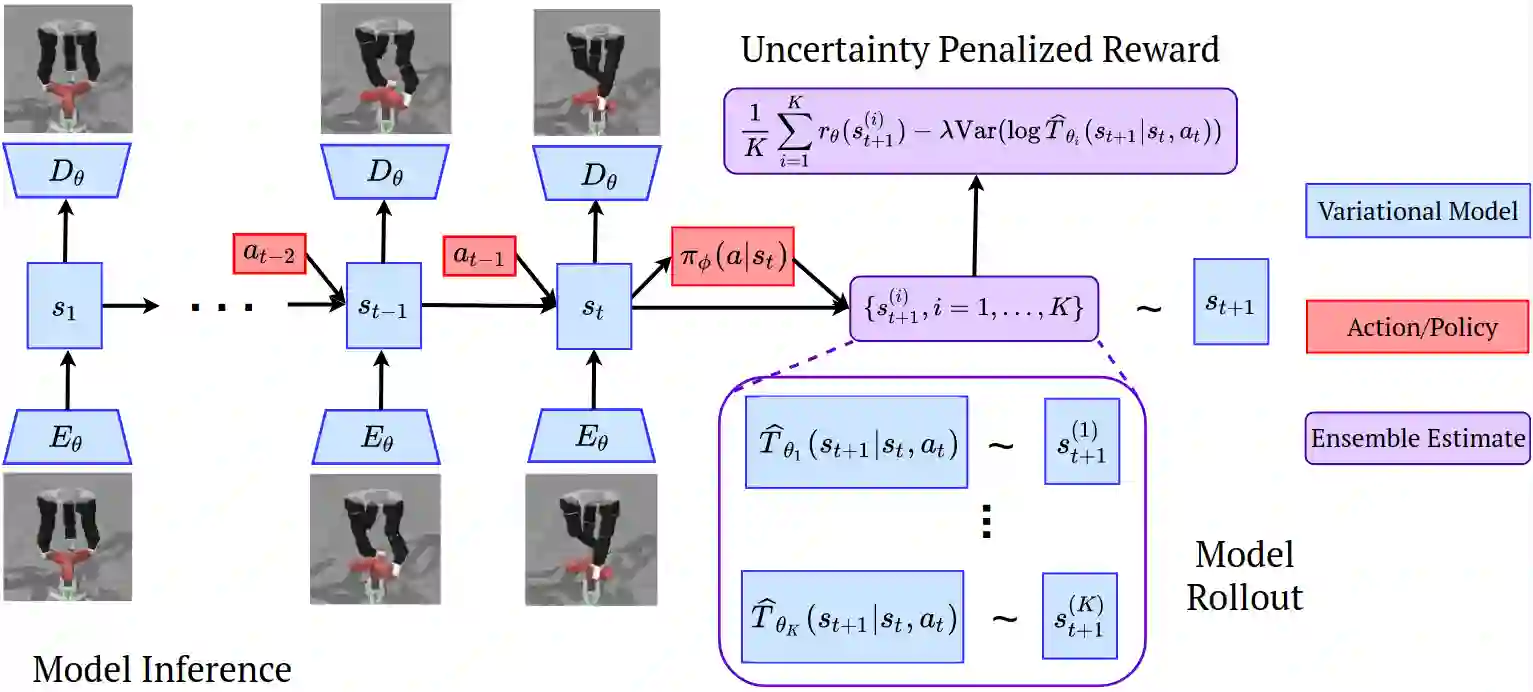
Offline reinforcement learning (RL) refers to the problem of learning policies from a static dataset of environment interactions. Offline RL enables extensive use and re-use of historical datasets, while also alleviating safety concerns associated with online exploration, thereby expanding the real-world applicability of RL. Most prior work in offline RL has focused on tasks with compact state representations. However, the ability to learn directly from rich observation spaces like images is critical for real-world applications such as robotics. In this work, we build on recent advances in model-based algorithms for offline RL, and extend them to high-dimensional visual observation spaces. Model-based offline RL algorithms have achieved state of the art results in state based tasks and have strong theoretical guarantees. However, they rely crucially on the ability to quantify uncertainty in the model predictions, which is particularly challenging with image observations. To overcome this challenge, we propose to learn a latent-state dynamics model, and represent the uncertainty in the latent space. Our approach is both tractable in practice and corresponds to maximizing a lower bound of the ELBO in the unknown POMDP. In experiments on a range of challenging image-based locomotion and manipulation tasks, we find that our algorithm significantly outperforms previous offline model-free RL methods as well as state-of-the-art online visual model-based RL methods. Moreover, we also find that our approach excels on an image-based drawer closing task on a real robot using a pre-existing dataset. All results including videos can be found online at https://sites.google.com/view/lompo/ .
翻译:离线强化学习(RL)是指从环境互动的静态数据集中学习政策的问题。离线RL能够广泛使用和重新使用历史数据集,同时减轻与在线探索相关的安全关切,从而扩大RL的实际可适用性。离线RL以前的大部分工作都侧重于通过压缩状态表示方式完成的任务。然而,从丰富的观测空间直接学习像图像这样的图像的能力对于机器人等真实世界应用至关重要。在这项工作中,我们利用基于模型的离线RL的越轨算法的最新进展,并将其推广到高水平的视觉观察空间。基于模型的离线 RL的离线运行算法在基于状态的任务中实现了艺术结果的状态,并具有很强的理论保障。然而,他们极其依赖模型预测中的不确定性量化能力,这在图像观察中尤其具有挑战性。为了克服这一挑战,我们提议学习一种潜伏状态动态模型,并代表着潜伏空间的模型中的不确定性。我们的方法在实践中既可以定位,也与在高水平视觉观察空间的ELOVO上最大限度地锁定一个较低的链。在未知的POMDP的在线图像操作上,在前的实验室上也发现了一种具有挑战性的图像操作方法。在前的实验室上找到一种具有挑战性的方法,在前的模型上,在前的模型上找到一种具有挑战性的方法,在前的模型-ROMPOL-L的模型的模型上,在前的模型-R-R-L的模型-RML的模型-A-A-L的实验中找到一种具有挑战性的方法。