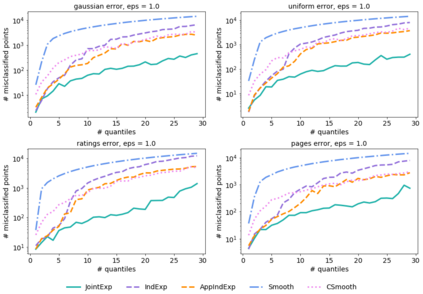
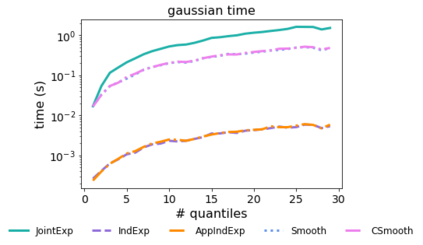
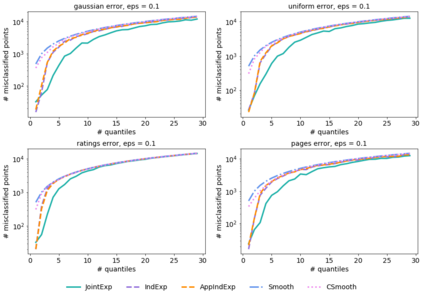
Quantiles are often used for summarizing and understanding data. If that data is sensitive, it may be necessary to compute quantiles in a way that is differentially private, providing theoretical guarantees that the result does not reveal private information. However, in the common case where multiple quantiles are needed, existing differentially private algorithms scale poorly: they compute each quantile individually, splitting their privacy budget and thus decreasing accuracy. In this work we propose an instance of the exponential mechanism that simultaneously estimates $m$ quantiles from $n$ data points while guaranteeing differential privacy. The utility function is carefully structured to allow for an efficient implementation that avoids exponential dependence on $m$ and returns estimates of all $m$ quantiles in time $O(mn^2 + m^2n)$. Experiments show that our method significantly outperforms the current state of the art on both real and synthetic data while remaining efficient enough to be practical.
翻译:量化法通常用于总结和理解数据。 如果数据是敏感的, 则可能有必要以不同私人的方式计算量化, 提供理论保证结果不会披露私人信息。 但是, 在需要多个量化法的常见情况下, 现有的差异私人算法规模不高: 它们单独计算每个量化, 分割隐私预算, 从而降低准确性。 在这项工作中, 我们提议了一个指数机制的例子, 该指数机制同时从美元数据点中估算美元量化值, 同时保证差异的隐私。 实用功能结构谨慎, 以便高效实施, 避免指数依赖美元, 并在时间上将所有美元量化法的估计数回报到$O( m ⁇ 2 + m ⁇ 2 ) 。 实验显示, 我们的方法大大超过真实和合成数据的当前水平, 同时保持足够有效, 以实用的方式运行 。