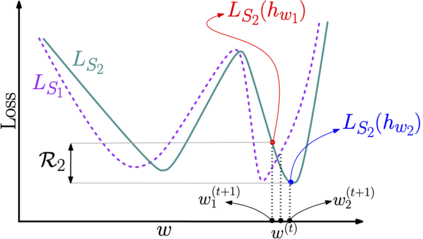
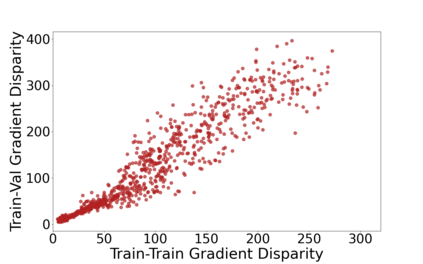
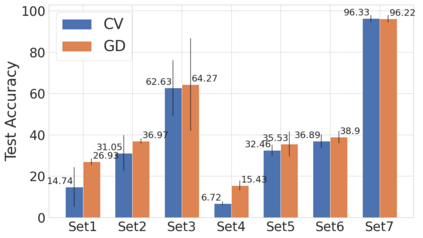
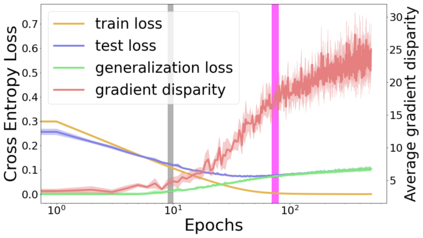
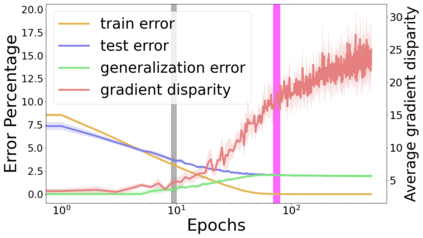
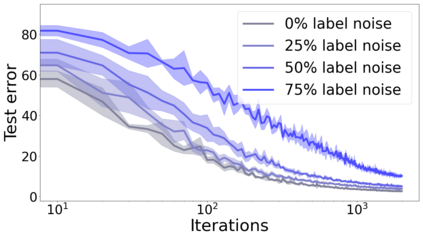
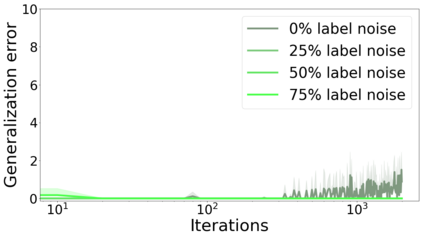
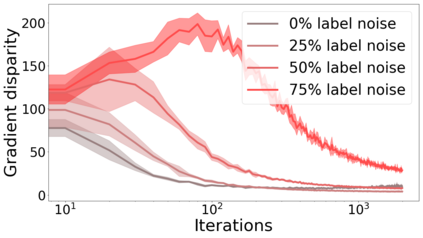
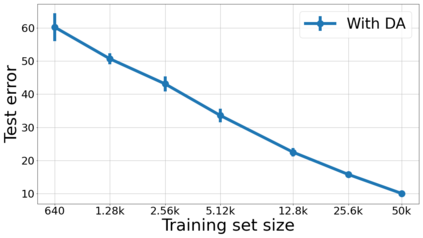
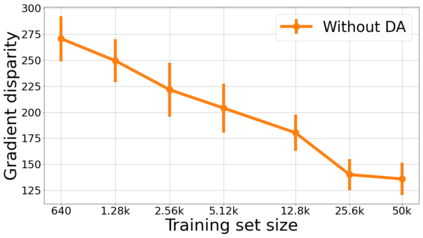
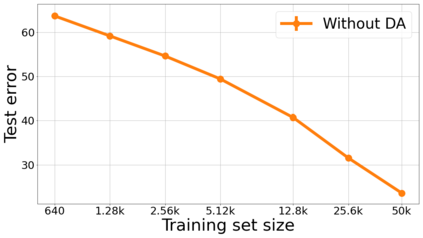
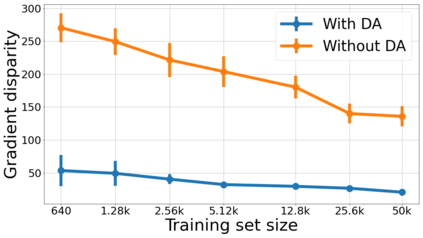
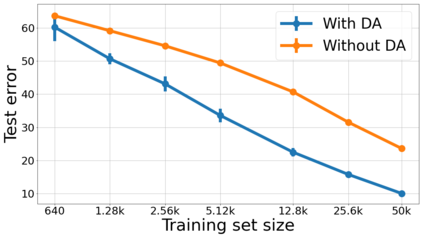
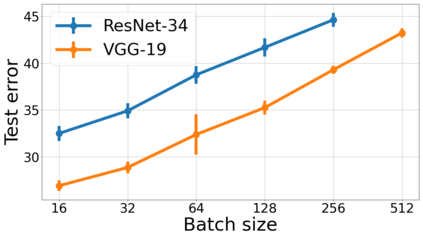
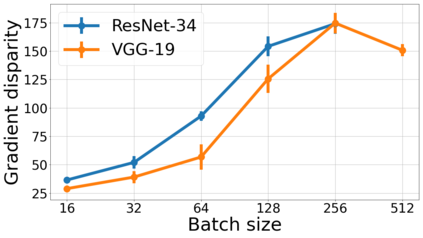
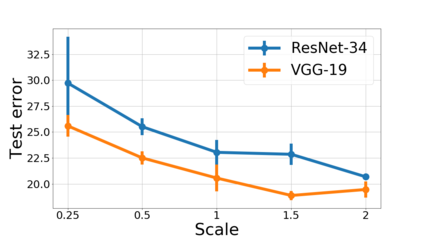
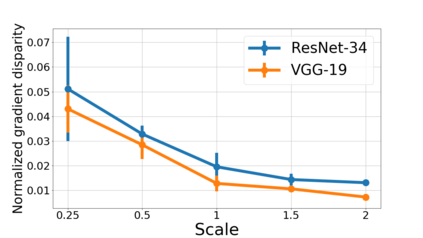
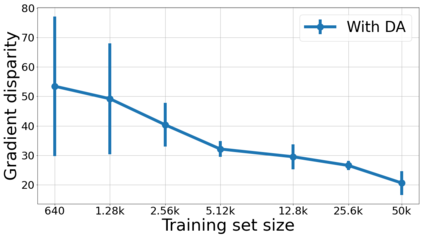
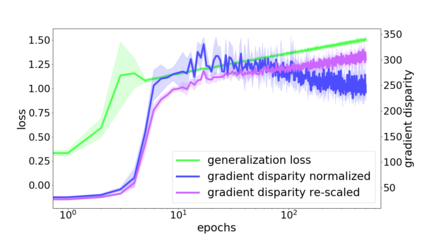
