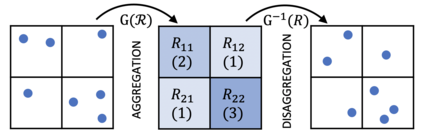
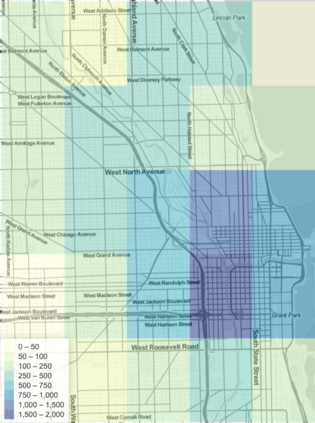
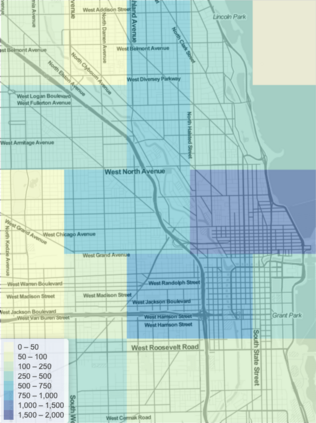
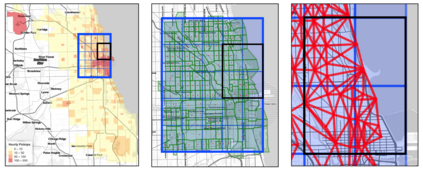
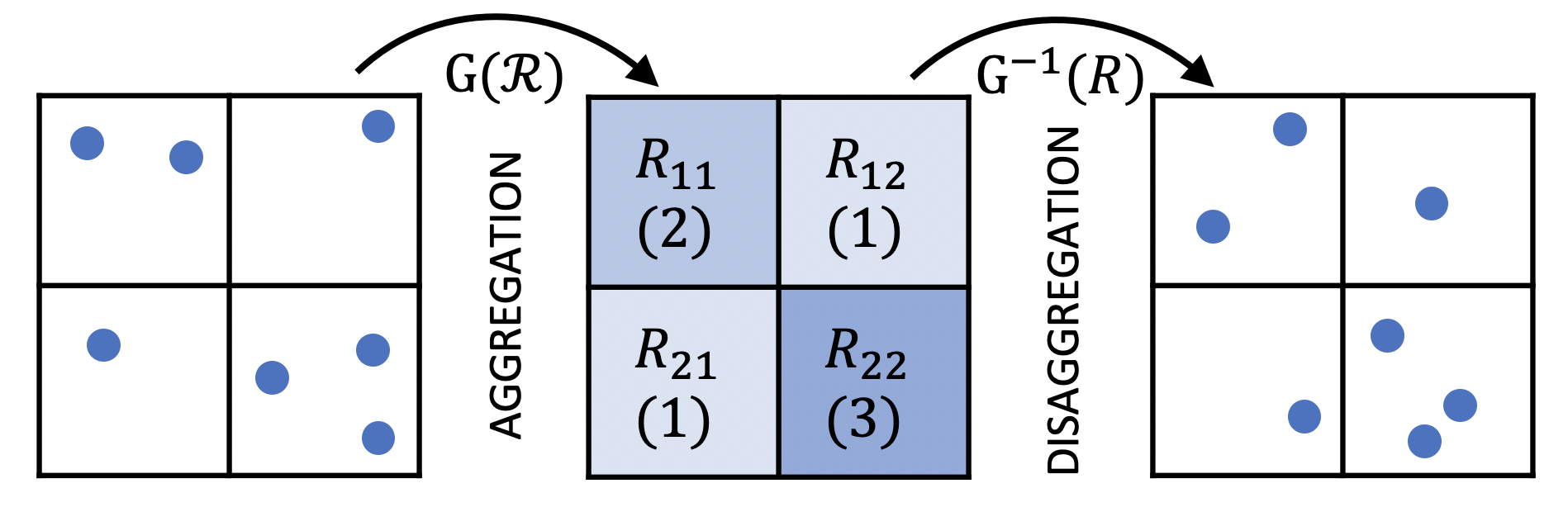
Mobility on demand (MoD) systems show great promise in realizing flexible and efficient urban transportation. However, significant technical challenges arise from operational decision making associated with MoD vehicle dispatch and fleet rebalancing. For this reason, operators tend to employ simplified algorithms that have been demonstrated to work well in a particular setting. To help bridge the gap between novel and existing methods, we propose a modular framework for fleet rebalancing based on model-free reinforcement learning (RL) that can leverage an existing dispatch method to minimize system cost. In particular, by treating dispatch as part of the environment dynamics, a centralized agent can learn to intermittently direct the dispatcher to reposition free vehicles and mitigate against fleet imbalance. We formulate RL state and action spaces as distributions over a grid partitioning of the operating area, making the framework scalable and avoiding the complexities associated with multiagent RL. Numerical experiments, using real-world trip and network data, demonstrate that this approach has several distinct advantages over baseline methods including: improved system cost; high degree of adaptability to the selected dispatch method; and the ability to perform scale-invariant transfer learning between problem instances with similar vehicle and request distributions.
翻译:根据需求进行机动(MoD)系统在实现灵活和高效的城市交通方面大有希望;然而,由于国防部车辆调度和车队再平衡有关的业务决策,在技术上产生了巨大的挑战;为此原因,操作者往往采用在特定环境下证明行之有效的简化算法;为缩小新方法和现有方法之间的差距,我们提议了一个基于无模式强化学习(RL)的车队再平衡模块框架,以利用现有的调度方法尽量减少系统成本;特别是,将调度作为环境动态的一部分处理,中央集权代理可以学习间歇性地指导调度员重新定位自由车辆和减轻车队不平衡现象;我们制定RL状态和行动空间,作为在运行区的网格分割线上分布,使框架可以伸缩,避免与多剂RL有关的复杂情况。 数字实验,利用实际世界旅行和网络数据,表明这一方法在基线方法上有若干明显的优势,包括:改进系统成本;高度适应选定的调度方法;以及有能力在类似车辆和请求分配的问题中进行规模波动转移学习。