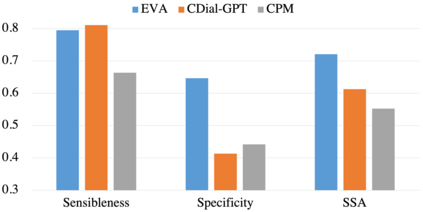
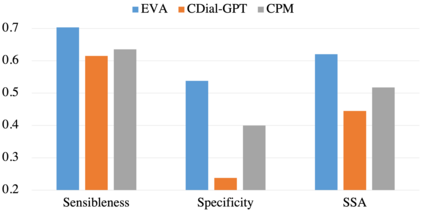
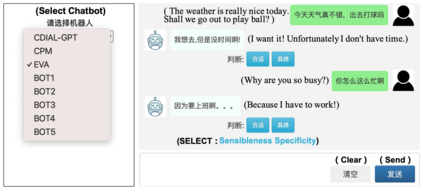
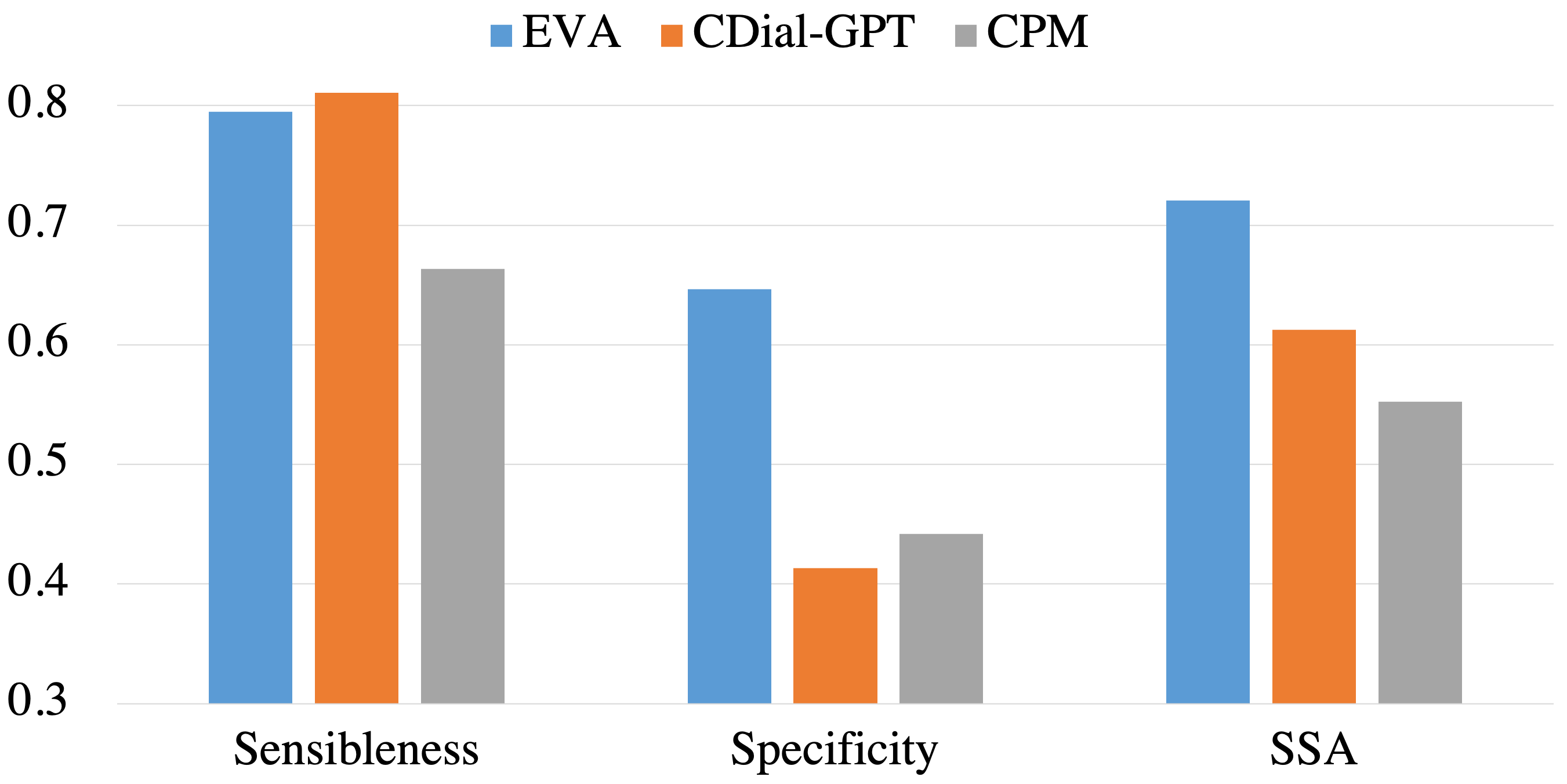
Although pre-trained language models have remarkably enhanced the generation ability of dialogue systems, open-domain Chinese dialogue systems are still limited by the dialogue data and the model size compared with English ones. In this paper, we propose EVA, a Chinese dialogue system that contains the largest Chinese pre-trained dialogue model with 2.8B parameters. To build this model, we collect the largest Chinese dialogue dataset named WDC-Dialogue from various public social media. This dataset contains 1.4B context-response pairs and is used as the pre-training corpus of EVA. Extensive experiments on automatic and human evaluation show that EVA outperforms other Chinese pre-trained dialogue models especially in the multi-turn interaction of human-bot conversations.
翻译:虽然经过培训的语文模式明显提高了对话系统的生成能力,但开放的中华对话系统仍受到对话数据和与英文相比的模型规模的限制,我们在本文件中提议,EVA是一个中国对话系统,其中包含了中国最大的、具有2.8B参数的经过培训的对话模式。为了建立这一模式,我们从各种公共社交媒体收集了最大的中国对话数据集,名为WDC-Dialoge。该数据集包含1.4B背景响应配对,并用作EVA的预培训材料。关于自动和人文评估的广泛实验显示,EVA优于其他经过培训的中国对话模式,特别是在人文对话的多轨互动方面。