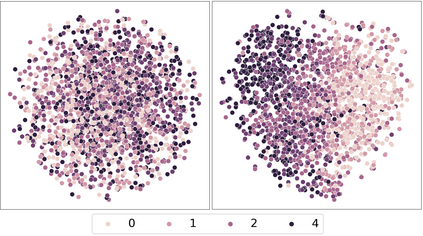
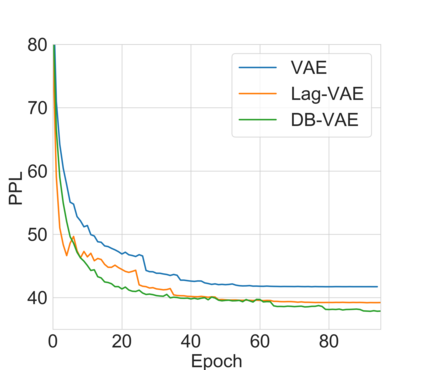
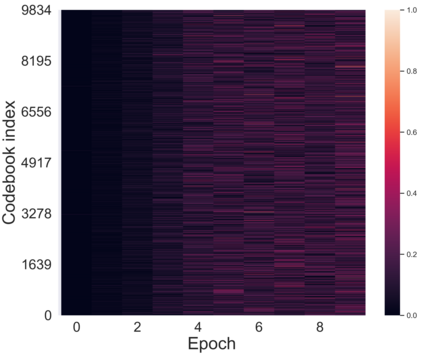
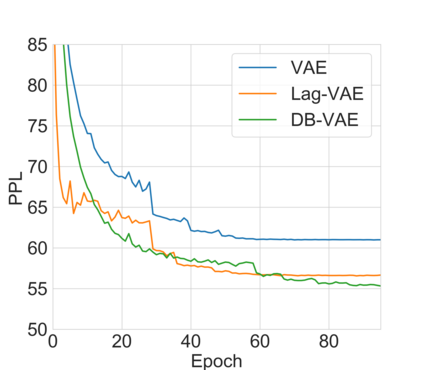
Variational autoencoders (VAEs) are essential tools in end-to-end representation learning. However, the sequential text generation common pitfall with VAEs is that the model tends to ignore latent variables with a strong auto-regressive decoder. In this paper, we propose a principled approach to alleviate this issue by applying a discretized bottleneck to enforce an implicit latent feature matching in a more compact latent space. We impose a shared discrete latent space where each input is learned to choose a combination of latent atoms as a regularized latent representation. Our model endows a promising capability to model underlying semantics of discrete sequences and thus provide more interpretative latent structures. Empirically, we demonstrate our model's efficiency and effectiveness on a broad range of tasks, including language modeling, unaligned text style transfer, dialog response generation, and neural machine translation.
翻译:变化式自动编码器(VAEs)是端到端代表学习的必要工具。然而,相继生成的文本在 VAEs 中常见的陷阱是,该模型倾向于忽略潜在变量,而其自动递增式解码器则很强。在本文中,我们提出一个原则性方法来缓解这一问题,在更紧凑的潜伏空间实施隐含的潜在特征匹配。我们设置了一个共享的离散潜伏空间,让每个输入都学会将潜在原子组合为正规化的潜在代表。我们的模型赋予了一种很有希望的能力,可以模拟离散序列的语义,从而提供更清晰的潜伏结构。我们很生动地展示了我们模型在广泛任务方面的效率和效力,包括语言建模、不统一的文本风格传输、对话生成和神经机翻译。