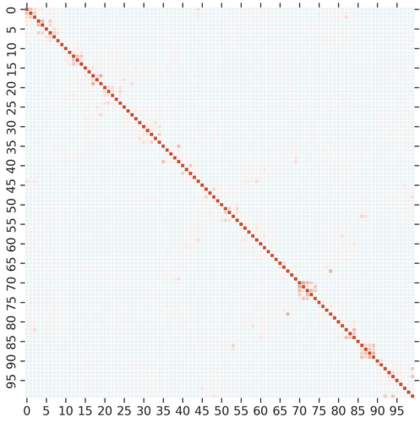
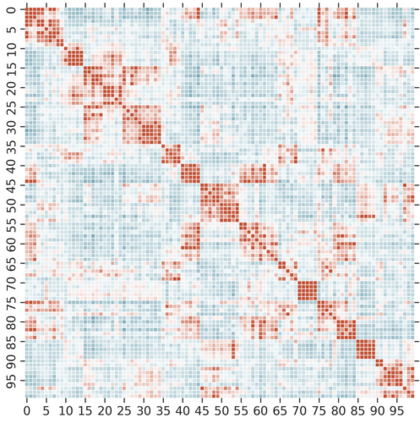
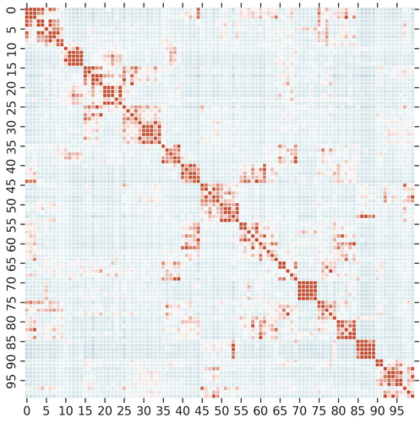
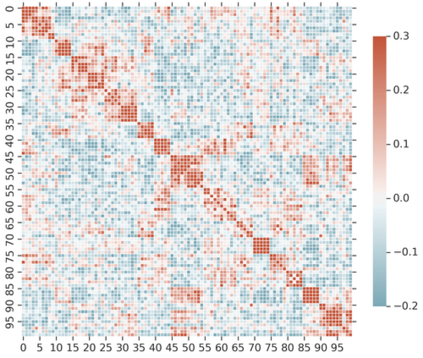
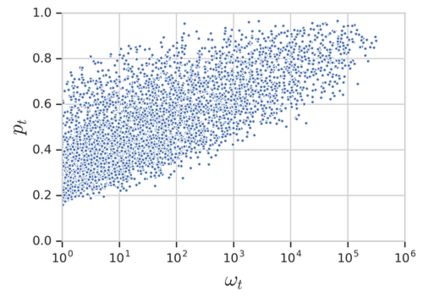
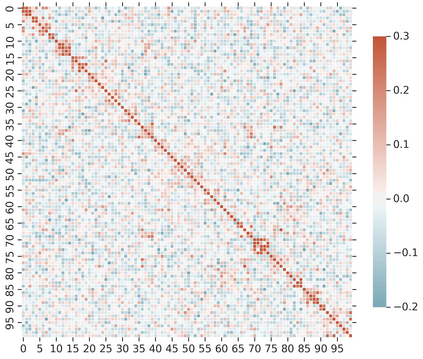
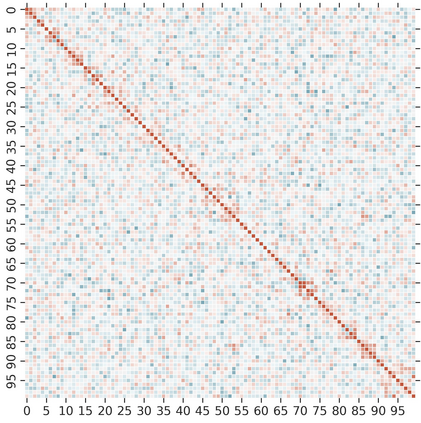
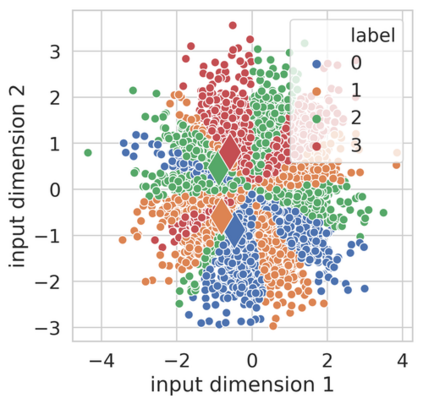
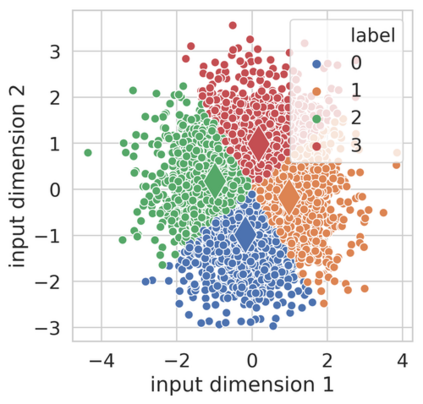
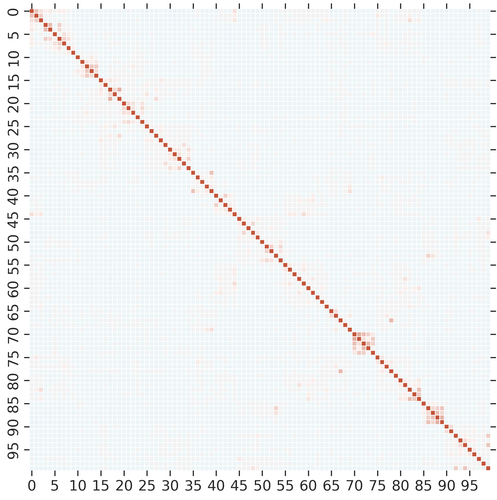
Knowledge Distillation (KD) is a model-agnostic technique to improve model quality while having a fixed capacity budget. It is a commonly used technique for model compression, where a larger capacity teacher model with better quality is used to train a more compact student model with better inference efficiency. Through distillation, one hopes to benefit from student's compactness, without sacrificing too much on model quality. Despite the large success of knowledge distillation, better understanding of how it benefits student model's training dynamics remains under-explored. In this paper, we categorize teacher's knowledge into three hierarchical levels and