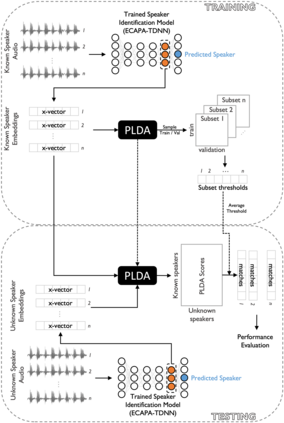
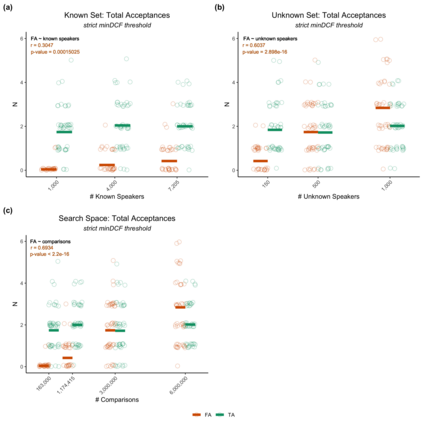
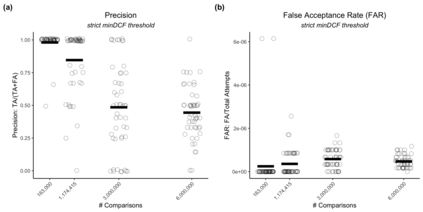
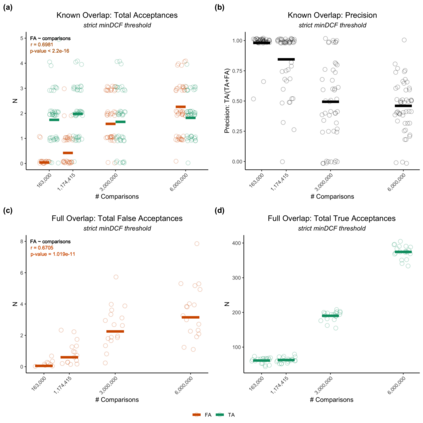
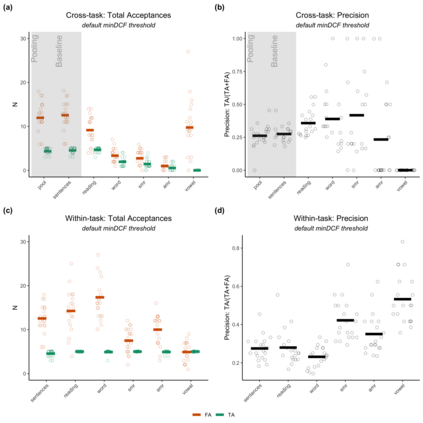
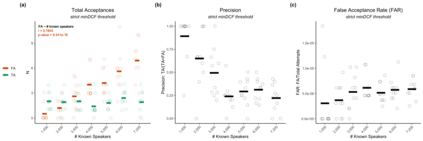
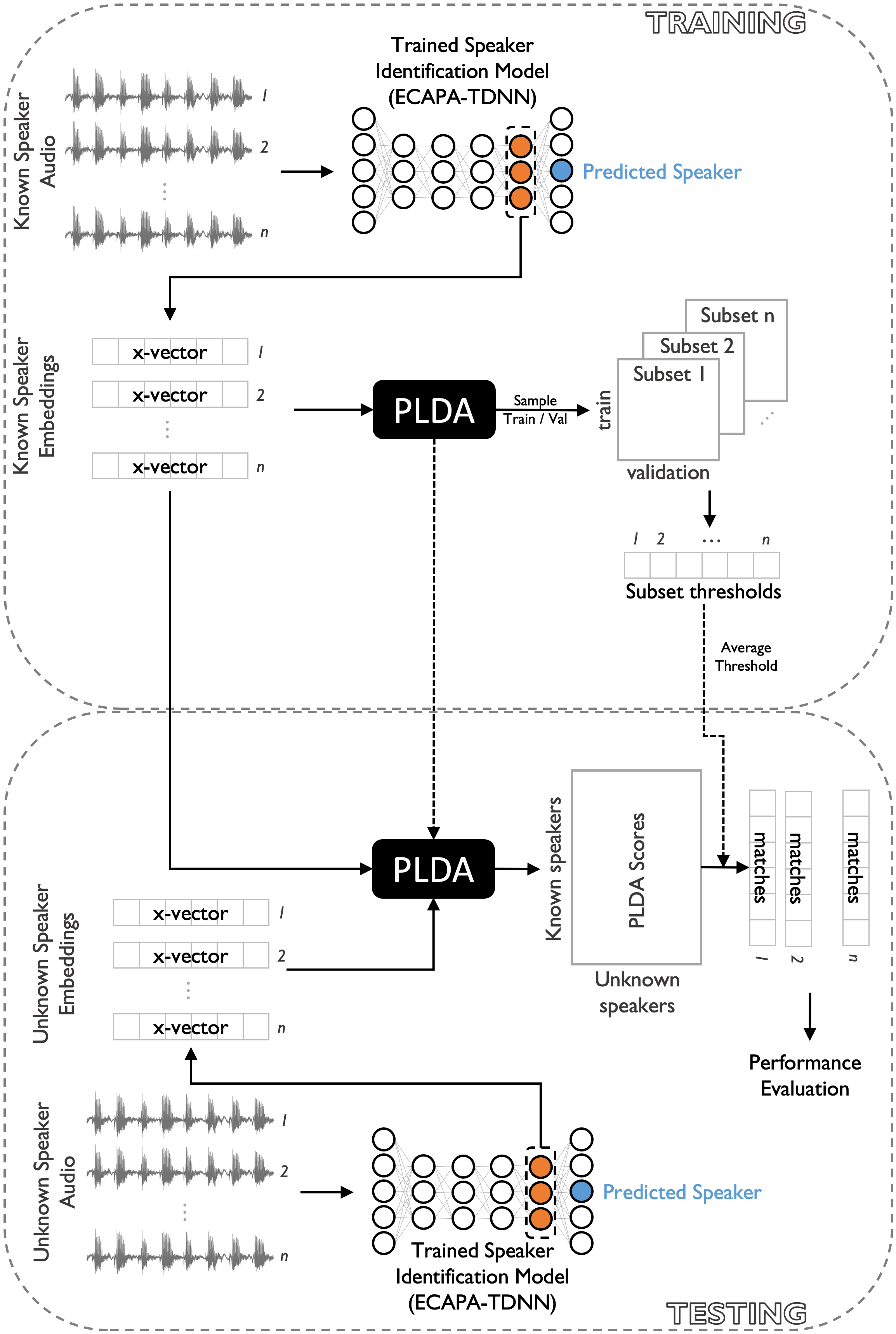
Large, curated datasets are required to leverage speech-based tools in healthcare. These are costly to produce, resulting in increased interest in data sharing. As speech can potentially identify speakers (i.e., voiceprints), sharing recordings raises privacy concerns. We examine the re-identification risk for speech recordings, without reference to demographic or metadata, using a state-of-the-art speaker recognition system. We demonstrate that the risk is inversely related to the number of comparisons an adversary must consider, i.e., the search space. Risk is