尚未充分量化。用对词汇的编码理论观点和使用新的基因化统计模型,我们界定了在各种限制下可压缩词汇的上界。我们从7种类型多样的语言中研究公司,我们利用这些上界来量化词汇的最佳性,并探讨自然代码主要制约的相对成本。我们发现(组合)形态学和图形学可以充分说明自然代码的多数复杂性,按代码长度来衡量。