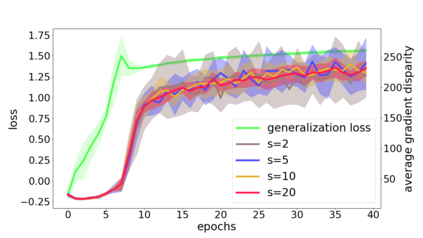
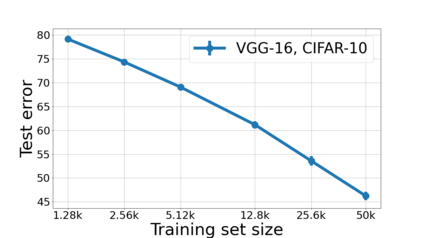
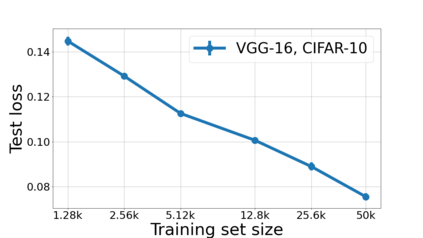
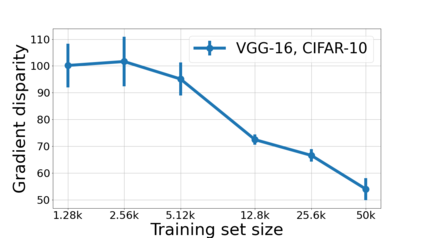
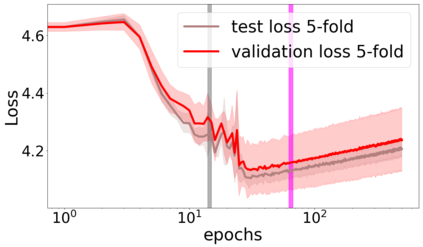
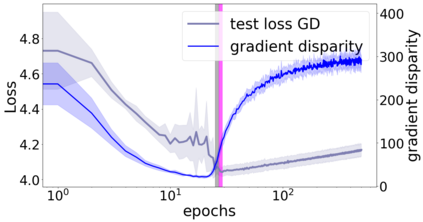
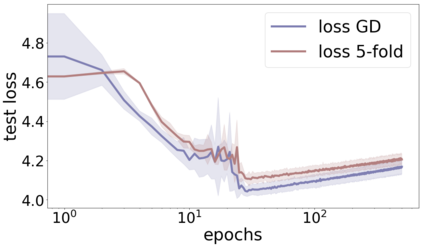
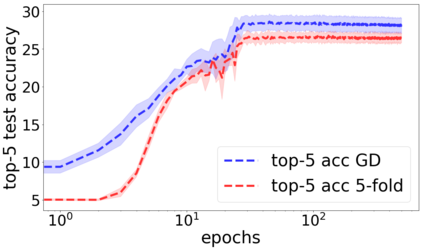
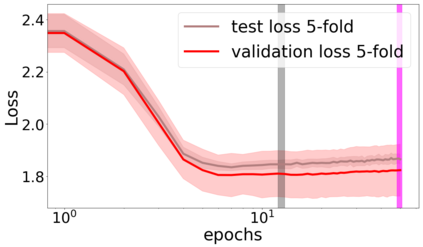
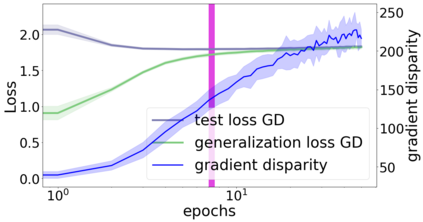
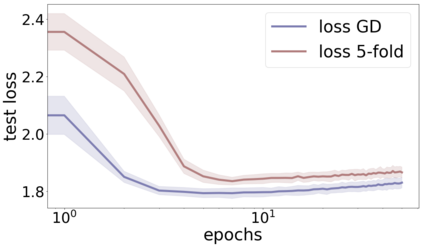
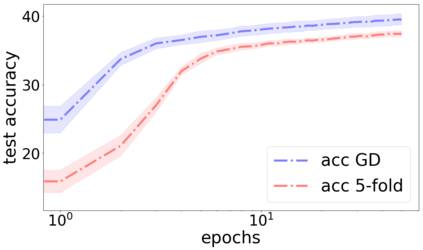
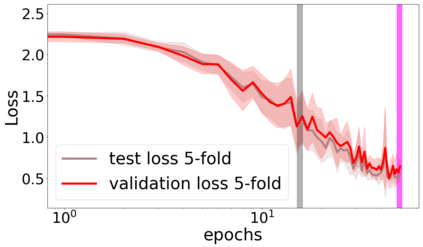
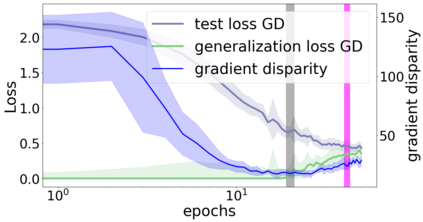
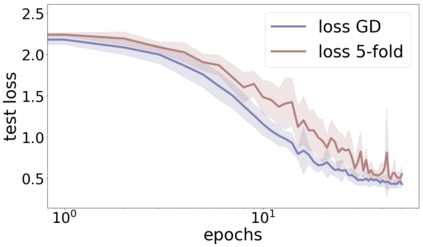
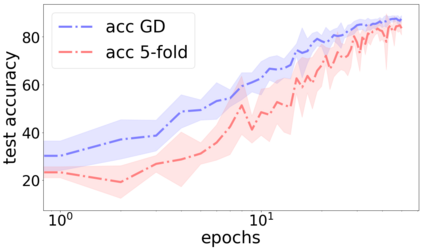
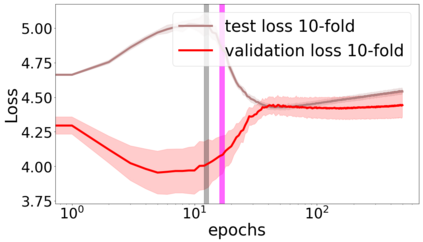
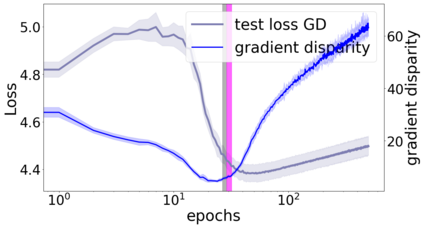
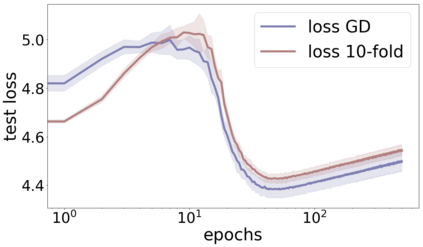
