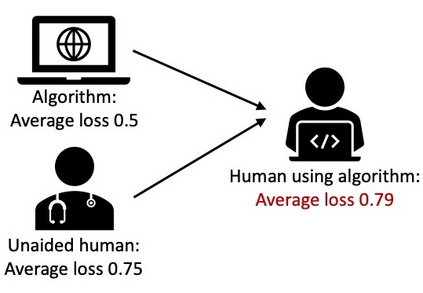
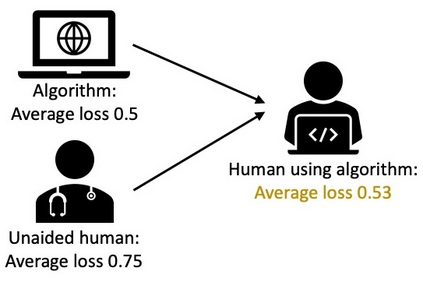
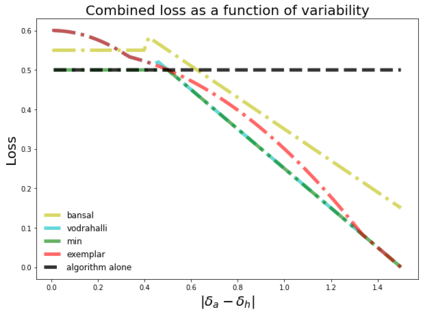
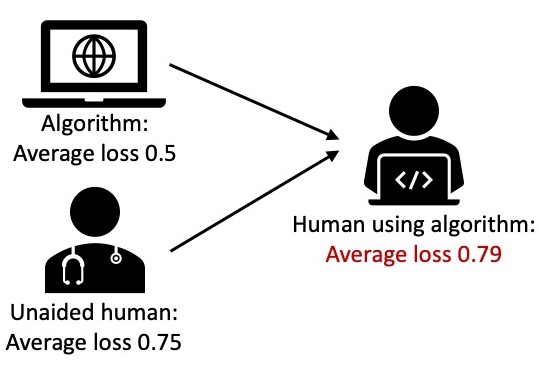
Much of machine learning research focuses on predictive accuracy: given a task, create a machine learning model (or algorithm) that maximizes accuracy. In many settings, however, the final prediction or decision of a system is under the control of a human, who uses an algorithm's output along with their own personal expertise in order to produce a combined prediction. One ultimate goal of such collaborative systems is "complementarity": that is, to produce lower loss (equivalently, greater payoff or utility) than either the human or algorithm alone. However, experimental results have shown that even in carefully-designed systems, complementary performance can be elusive. Our work provides three key contributions. First, we provide a theoretical framework for modeling simple human-algorithm systems and demonstrate that multiple prior analyses can be expressed within it. Next, we use this model to prove conditions where complementarity is impossible, and give constructive examples of where complementarity is achievable. Finally, we discuss the implications of our findings, especially with respect to the fairness of a classifier. In sum, these results deepen our understanding of key factors influencing the combined performance of human-algorithm systems, giving insight into how algorithmic tools can best be designed for collaborative environments.
翻译:机器学习的大部分研究都集中在预测准确性上:给一个任务,创建一个机器学习模型(或算法),使准确性最大化。然而,在许多环境中,一个系统的最后预测或决定是由一个人控制的,他利用算法的产出和他们自己的个人专门知识来作出综合预测。这种合作系统的最终目标之一是“互补性”即产生比人类或算法本身低的损失(相等、更大的回报或效用),然而,实验结果表明,即使在精心设计的系统中,互补性能也是难以实现的。我们的工作提供了三个主要贡献。首先,我们为模拟简单的人-负数系统提供了一个理论框架,并表明可以在此范围内进行多次先前的分析。接下来,我们利用这个模型来证明不可能互补的条件,并给出可以实现互补的建设性例子。最后,我们讨论了我们发现的影响,特别是归正者的公正性。总而言,这些结果加深了我们对影响人类-负数系统综合性能的关键因素的理解,对合作性工具是如何设计最佳环境的洞察力。