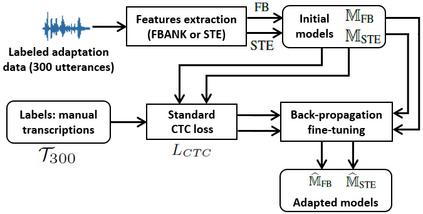
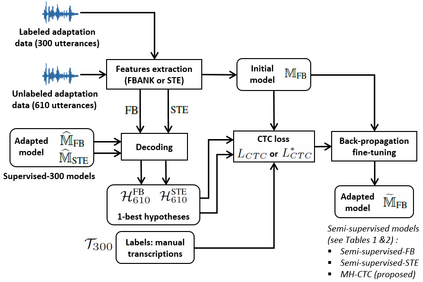
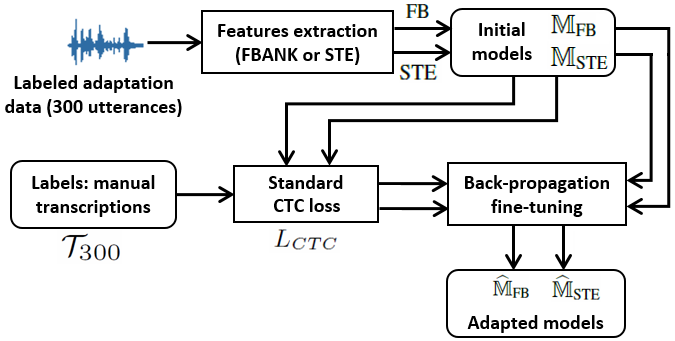
This paper proposes an adaptation method for end-to-end speech recognition. In this method, multiple automatic speech recognition (ASR) 1-best hypotheses are integrated in the computation of the connectionist temporal classification (CTC) loss function. The integration of multiple ASR hypotheses helps alleviating the impact of errors in the ASR hypotheses to the computation of the CTC loss when ASR hypotheses are used. When being applied in semi-supervised adaptation scenarios where part of the adaptation data do not have labels, the CTC loss of the proposed method is computed from different ASR 1-best hypotheses obtained by decoding the unlabeled adaptation data. Experiments are performed in clean and multi-condition training scenarios where the CTC-based end-to-end ASR systems are trained on Wall Street Journal (WSJ) clean training data and CHiME-4 multi-condition training data, respectively, and tested on Aurora-4 test data. The proposed adaptation method yields 6.6% and 5.8% relative word error rate (WER) reductions in clean and multi-condition training scenarios, respectively, compared to a baseline system which is adapted with part of the adaptation data having manual transcriptions using back-propagation fine-tuning.
翻译:本文建议了终端到终端语音识别的适应方法。在这个方法中,在计算连接器时间分类损失功能时,将多个自动语音识别(ASR)1最佳假设纳入计算中。将多个ASR假设结合在一起有助于减轻ASR假设错误的影响,在使用ASR假设时,计算CTC损失。当应用在半监督的适应假设情景中,部分适应数据没有标签时,拟议方法的CTC损失从解码无标签适应数据获得的不同ASR 1最佳假设中计算。实验是在清洁和多条件的培训情景中进行的,在这种情景中,基于CTCS的终端到终端 ASR系统分别接受了《华尔街日报》清洁培训数据和CHiME-4多条件培训数据的培训,并在Aurora-4测试数据中进行了测试。拟议的适应方法在清洁和多条件培训情景中分别实现了6.6%和5.8%相对字错误率的下降。实验是在清洁和多条件培训情景中进行的。实验是在清洁和多条件培训假设中进行,在清洁和多条件培训情景中进行试验,而基准系统则经过调整后调整后调整,对适应数据进行了部分调整。