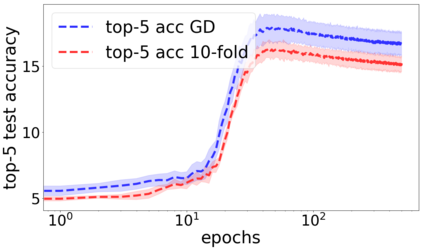
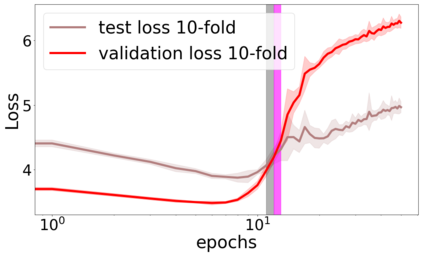
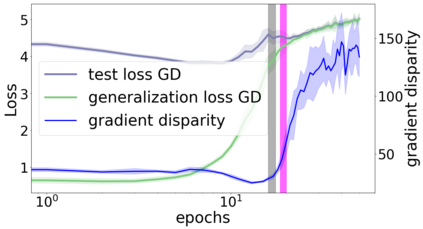
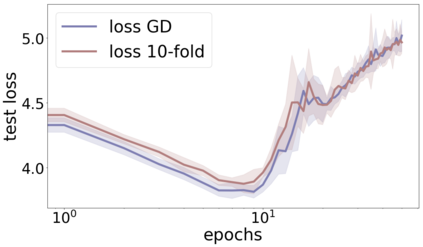
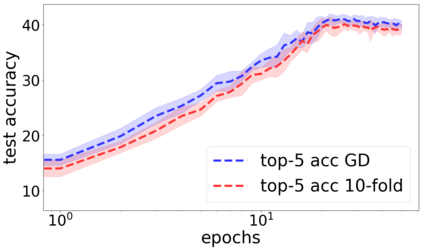
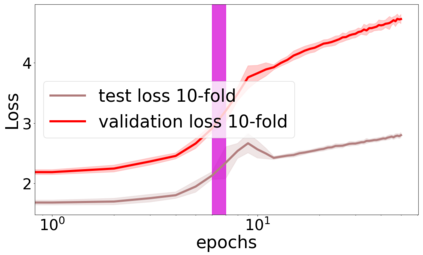
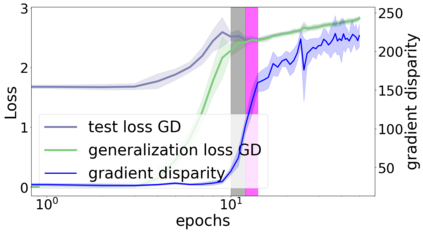
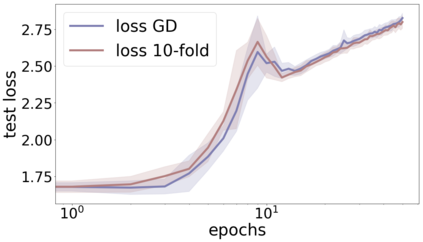
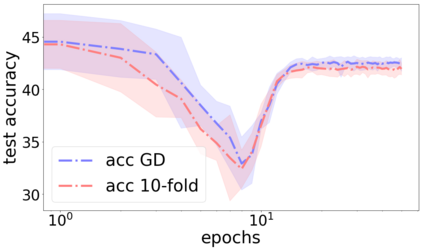
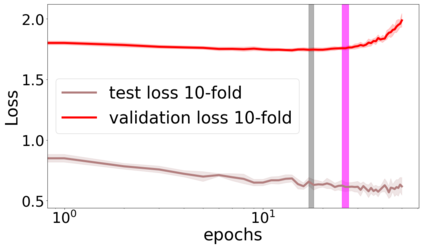
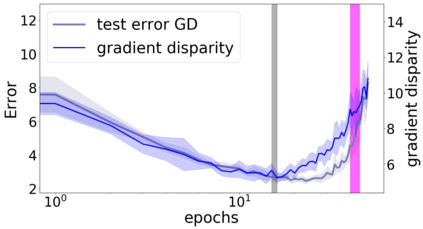
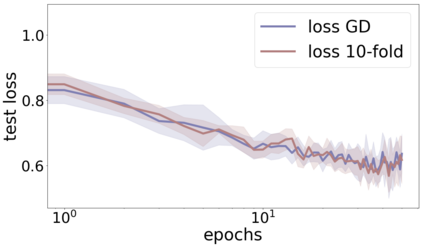
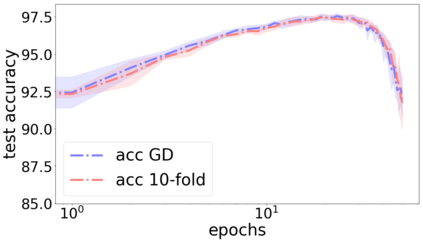
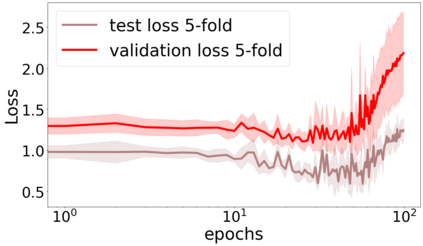
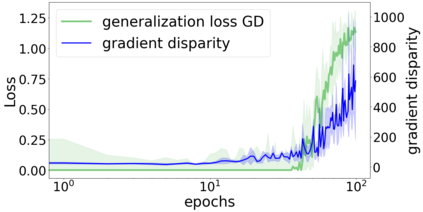
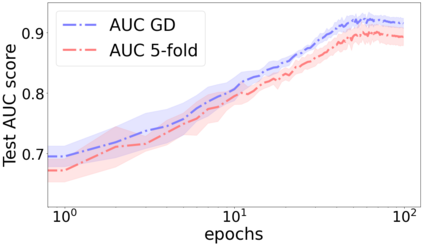
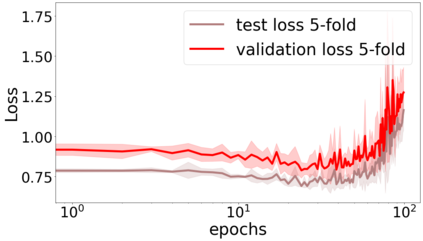
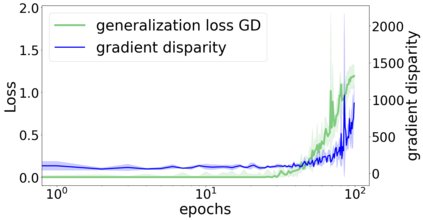
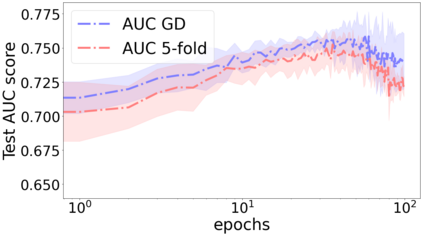
