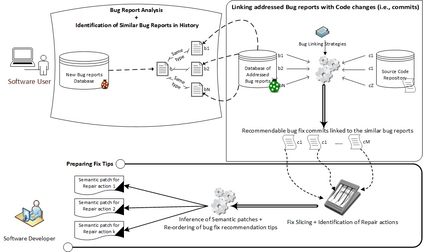
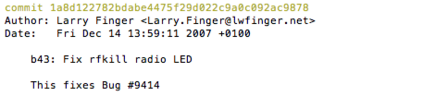
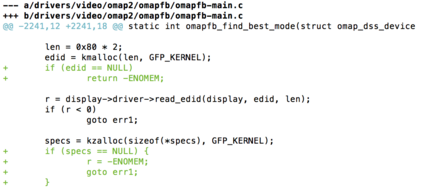
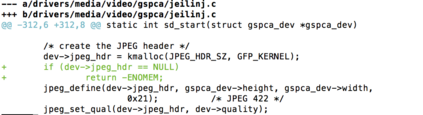
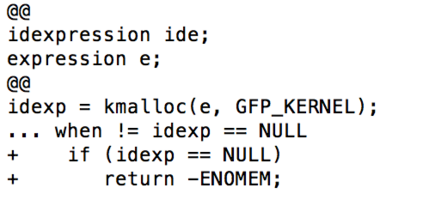
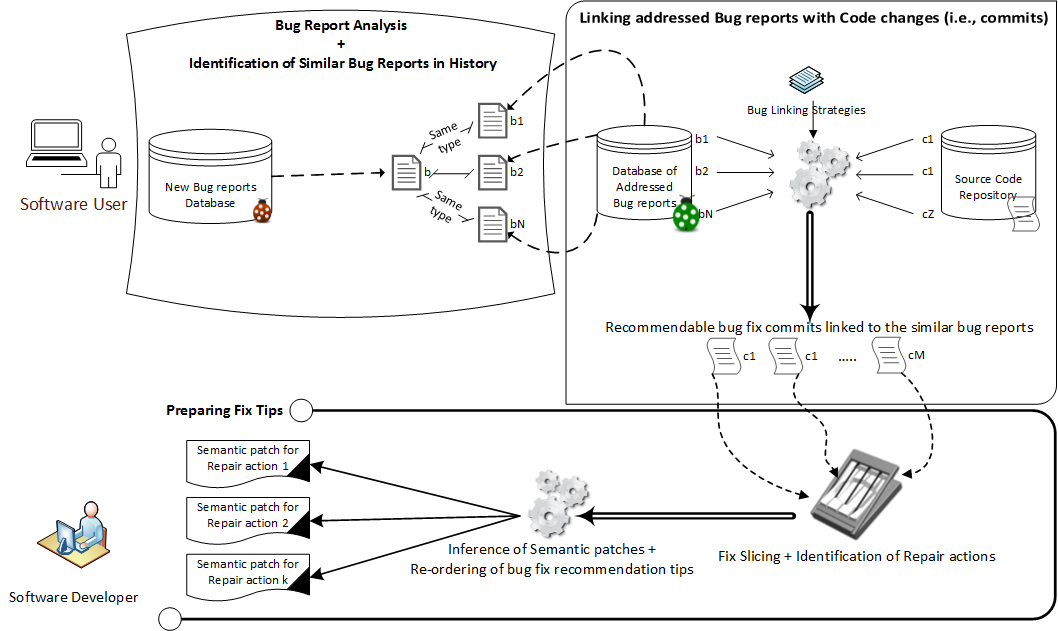
In software development, fixing bugs is an important task that is time consuming and cost-sensitive. While many approaches have been proposed to automatically detect and patch software code, the strategies are limited to a set of identified bugs that were thoroughly studied to define their properties. They thus manage to cover a niche of faults such as infinite loops. We build on the assumption that bugs, and the associated user bug reports, are repetitive and propose a new approach of fix recommendations based on the history of bugs and their associated fixes. In our approach, once a bug is reported, it is automatically compared to all previously fixed bugs using information retrieval techniques and machine learning classification. Based on this comparison, we recommend top-{\em k} fix actions, identified from past fix examples, that may be suitable as hints for software developers to address the new bug.
翻译:在软件开发中,修补错误是一项耗时且成本敏感的重要任务。 虽然提出了许多自动检测和修补软件代码的方法, 但这些策略仅限于一组经过彻底研究以定义其属性的已查明的错误。 因此, 它们能够覆盖诸如无限循环等的缺陷。 我们基于这样的假设, 即错误和相关用户错误报告是重复性的, 并基于错误历史及其相关修正, 提出了新的修补建议 。 在我们的处理方法中, 一旦报告错误, 就会使用信息检索技术和机器学习分类, 自动将它与所有先前固定的错误进行比较 。 基于此比较, 我们建议从以往的修补示例中找出的顶级 ~ em k} 修正动作, 可能适合作为软件开发者处理新错误的提示 。