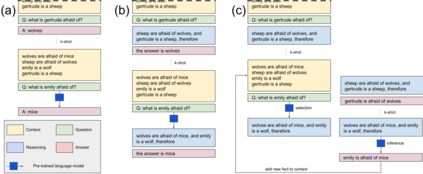
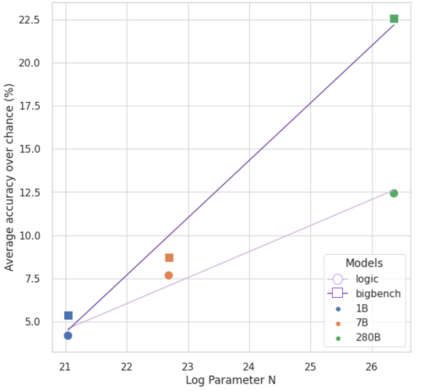
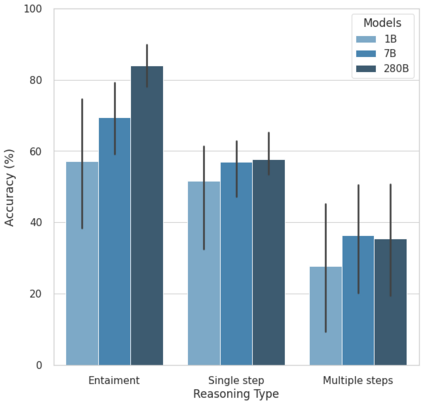
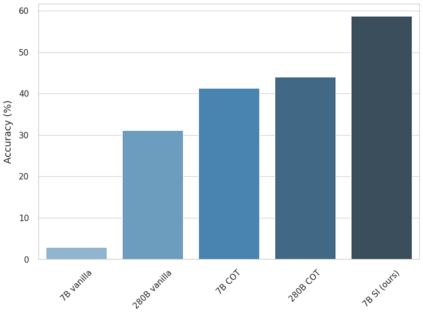
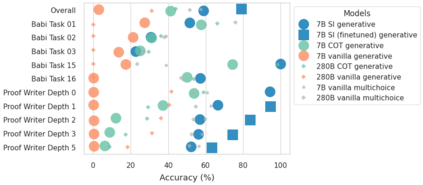
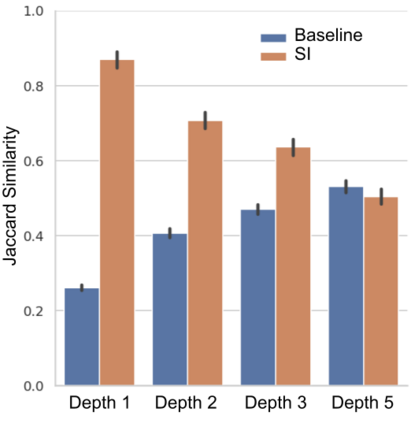
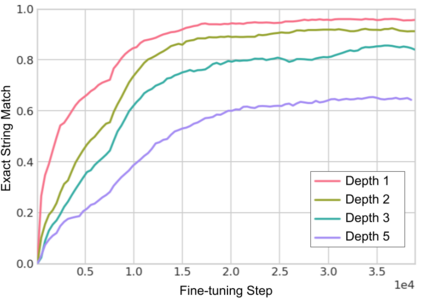
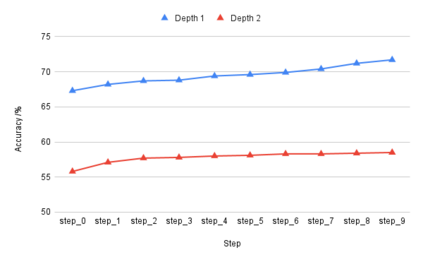
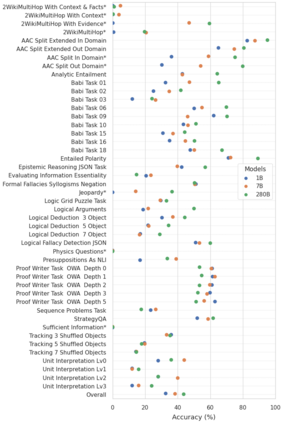
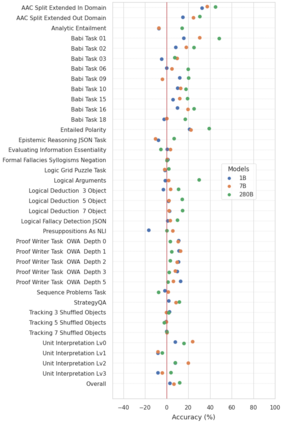
Large language models (LLMs) have been shown to be capable of impressive few-shot generalisation to new tasks. However, they still tend to perform poorly on multi-step logical reasoning problems. Here we carry out a comprehensive evaluation of LLMs on 50 tasks that probe different aspects of logical reasoning. We show that language models tend to perform fairly well at single step inference or entailment tasks, but struggle to chain together multiple reasoning steps to solve more complex problems. In light of this, we propose a Selection-Inference (SI) framework that exploits pre-trained LLMs as general processing modules, and alternates between selection and inference to generate a series of interpretable, casual reasoning steps leading to the final answer. We show that a 7B parameter LLM used within the SI framework in a 5-shot generalisation setting, with no fine-tuning, yields a performance improvement of over 100% compared to an equivalent vanilla baseline on a suite of 10 logical reasoning tasks. The same model in the same setting even outperforms a significantly larger 280B parameter baseline on the same suite of tasks. Moreover, answers produced by the SI framework are accompanied by a causal natural-language-based reasoning trace, which has important implications for the safety and trustworthiness of the system.
翻译:大型语言模型(LLMS)被证明能够给新任务带来令人印象深刻的微小概括,然而,在多步逻辑推理问题上,它们往往表现不佳。我们在这里对调查逻辑推理不同方面的50项任务中的LLMS进行全面评估。我们表明,语言模型往往在单步推论或必然任务中表现相当好,但努力将多种推理步骤连在一起,以解决更复杂的问题。有鉴于此,我们提议一个选择-推理框架,将预先培训的LLMS作为一般处理模块,在选择和推断之间进行替代,以产生一系列可解释的、随意推理步骤,从而导致最后答案。我们显示,在SI框架中使用的7B参数LM(LM)在五点概括的概括环境中使用,没有微调,其性能提高100%以上,而10套逻辑推理任务的范拉基线则相当。同样的模型甚至超越了同一套任务上一个大得多的280B参数基线。此外,由SI框架提出的答复带有重要的、基于自然语言推理的可靠程度。