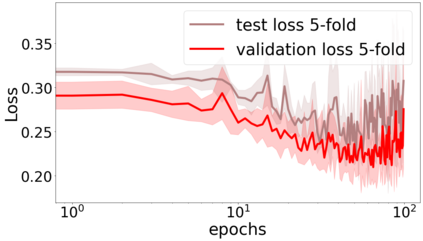
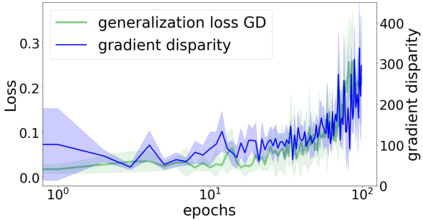
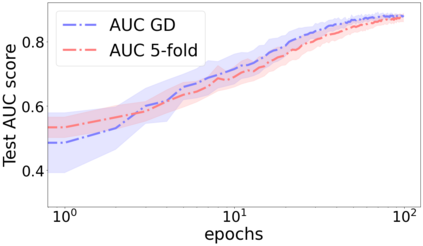
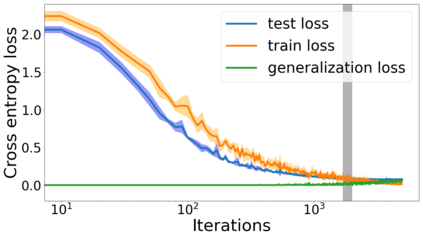
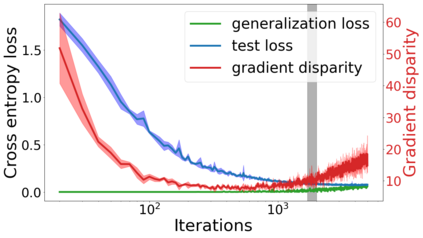
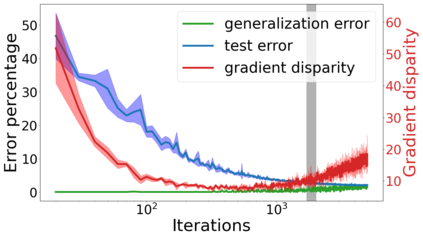
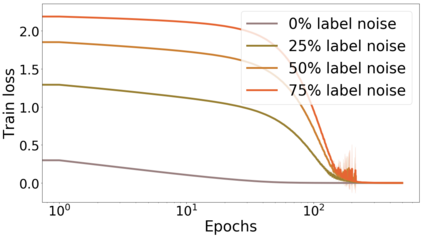
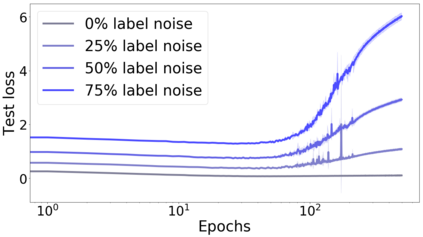
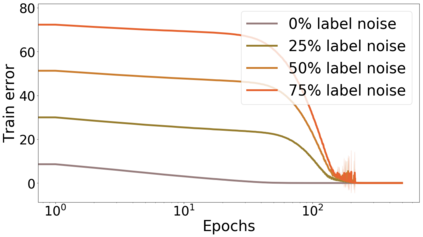
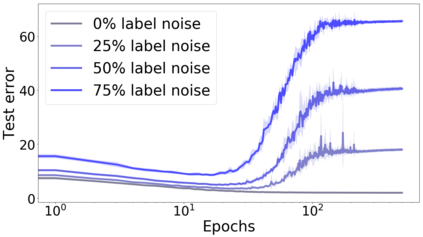
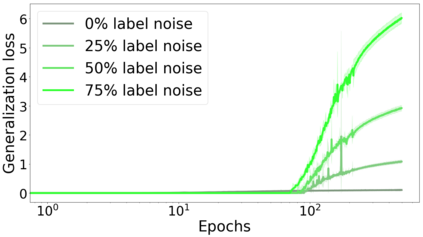
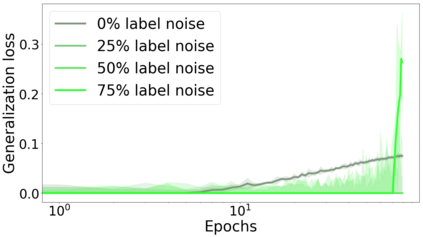
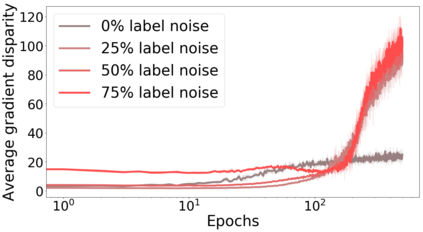
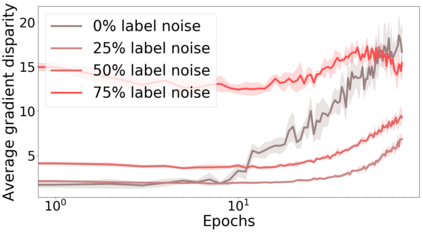
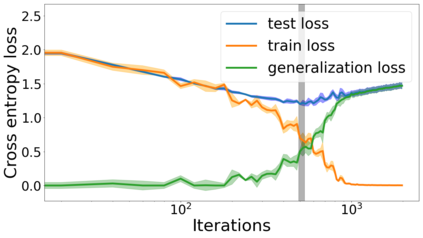
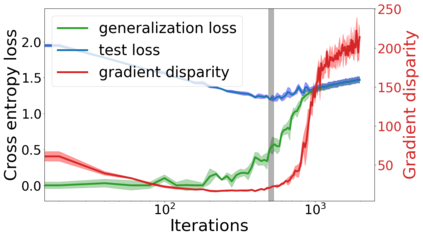
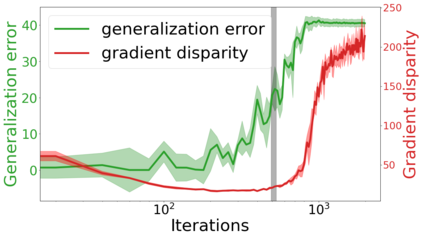
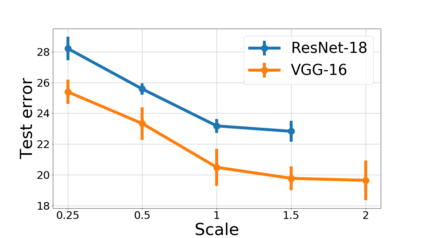
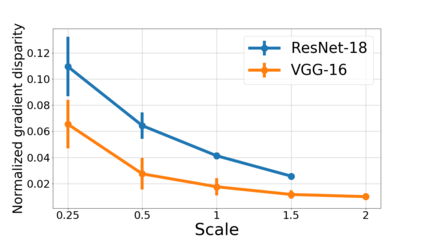
