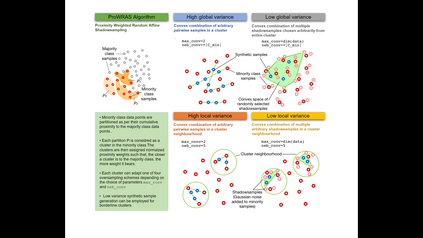
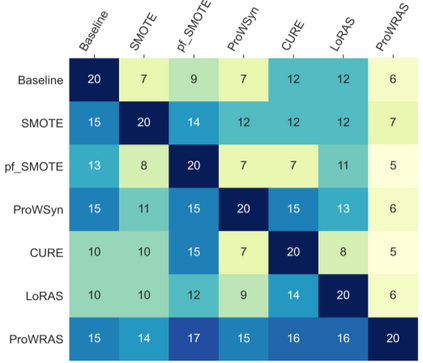
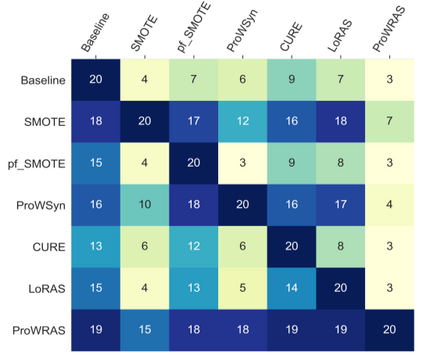
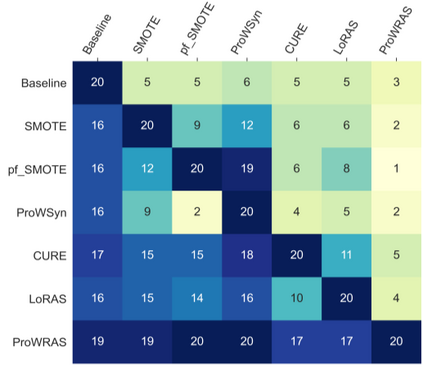
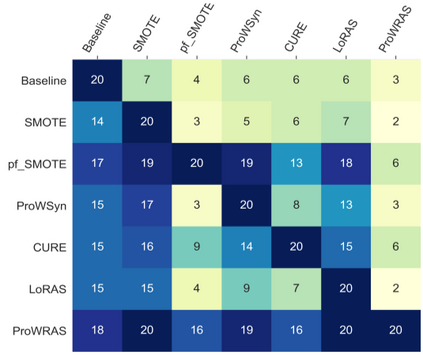
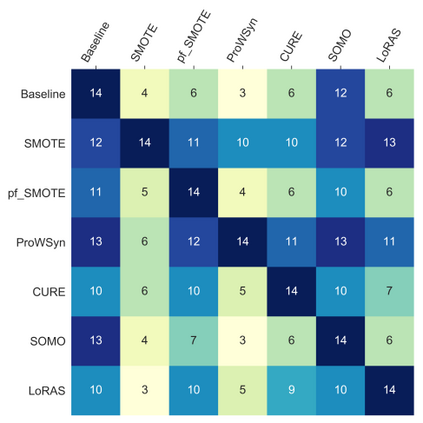
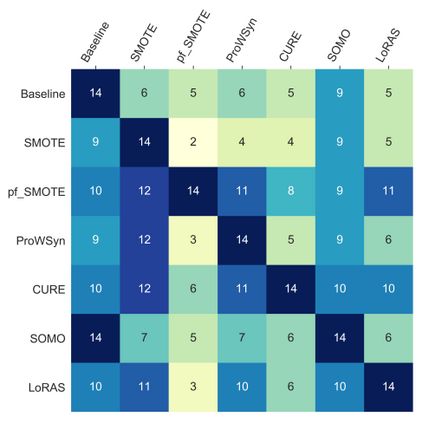
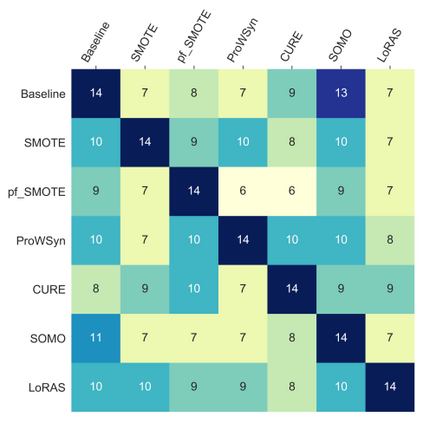
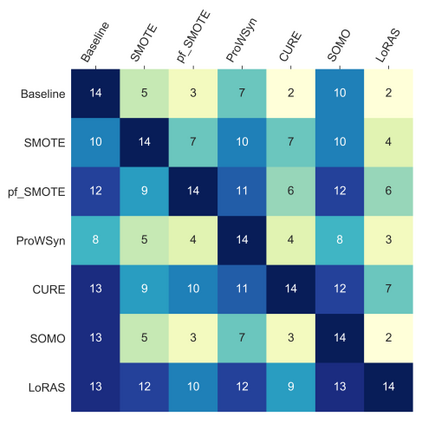
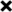Over 85 oversampling algorithms, mostly extensions of the SMOTE algorithm, have been built over the past two decades, to solve the problem of imbalanced datasets. However, it has been evident from previous studies that different oversampling algorithms have different degrees of efficiency with different classifiers. With numerous algorithms available, it is difficult to decide on an oversampling algorithm for a chosen classifier. Here, we overcome this problem with a multi-schematic and classifier-independent oversampling approach: ProWRAS(Proximity Weighted Random Affine Shadowsampling). ProWRAS integrates the Localized Random Affine Shadowsampling (LoRAS)algorithm and the Proximity Weighted Synthetic oversampling (ProWSyn) algorithm. By controlling the variance of the synthetic samples, as well as a proximity-weighted clustering system of the minority classdata, the ProWRAS algorithm improves performance, compared to algorithms that generate synthetic samples through modelling high dimensional convex spaces of the minority class. ProWRAS has four oversampling schemes, each of which has its unique way to model the variance of the generated data. Most importantly, the performance of ProWRAS with proper choice of oversampling schemes, is independent of the classifier used. We have benchmarked our newly developed ProWRAS algorithm against five sate-of-the-art oversampling models and four different classifiers on 20 publicly available datasets. ProWRAS outperforms other oversampling algorithms in a statistically significant way, in terms of both F1-score and Kappa-score. Moreover, we have introduced a novel measure for classifier independence I-score, and showed quantitatively that ProWRAS performs better, independent of the classifier used. In practice, ProWRAS customizes synthetic sample generation according to a classifier of choice and thereby reduces benchmarking efforts.
翻译:超过85个过度抽样算法, 主要是SMOTE算法的延伸, 过去二十年已经建立起来, 以解决不平衡的数据集问题。 然而, 从以前的研究中可以明显看出, 不同的过度抽样算法与不同的分类者具有不同的效率程度。 有了众多的算法, 我们很难决定为所选的分类者建立过度抽样算法。 在这里, 我们克服了这个问题, 我们采用了一个多层次和分类的过度抽样抽样法: ProWRAS( 快速加权随机瞬间暗影抽样抽样调查) 。 ProRWAS 整合了本地化的 Rent Affacter 暗影采样( LoRAS) 和 超精度混合的合成算法。 ProWRAS 使用了不同比例的混血算法 。 控制合成样本的差异, 以及少数群体类数据的近身组集集集, ProRWAS 算法( ProWRAS) 提高了现有合成样本的性能, 通过模拟高维度的超度分式模拟系统, 也使用了四种不同的数据基数 。