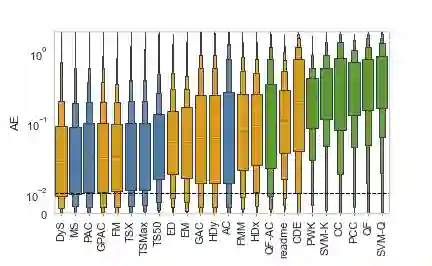
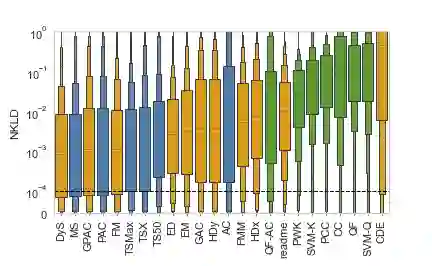
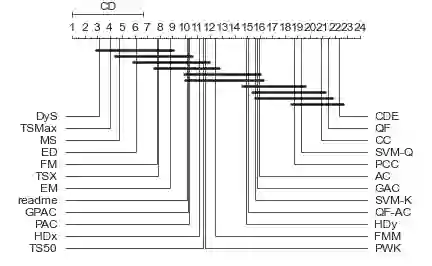
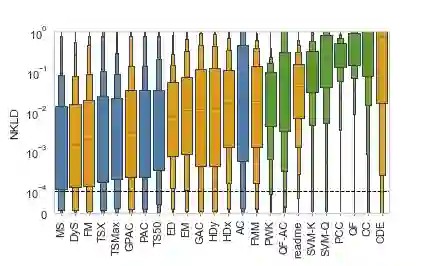
Quantification represents the problem of predicting class distributions in a given target set. It also represents a growing research field in supervised machine learning, for which a large variety of different algorithms has been proposed in recent years. However, a comprehensive empirical comparison of quantification methods that supports algorithm selection is not available yet. In this work, we close this research gap by conducting a thorough empirical performance comparison of 24 different quantification methods. To consider a broad range of different scenarios for binary as well as multiclass quantification settings, we carried out almost 3 million experimental runs on 40 data sets. We observe that no single algorithm generally outperforms all competitors, but identify a group of methods including the Median Sweep and the DyS framework that perform significantly better in binary settings. For the multiclass setting, we observe that a different, broad group of algorithms yields good performance, including the Generalized Probabilistic Adjusted Count, the readme method, the energy distance minimization method, the EM algorithm for quantification, and Friedman's method. More generally, we find that the performance on multiclass quantification is inferior to the results obtained in the binary setting. Our results can guide practitioners who intend to apply quantification algorithms and help researchers to identify opportunities for future research.
翻译:量化代表了在特定目标集中预测类分布的问题。 它还代表了监督机器学习中日益扩大的研究领域,近年来已经为此提出了各种不同的算法。然而,还没有对支持算法选择的量化方法进行全面的经验比较。在这项工作中,我们通过对24种不同的量化方法进行彻底的经验性业绩比较来缩小研究差距。为了考虑二进制和多级量化设置的各种不同情景,我们在40个数据集上进行了近300万个实验运行。我们发现,没有任何一种单一算法普遍优于所有竞争者,而是确定了一组方法,包括中流线扫描和DyS框架,在二进制环境中表现要好得多。对于多级设置,我们观察到,不同的、广泛的算法组合产生良好的性能,包括通用的概率调整计数、读数方法、能源距离最小化方法、计量的EM算法和弗里德曼方法。更一般地说,我们发现,在多级量化方面的绩效低于在二进制环境中取得的结果。我们的研究成果可以用来指导未来的研究人员确定量化机会。