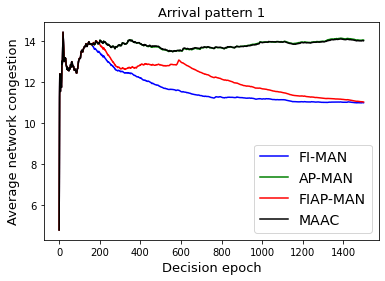
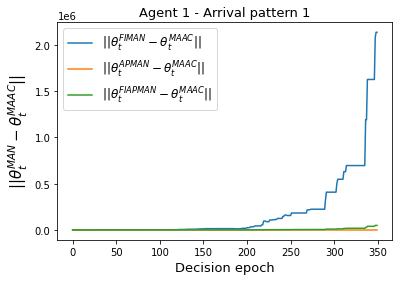
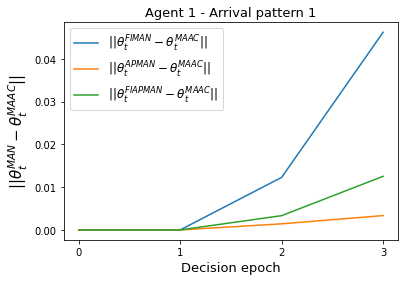
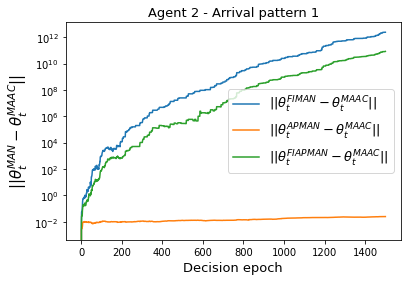
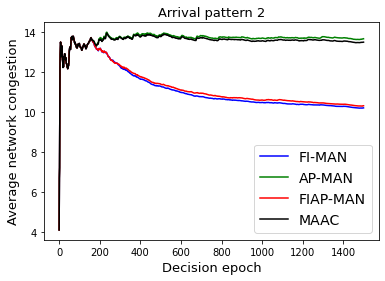
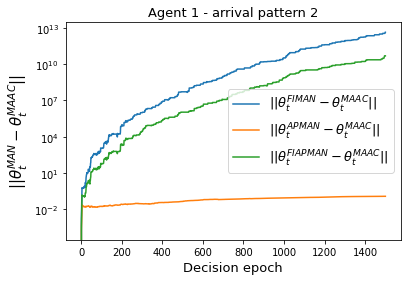
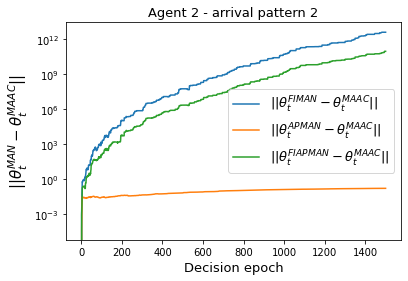
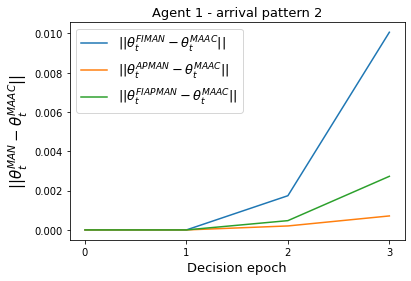
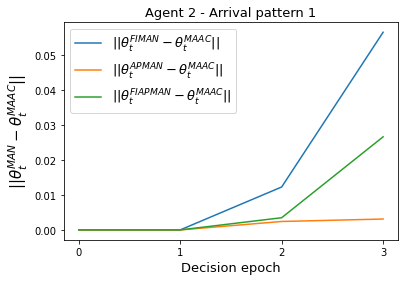
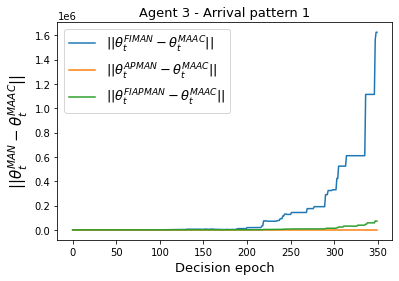
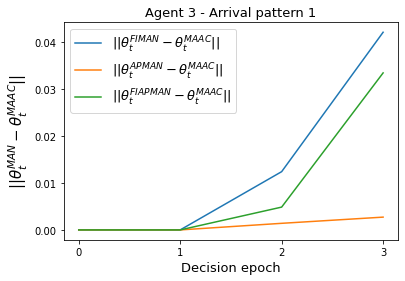
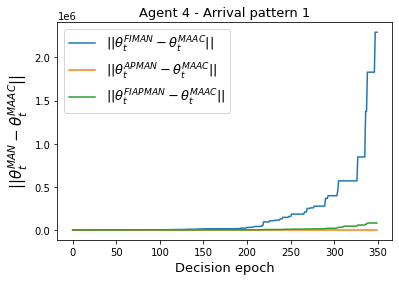
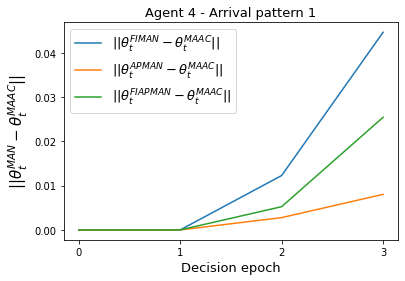
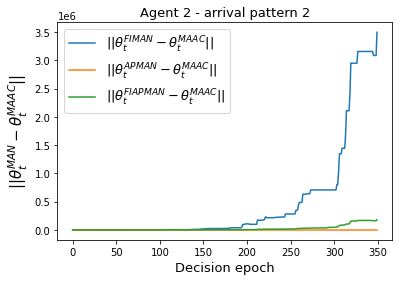
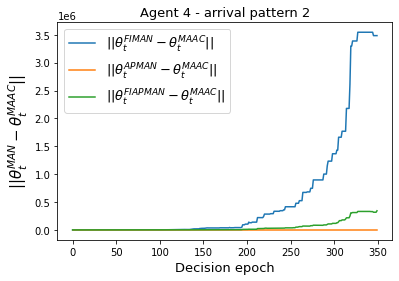
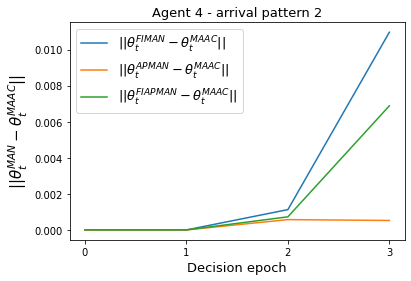
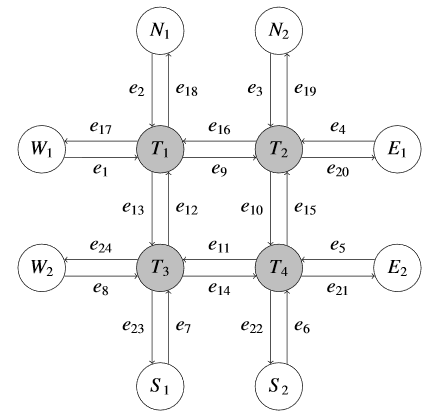
Both single-agent and multi-agent actor-critic algorithms are an important class of Reinforcement Learning algorithms. In this work, we propose three fully decentralized multi-agent natural actor-critic (MAN) algorithms. The agents' objective is to collectively learn a joint policy that maximizes the sum of averaged long-term returns of these agents. In the absence of a central controller, agents communicate the information to their neighbors via a time-varying communication network while preserving privacy. We prove the convergence of all the 3 MAN algorithms to a globally asymptotically stable point of the ODE corresponding to the actor update; these use linear function approximations. We use the Fisher information matrix to obtain the natural gradients. The Fisher information matrix captures