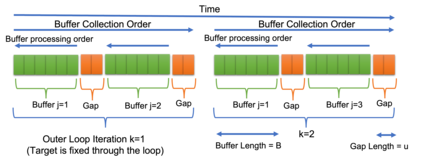
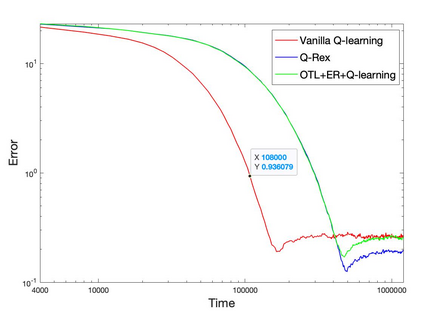
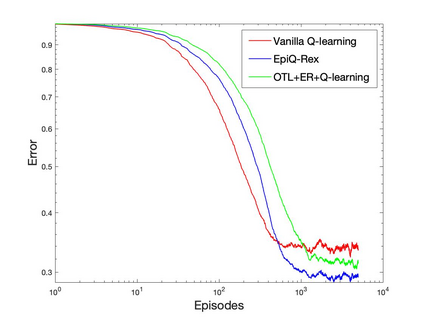
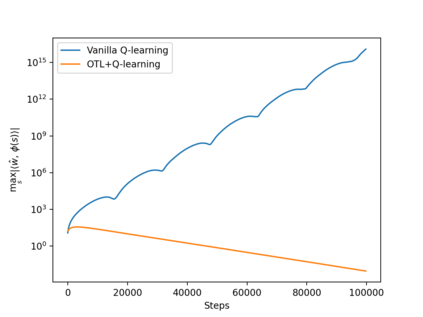
Q-learning is a popular Reinforcement Learning (RL) algorithm which is widely used in practice with function approximation (Mnih et al., 2015). In contrast, existing theoretical results are pessimistic about Q-learning. For example, (Baird, 1995) shows that Q-learning does not converge even with linear function approximation for linear MDPs. Furthermore, even for tabular MDPs with synchronous updates, Q-learning was shown to have sub-optimal sample complexity (Li et al., 2021;Azar et al., 2013). The goal of this work is to bridge the gap between practical success of Q-learning and the relatively pessimistic theoretical results. The starting point of our work is the observation that in practice, Q-learning is used with two important modifications: (i) training with two networks, called online network and target network simultaneously (online target learning, or OTL) , and (ii) experience replay (ER) (Mnih et al., 2015). While they have been observed to play a significant role in the practical success of Q-learning, a thorough theoretical understanding of how these two modifications improve the convergence behavior of Q-learning has been missing in literature. By carefully combining Q-learning with OTL and reverse experience replay (RER) (a form of experience replay), we present novel methods Q-Rex and Q-RexDaRe (Q-Rex + data reuse). We show that Q-Rex efficiently finds the optimal policy for linear MDPs (or more generally for MDPs with zero inherent Bellman error with linear approximation (ZIBEL)) and provide non-asymptotic bounds on sample complexity -- the first such result for a Q-learning method for this class of MDPs under standard assumptions. Furthermore, we demonstrate that Q-RexDaRe in fact achieves near optimal sample complexity in the tabular setting, improving upon the existing results for vanilla Q-learning.
翻译:Q- 学习是一种大众强化学习(RL) 算法, 在实践中广泛使用, 功能近似( Mnih 等人, 2015年) 。 相比之下, 现有的理论结果对Q- 学习是悲观的。 例如( Baird,1995年) 显示, Q- 学习甚至与线性 MDP 线性函数近似不相趋。 此外, 即使是表格式的 MDP 和同步更新, Q- 学习也显示具有亚最佳样本复杂性( Li 等人, 2021年; Azar 等人,2013年)。 这项工作的目的是弥合Q- 学习的内在复杂性学习和相对悲观的理论结果之间的差距。 我们工作的出发点是,在实践中, Q- 学习与线性网络同时使用, 称为在线网络和目标网络( 在线目标学习, 或 OTL), 和 (二) 经验重现 (ER) (Mnih 等人, 2015年) 发现, 在实时- R- Q- Q- 的不断学习方法中, 显示我们不断学习的理论- R- 学习结果如何在不断学习中, 学习中, 更进一步。