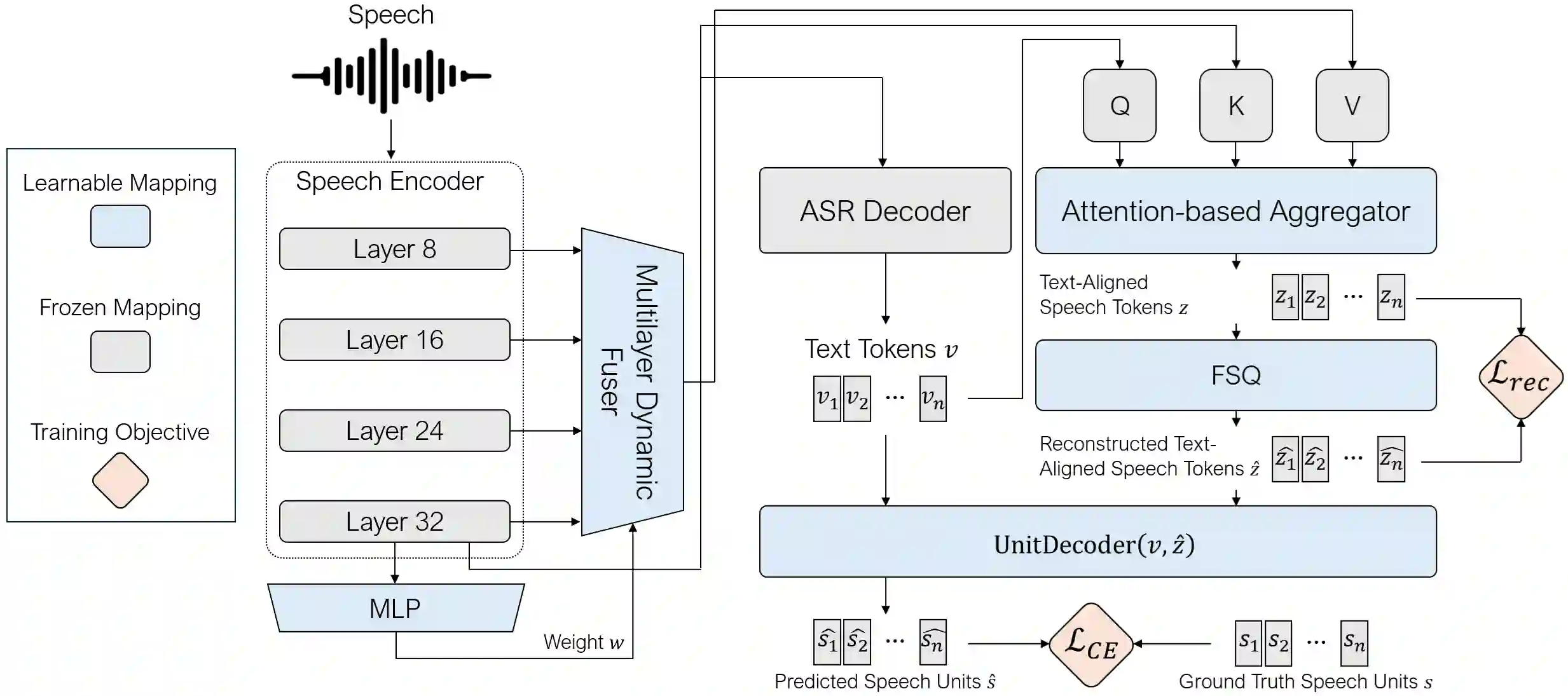
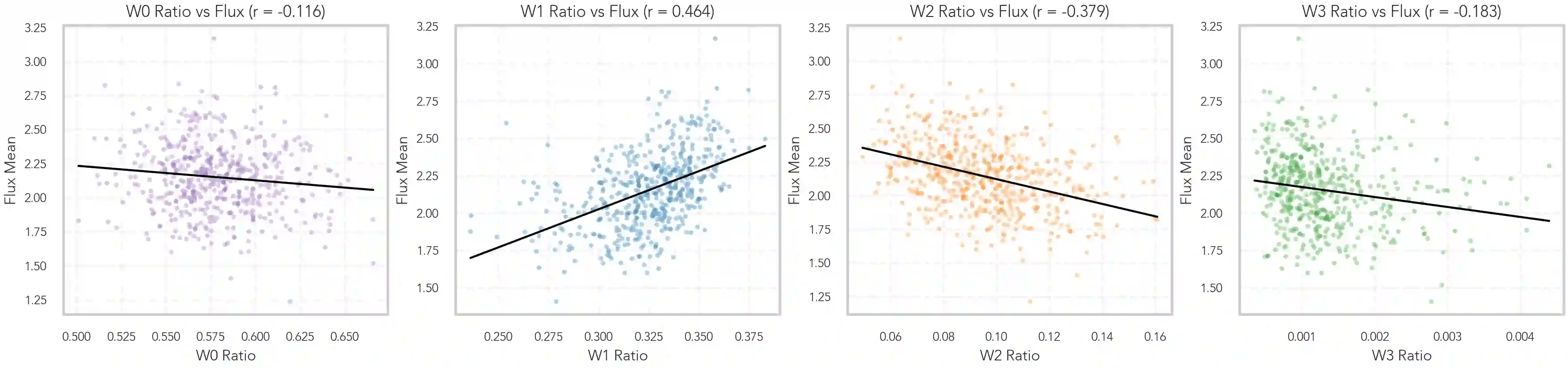
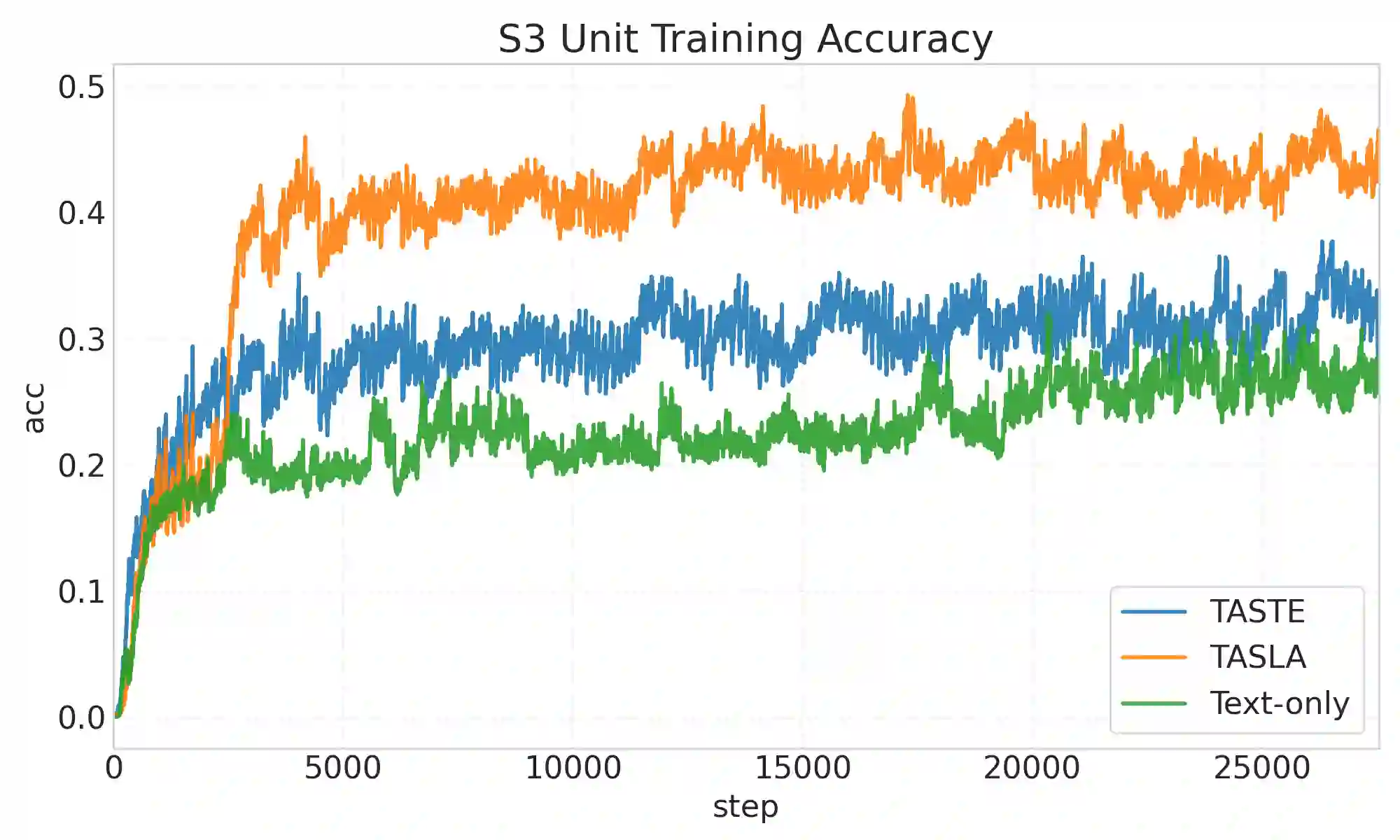
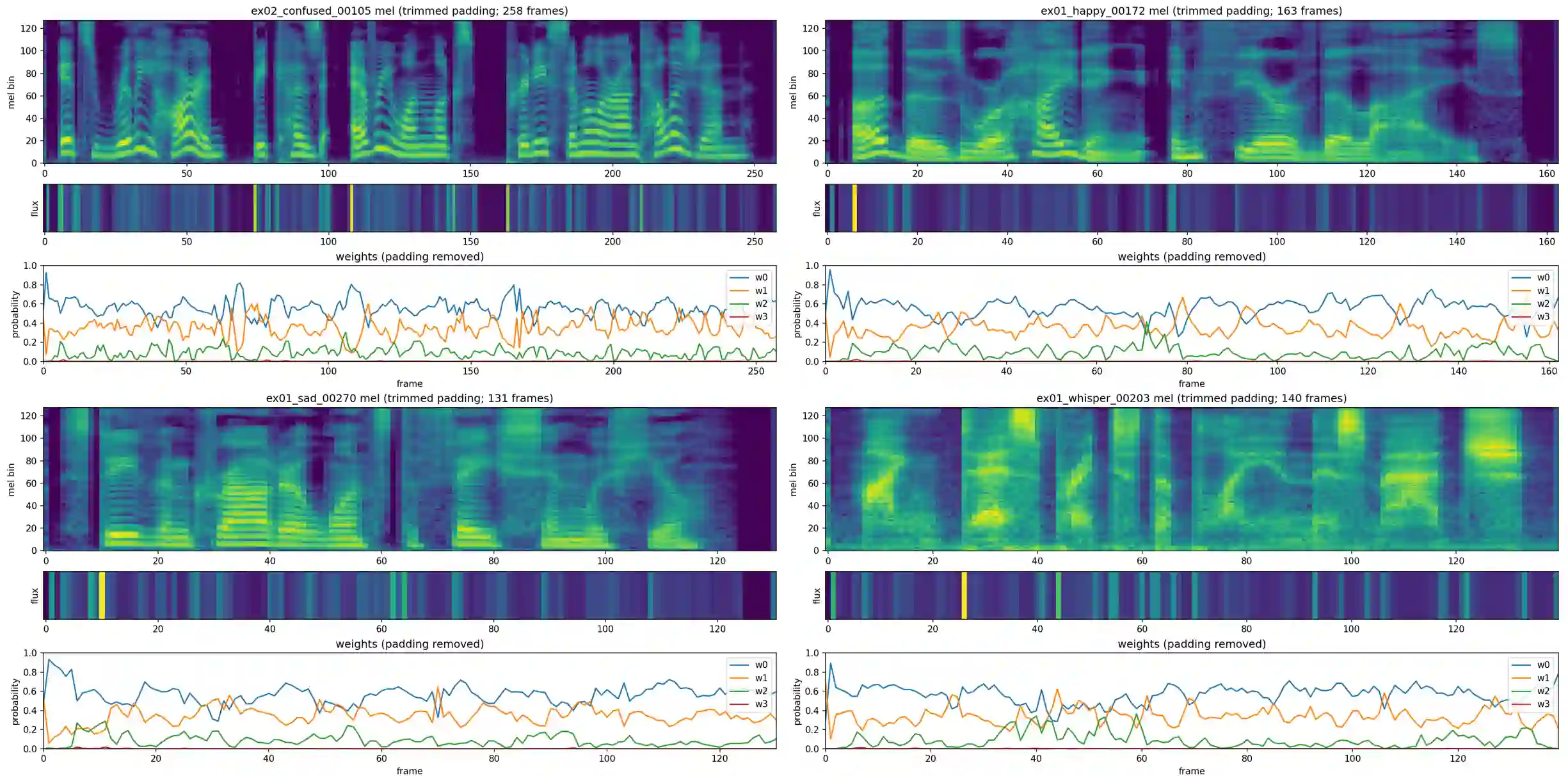
We propose Text-Aligned Speech Tokens with Multiple Layer-Aggregation (TASLA), which is a text-aligned speech tokenization framework that aims to address the problem that under a low-frame-rate and text-aligned regime, single-source speech tokens may lose acoustic details during reconstruction. On the other hand, this paper further explains how different encoder layers collaborate to capture comprehensive acoustic features for tokenization. Previous