study its effects on knowledge distillation: (1) knowledge of the `universe', where KD brings a regularization effect through label smoothing; (2) domain knowledge, where teacher injects class relationships prior to student's logit layer geometry; and (3) instance specific knowledge, where teacher rescales student model's per-instance gradients based on its measurement on the event difficulty. Using systematic analyses and extensive empirical studies on both synthetic and real-world datasets, we confirm that the aforementioned three factors play a major role in knowledge distillation. Furthermore, based on our findings, we diagnose some of the failure cases of applying KD from recent studies.
翻译:知识蒸馏(KD)是一种在固定能力预算的情况下改进模型质量的模型-不可知技术,是一种用于改进模型质量的模型压缩的常用技术,一种质量更高的更大型能力教师模型用于培训更紧凑的学生模型,提高推断效率。通过蒸馏,人们希望从学生的紧凑性中获益,而不会在模型质量上牺牲太多。尽管知识蒸馏取得了很大成功,但更好地了解它如何有益于学生模型的培训动态仍然没有得到充分利用。在本文中,我们将教师的知识分为三个等级层次,并研究其对知识蒸馏的影响:(1) 关于“单向”的知识,即KD通过标签的平滑带来正规化效果;(2) 域知识,通过蒸馏,人们希望从学生的逻辑层地理测量法之前的教师的输入班关系中受益;(3) 具体知识,教师根据对事件难度的测量,重新测定学生模型的人均梯度。我们利用对合成和现实世界数据集的系统分析和广泛经验研究,我们确认上述三个因素在研究中产生了一种主要的缺陷。