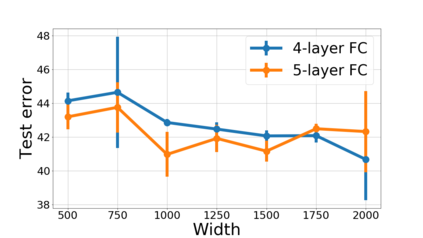
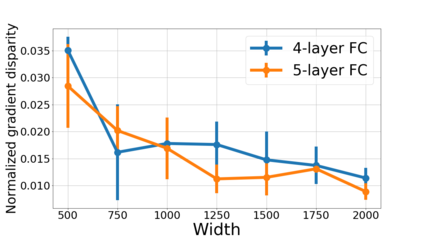
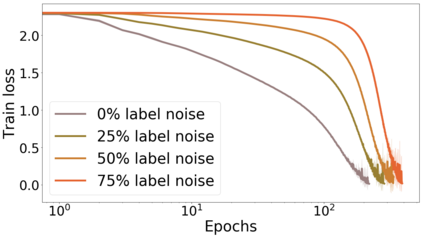
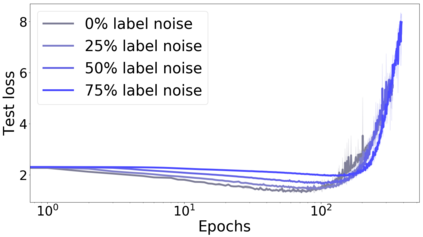
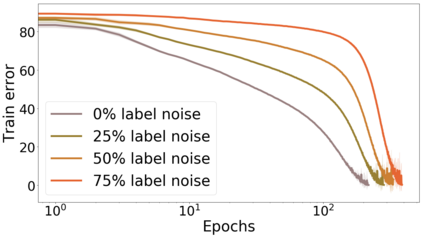
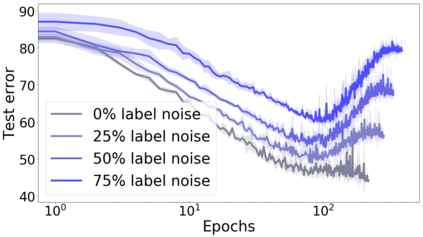
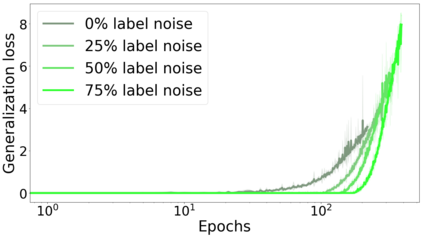
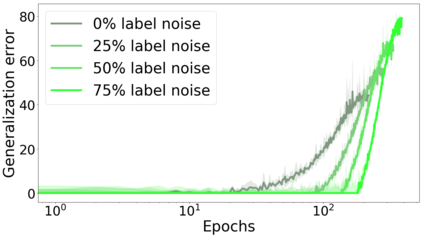
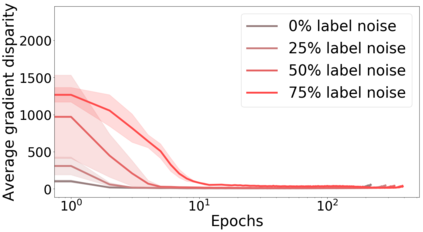
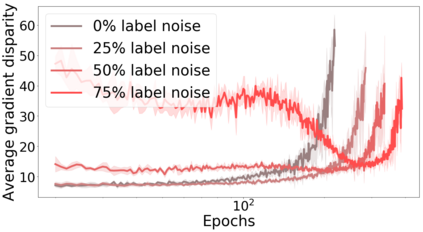
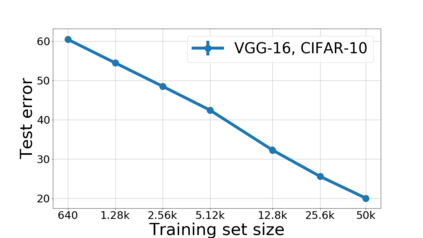
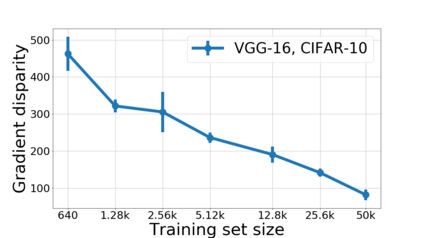
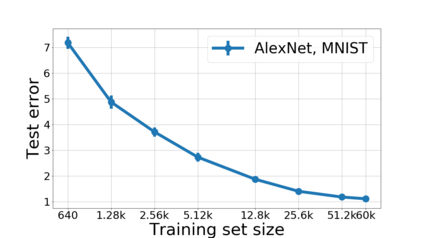
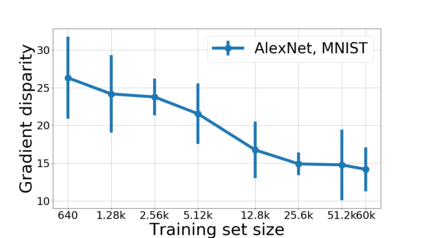
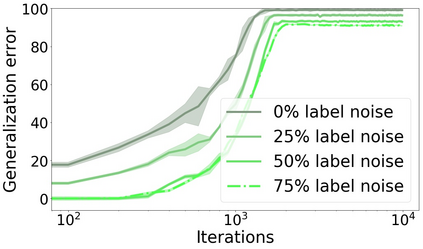
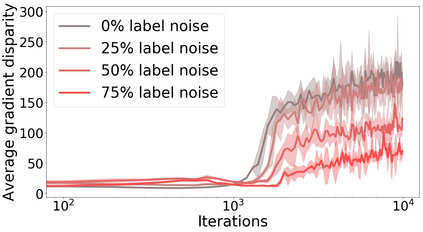
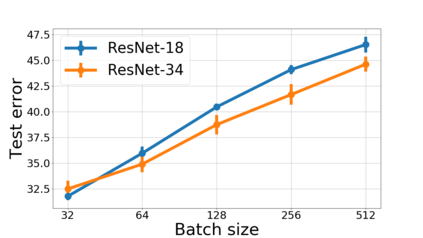
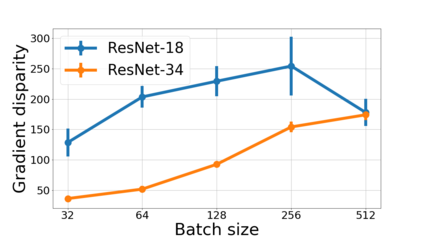
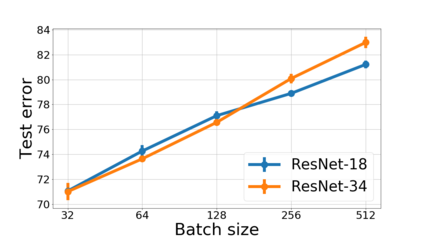