high for a small search space but drops as the search space grows ($precision >0.85$ for $<1*10^{6}$ comparisons, $precision <0.5$ for $>3*10^{6}$ comparisons). Next, we show that the nature of a speech recording influences re-identification risk, with non-connected speech (e.g., vowel prolongation) being harder to identify. Our findings suggest that speaker recognition systems can be used to re-identify participants in specific circumstances, but in practice, the re-identification risk appears low.
翻译:为了利用基于语言的保健工具,需要大量整理数据集,以利用基于语言的保健工具。制作这些数据集费用昂贵,导致对数据共享的兴趣增加。由于演讲可能识别发言者(即语音指纹),共享录音会引起隐私问题。我们使用最先进的语音识别系统,在不参考人口或元数据的情况下,审查语音录音的重新识别风险。我们证明,风险与对手必须考虑的比较数量(即搜索空间)存在反向关系。小搜索空间的风险很高,但随着搜索空间的增长而下降(精确度 > 0.85美元,为 < 1*10 ⁇ 6美元),进行比较,为0.5美元,为 > 310 ⁇ 6美元) 。接下来,我们显示,语音记录的性质影响重新识别风险,而无关联的语音(如誓言延长)则更难识别。我们的研究结果表明,语音识别系统可用于在特定情况下重新识别参与者,但在实践中,重新识别风险似乎较低。