the curvature of the Kullback-Leibler (KL) divergence between polices at successive iterates. We also show that the gradient of this KL divergence between policies of successive iterates is proportional to the objective function's gradient. Our MAN algorithms indeed use this \emph{representation} of the objective function's gradient. Under certain conditions on the Fisher information matrix, we prove that at each iterate, the optimal value via MAN algorithms can be better than that of the multi-agent actor-critic (MAAC) algorithm using the standard gradients. To validate the usefulness of our proposed algorithms, we implement all the 3 MAN algorithms on a bi-lane traffic network to reduce the average network congestion. We observe an almost 25% reduction in the average congestion in 2 MAN algorithms; the average congestion in another MAN algorithm is on par with the MAAC algorithm. We also consider a generic 15 agent MARL; the performance of the MAN algorithms is again as good as the MAAC algorithm. We attribute the better performance of the MAN algorithms to their use of the above representation.
翻译:在这项工作中,我们建议三个完全分散的多试剂自然演艺员(MAN)算法。这些代理商的目标是集体学习一个联合政策,使这些代理商平均长期回报的总和最大化。在没有中央控制器的情况下,代理商通过一个时间变化的通信网络将信息传递给邻居,同时保护隐私。我们证明所有3个MAN算法都与一个全球无干扰稳定的ODE点相匹配;这些算法使用线性函数近似值。我们使用Fisher信息矩阵获取自然梯度。Fisher信息矩阵在连续循环中捕捉了Kullback-Leable(KL)警察之间平均长期回报的曲线。我们还显示,这种KL值在连续循环政策上的偏差与目标函数的梯度成成正比。我们的MAN算算法也确实使用了这个目标函数的平价值;我们使用2个线性能信息矩阵的直线性能矩阵来降低2级值。在某种特定条件下,使用MIRA-LMAL 算法中,我们用一个最优的马力运算算算算算算算算算法的平价值。