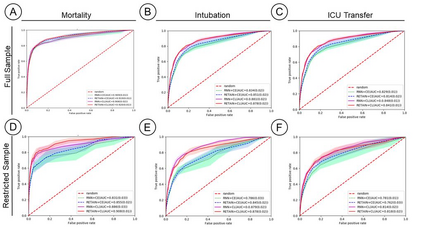
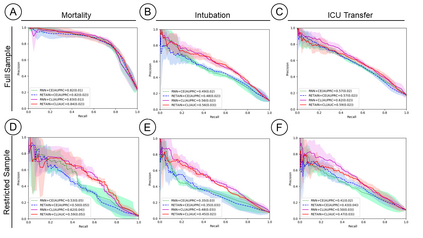
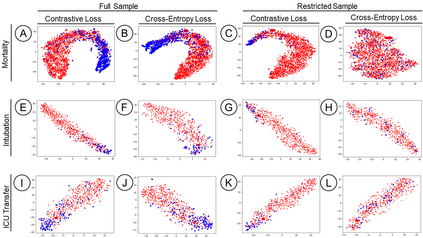
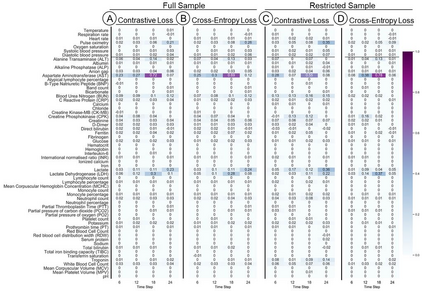
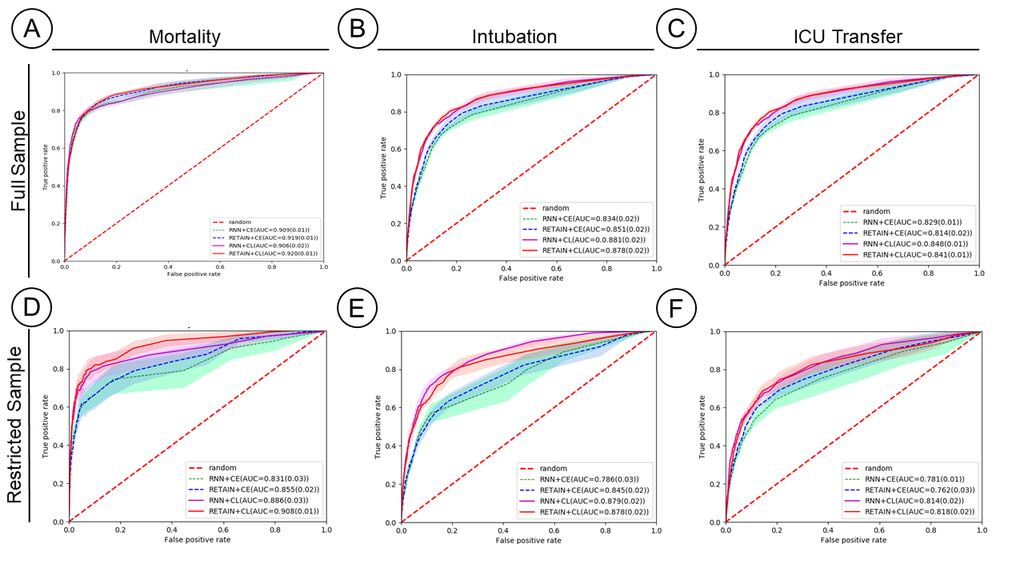
Machine Learning (ML) models typically require large-scale, balanced training data to be robust, generalizable, and effective in the context of healthcare. This has been a major issue for developing ML models for the coronavirus-disease 2019 (COVID-19) pandemic where data is highly imbalanced, particularly within electronic health records (EHR) research. Conventional approaches in ML use cross-entropy loss (CEL) that often suffers from poor margin classification. For the first time, we show that contrastive loss (CL) improves the performance of CEL especially for imbalanced EHR data and the related COVID-19 analyses. This study has been approved by the Institutional Review Board at the Icahn School of Medicine at Mount Sinai. We use EHR data from five hospitals within the Mount Sinai Health System (MSHS) to predict mortality, intubation, and intensive care unit (ICU) transfer in hospitalized COVID-19 patients over 24 and 48 hour time windows. We train two sequential architectures (RNN and RETAIN) using two loss functions (CEL and CL). Models are tested on full sample data set which contain all available data and restricted data set to emulate higher class imbalance.CL models consistently outperform CEL models with the restricted data set on these tasks with differences ranging from 0.04 to 0.15 for AUPRC and 0.05 to 0.1 for AUROC. For the restricted sample, only the CL model maintains proper clustering and is able to identify important features, such as pulse oximetry. CL outperforms CEL in instances of severe class imbalance, on three EHR outcomes with respect to three performance metrics: predictive power, clustering, and feature importance. We believe that the developed CL framework can be expanded and used for EHR ML work in general.
翻译:机械学习(ML)模型通常需要大规模、均衡的培训数据,以便稳健、可概括和有效地进行卫生保健工作。这是在2019年科诺纳病毒疾病(COVID-19)大流行中,数据高度失衡,特别是在电子健康记录(EHR)研究中,数据高度失衡的2019年科诺纳病毒疾病(COVID-19)大流行中,开发ML模型的主要问题。ML的常规方法使用经常遭受差差幅分类的跨肾损失(CEL)模型。我们第一次显示,对比损失(CL)提高了CEL的性能,特别是在不平衡的EHR数据和相关的COVID-19分析方面。这项研究得到了西奈山Icah医学院机构审查理事会的批准。我们使用Sinai山保健系统(MSHS)五家医院的EHR数据来预测死亡率、摄氏体损失(CUL)和强化护理单位(IC)的转移通常24小时以上和48小时以上时间窗口。我们用两项损失功能(CEL和CVIN)来培训两个序列结构(RNUD和REAN)的功能增强的功能(C和CVD1919)分析。模型用C的模型来不断测试的E(CRL)的E值变缩缩变缩数据,这些模型用于C的C的C。在C的模型中,这些模型中,这些模型的CRBRML的模型的精确数据显示的精确数据,这些模型的精确数据,这些模型的精确数据是用来用来在C的精确数据,用来在CRBRML的完整数据中,这些模型和CRBRDRDRDR的精确数据中,这些模型的精确数据中,这些模型的完整数据是用来对C的完整数据,用来对C的精确的完整的模型的精确的精确的精确的精确数据,用来的精确的精确的精确的模型的模型的模型的精确的精确的模型的模型的精确数据。