work, TASTE, proposed the text-aligned speech tokenization framework, which is a LM-friendly architecture, but struggles to capture acoustic details. We address this trade-off with two components: Multi-Layer Dynamic Attention (MLDA), which lets each text position adaptively mix shallow/deep features from a frozen speech encoder, and Finite Scalar Quantization (FSQ), a simple per-dimension discretization with smooth optimization. At about 2.62 Hz (tokens/s), TASLA consistently improves prosody and achieves competitive quality over TASTE on in-domain (LibriSpeech) and OOD (EXPRESSO, Voxceleb) sets. We further demonstrate that dynamic layer mixing is correlated with spectral flux and explains why MLDA preserves prosody under a low frame rate with extreme feature compression.
翻译:我们提出了具有多层聚合的文本对齐语音标记(TASLA),这是一个文本对齐的语音标记化框架,旨在解决在低帧率与文本对齐机制下,单源语音标记在重建过程中可能丢失声学细节的问题。另一方面,本文进一步阐释了不同编码器层如何协作以捕获用于标记化的全面声学特征。先前的工作TASTE提出了文本对齐的语音标记化框架,这是一种对语言模型友好的架构,但难以捕获声学细节。我们通过两个组件来解决这一权衡:多层动态注意力(MLDA),它允许每个文本位置自适应地混合来自冻结语音编码器的浅层/深层特征;以及有限标量量化(FSQ),这是一种简单的逐维度离散化方法,具有平滑优化特性。在约2.62 Hz(标记/秒)的速率下,TASLA在领域内(LibriSpeech)和领域外(EXPRESSO, Voxceleb)数据集上持续改善了韵律表现,并在质量上取得了与TASTE相当的结果。我们进一步证明,动态层混合与频谱通量相关,并解释了MLDA为何能在低帧率和极端特征压缩条件下保持韵律信息。