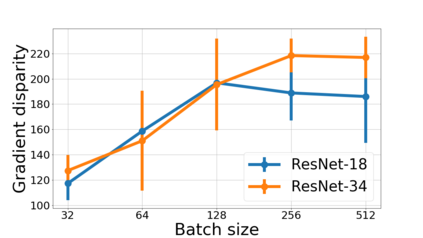
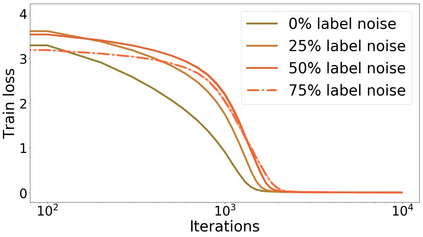
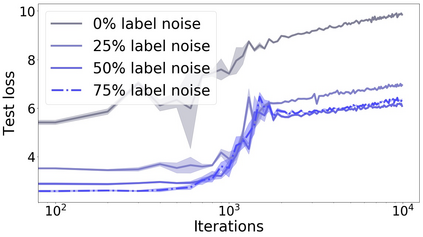
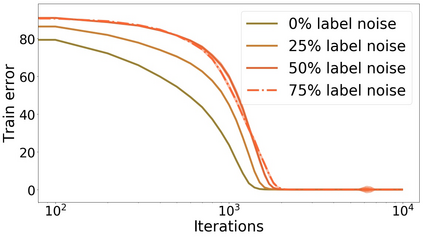
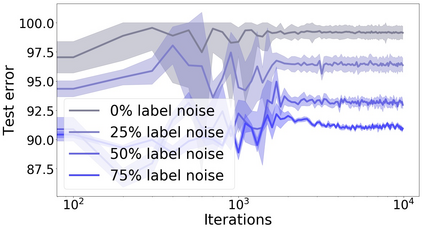
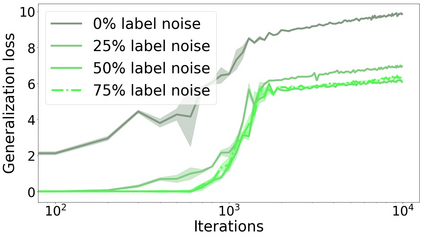
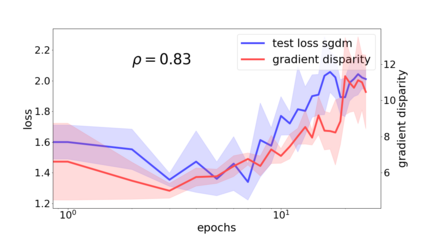
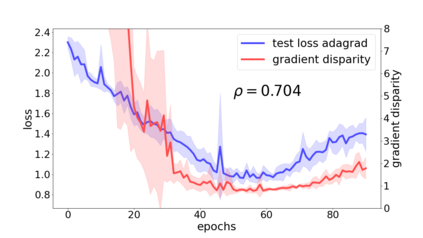
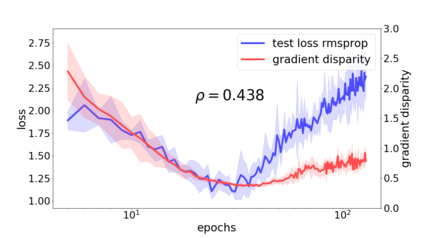
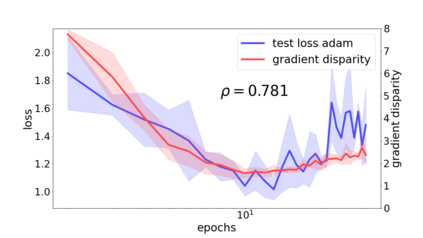
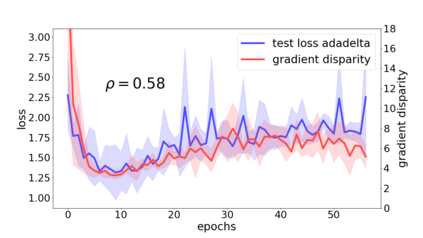
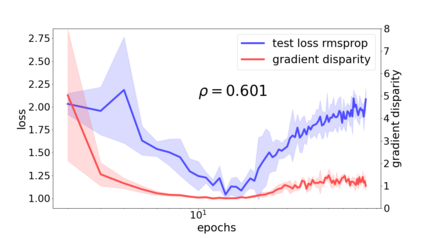
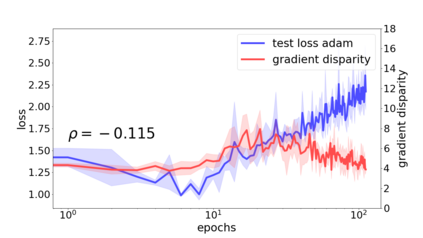
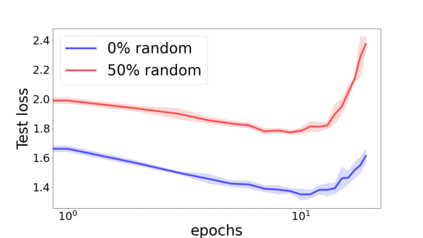
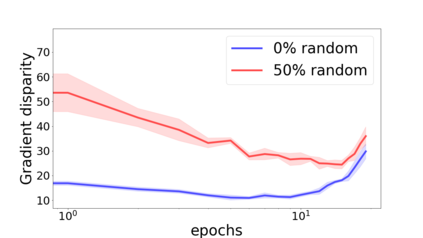
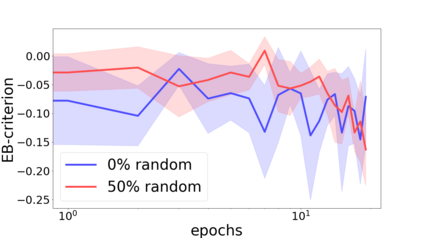
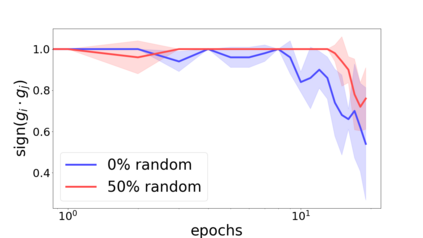
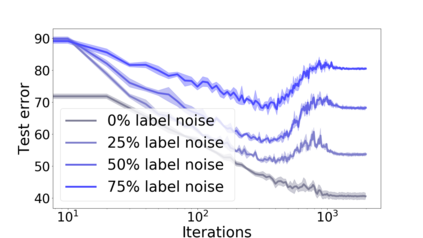
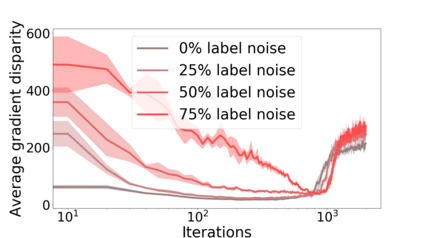
