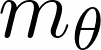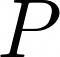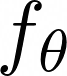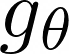Video question answering (VideoQA) is a complex task that requires diverse multi-modal data for training. Manual annotation of question and answers for videos, however, is tedious and prohibits scalability. To tackle this problem, recent methods consider zero-shot settings with no manual annotation of visual question-answer. In particular, a promising approach adapts frozen autoregressive language models pretrained on Web-scale text-only data to multi-modal inputs. In contrast, we here build on frozen bidirectional language models (BiLM) and show that such an approach provides a stronger and cheaper alternative for zero-shot VideoQA. In particular, (i) we combine visual inputs with the frozen BiLM using light trainable modules, (ii) we train such modules using Web-scraped multi-modal data, and finally (iii) we perform zero-shot VideoQA inference through masked language modeling, where the masked text is the answer to a given question. Our proposed approach, FrozenBiLM, outperforms the state of the art in zero-shot VideoQA by a significant margin on a variety of datasets, including LSMDC-FiB, iVQA, MSRVTT-QA, MSVD-QA, ActivityNet-QA, TGIF-FrameQA, How2QA and TVQA. It also demonstrates competitive performance in the few-shot and fully-supervised setting. Our code and models will be made publicly available at https://antoyang.github.io/frozenbilm.html.
翻译:视频解答( VideoQA ) 是一项复杂的任务,需要多种多模式的培训数据。 但是,对视频的问答进行人工说明是乏味的,禁止可缩放性。 为了解决这个问题,最近的方法考虑到零点设置,而没有手工解答视觉解答。特别是,一种有希望的方法将预先在网络规模的纯文本数据上训练的冻结的自动反向语言模型改造为多模式输入。相比之下,我们在这里建立冻结的双向双向语言模型(BILM ), 并表明这种方法为零弹射视频QA提供了更强、更便宜的替代方案。 特别是, (一) 我们使用轻度培训模块将视觉输入与冻结的BILMM(零点) 组合在一起, (二) 我们通过掩码语言模型执行零点视频QA( 掩码), 我们提议的我们的方法、 FrozenBLMM(FA) 超越了SQQQ( QA-QA) 的状态, 以零点A-SFA(O-DA-VA-D) QA( Q) AS-VA(O-VA) Q) QA(O-SD) Q) 和以显著的版本的版本的版本数据展示, 将展示一个重要版本的版本的图像(O-SF-SF-F-SD(OFA) ) QA-SD(O) 、 ) ) 的版本的版本数据展示一个重要的版本的版本的版本的版本的版本的版本的版本的版本的版本数据。