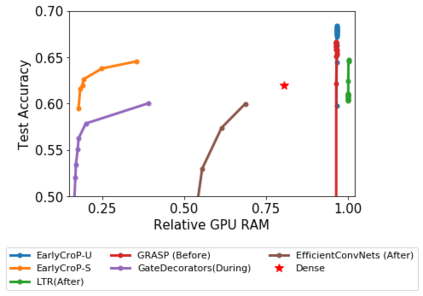
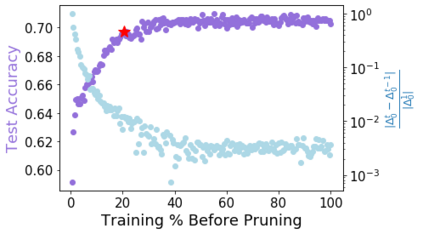
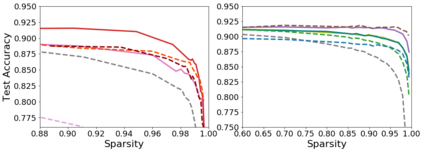
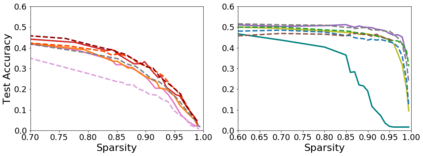
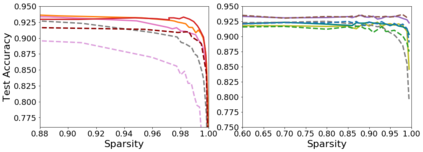
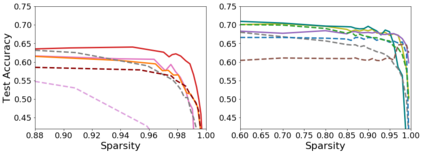
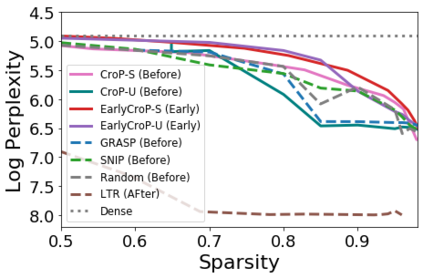
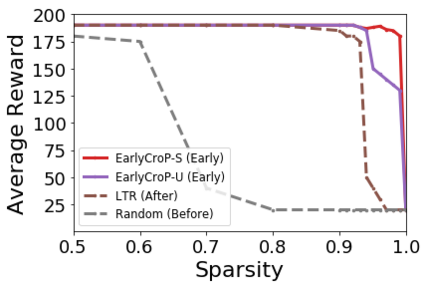
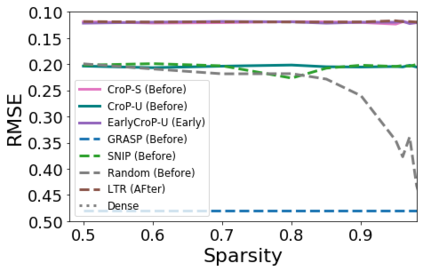
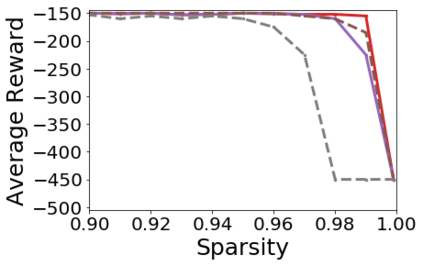
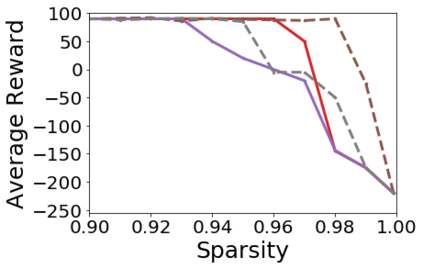
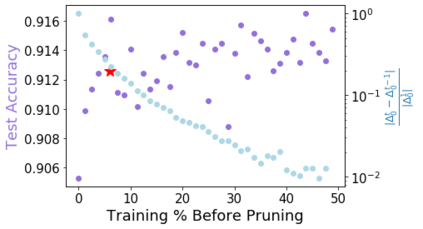
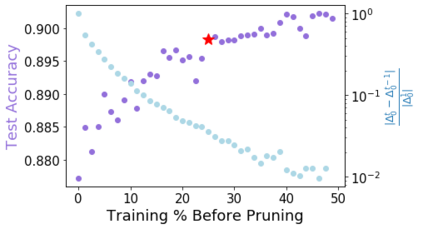
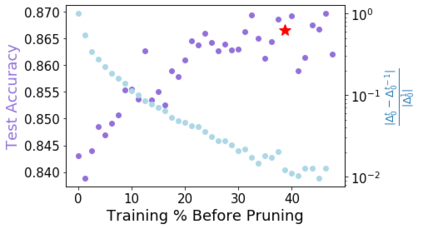
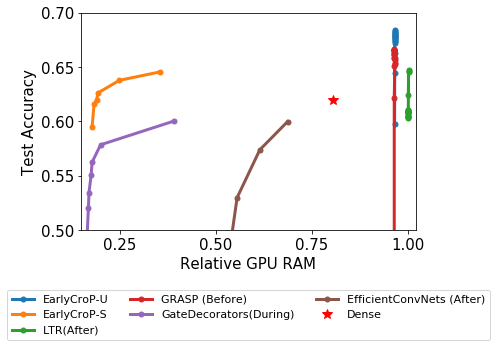
Pruning, the task of sparsifying deep neural networks, received increasing attention recently. Although state-of-the-art pruning methods extract highly sparse models, they neglect two main challenges: (1) the process of finding these sparse models is often very expensive; (2) unstructured pruning does not provide benefits in terms of GPU memory, training time, or carbon emissions. We propose Early Compression via Gradient Flow Preservation (EarlyCroP), which efficiently extracts state-of-the-art sparse models before or early in training addressing challenge (1), and can be applied in a structured manner addressing challenge (2). This enables us to train sparse networks on commodity GPUs whose dense versions would be too large, thereby saving costs and reducing hardware requirements. We empirically show that EarlyCroP outperforms a rich set of baselines for many tasks (incl. classification, regression) and domains (incl. computer vision, natural language processing, and reinforcment learning). EarlyCroP leads to accuracy comparable to dense training while outperforming pruning baselines.
翻译:最近人们日益关注深层神经网络的封闭性工作。尽管最先进的裁剪方法吸引了高度稀少的模式,但它们忽视了两大挑战:(1) 寻找这些稀有模式的过程往往非常昂贵;(2) 无结构的剪裁在 GPU 记忆、培训时间或碳排放方面没有带来好处。我们提议通过 " 梯流保护 " (EarlyCroP) 进行早期压缩,这在培训应对挑战(1)之前或培训初期有效地提取了最先进的稀有模式,并且可以有条不紊地应用这些模式应对挑战(2) 。这使我们能够对稀有的商品的GPUPS 进行培训,这些商品的密集版本会太大,从而节省成本并减少硬件需求。我们从经验上表明, " 早期CroP " 超越了许多任务(包括分类、回归)和领域(包括计算机视野、自然语言处理和再配置学习)的丰富基线。早期CroP 导致精准性与密集培训相比,同时不能运行基线。