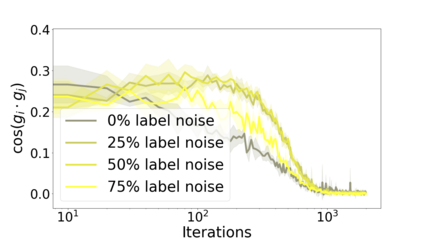
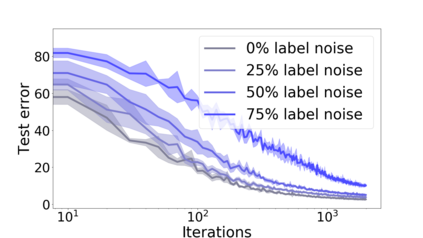
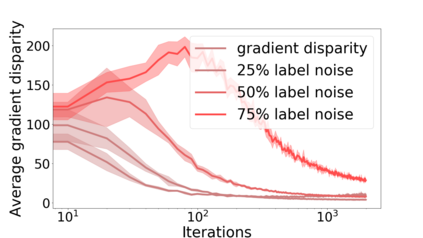
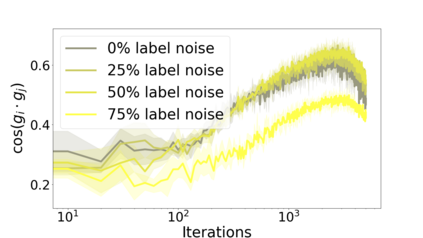
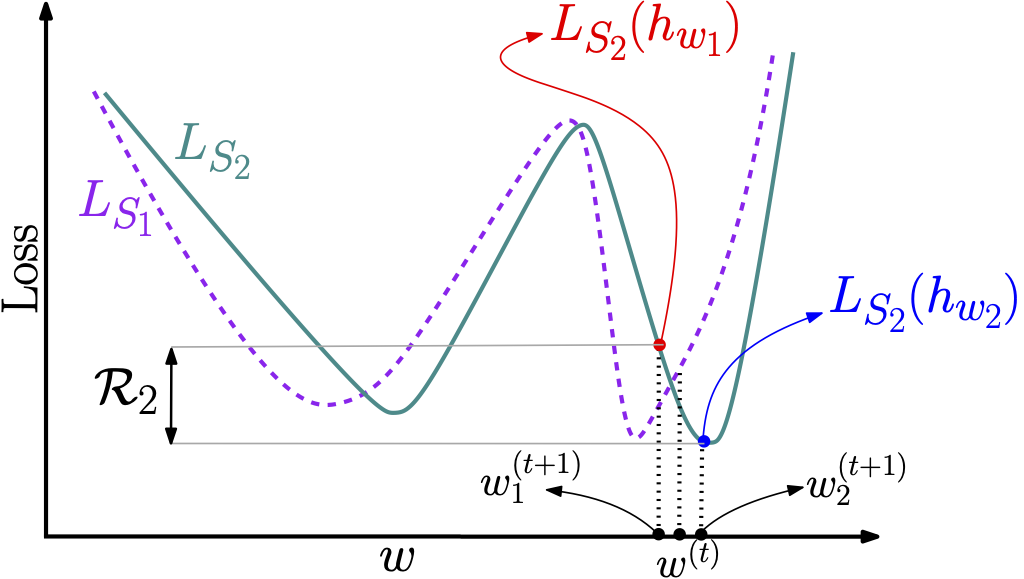
We propose a metric for evaluating the generalization ability of deep neural networks trained with mini-batch gradient descent. Our metric, called gradient disparity, is the $\ell_2$ norm distance between the gradient vectors of two mini-batches drawn from the training set. It is derived from a probabilistic upper bound on the difference between the classification errors over a given mini-batch, when the network is trained on this mini-batch and when the network is trained on another mini-batch of points sampled from the same dataset. We empirically show that gradient disparity is a very promising early-stopping criterion (i) when data is limited, as it uses all the samples for training and (ii) when available data has noisy labels, as it signals overfitting better than the validation data. Furthermore, we show in a wide range of experimental settings that gradient disparity is strongly related to the generalization error between the training and test sets, and that it is also very informative about the level of label noise.
翻译:我们建议了一种衡量标准,用于评价受过小型梯度梯度下降训练的深神经网络的普及能力。我们称为梯度差异的衡量标准是两个从训练集中抽取的小型弹匣的梯度矢量之间的标准距离$@ell_2$。它来自对某一微型弹匣的分类错误之间的差别的概率上限,当网络是在这个微型弹匣上接受培训时,当网络是用从同一数据集中抽取的另一批小点时。我们从经验上表明,梯度差异是一个很有希望的早期停止标准 (i) 当数据有限时,它使用所有样本进行培训,以及(ii) 当现有数据带有噪音标签时,它发出信号比验证数据更好。此外,我们在广泛的实验环境里显示,梯度差异与培训和测试组之间的普遍错误密切相关,而且对于标签噪音的程度也非常丰富。