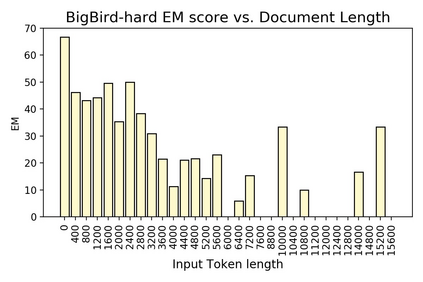
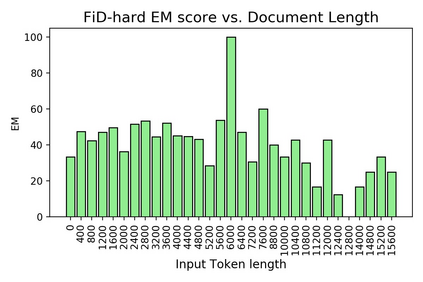
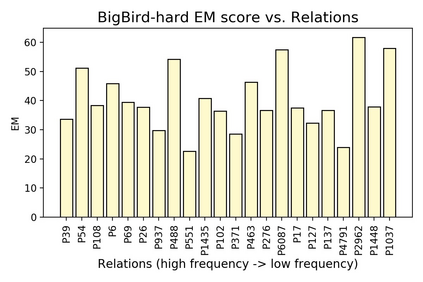
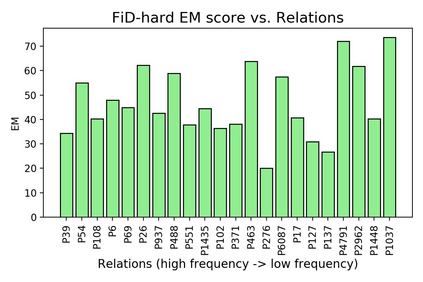
Time is an important dimension in our physical world. Lots of facts can evolve with respect to time. For example, the U.S. President might change every four years. Therefore, it is important to consider the time dimension and empower the existing QA models to reason over time. However, the existing QA datasets contain rather few time-sensitive questions, hence not suitable for diagnosing or benchmarking the model's temporal reasoning capability. In order to promote research in this direction, we propose to construct a time-sensitive QA dataset. The dataset is constructed by 1) mining time-evolving facts from WikiData and align them to their corresponding Wikipedia page, 2) employing crowd workers to verify and calibrate these noisy facts, 3) generating question-answer pairs based on the annotated time-sensitive facts. Our dataset poses challenges in the aspect of both temporal understanding and temporal reasoning. We evaluate different SoTA long-document QA systems like BigBird and FiD on our dataset. The best-performing model FiD can only achieve 46\% accuracy, still far behind the human performance of 87\%. We demonstrate that these models are still lacking the ability to perform consistent temporal reasoning. Therefore, we believe that our dataset could serve as a benchmark to develop NLP models more sensitive to temporal shift. The dataset and code are released in~\url{https://github.com/wenhuchen/Time-Sensitive-QA}.
翻译:时间是我们物理世界的一个重要维度。 许多事实可以随着时间变化而演变。 例如, 美国总统可能每四年改变一次。 因此, 重要的是要考虑时间维度, 并赋予现有的QA模型在一段时间里能够理解。 然而, 现有的QA数据集包含一些时间敏感问题, 因而不适合对模型的时间推理能力进行诊断或基准。 为了促进这方面的研究, 我们提议构建一个时间敏感的QA数据集 。 数据集的构建方式是:(1) 从 WikiData 挖掘时间变化的事实, 并将它们与相应的WikiData 页面相匹配。 因此, 重要的是要考虑时间维基Data 的时间维基百科层面, 并赋予现有QA 模型的能力, 核实和校准这些噪音事实, 3 产生基于附加时间敏感事实的问答配对。 我们的数据集在时间理解和时间推理两方面都提出了挑战。 我们评估不同的 SoTA 长的 QA 系统, 比如 Bigbird 和 FiD 。 最佳的FID 只能达到46 ⁇ 准确性。, 仍然远远落后于87- QQ- 的人类业绩的运行, 2) 和 NAlma- 的模型, 我们坚信 的时标定的模型是持续的推 。